
云原生数据仓库AnalyticDB PostgreSQL有几个任务sql 要十几分钟,但是内存使用并不高,这是为什么?我们的数据源是flink 流,一直在写入,我们连接池限制的是200个。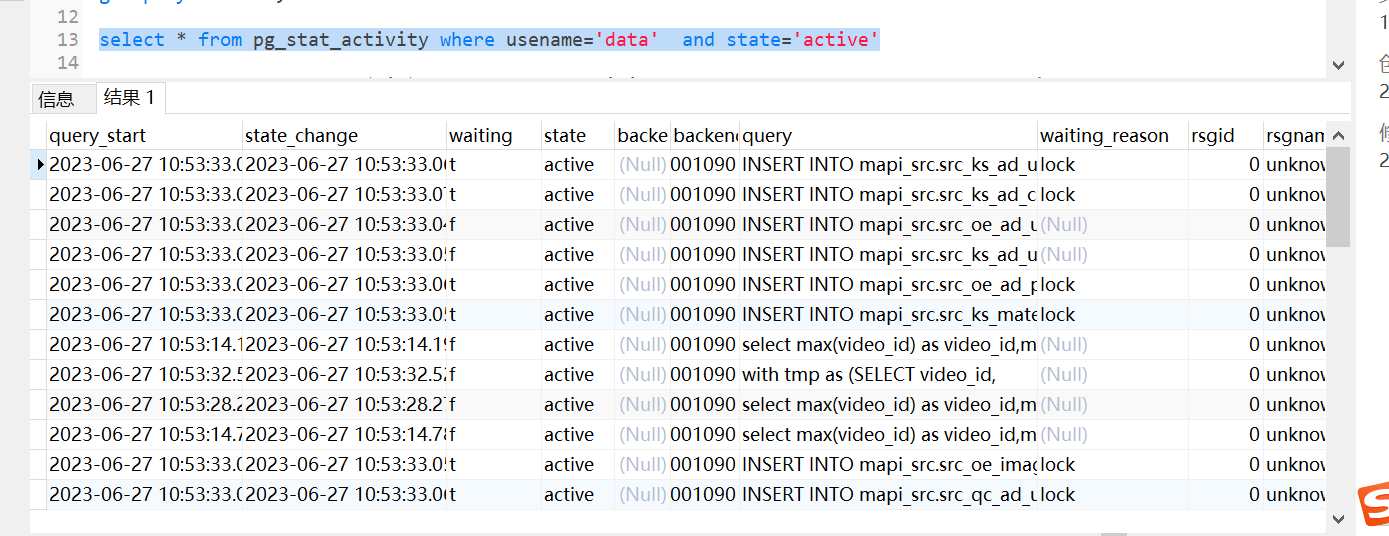
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
有几个可能的原因导致云原生数据仓库 AnalyticDB PostgreSQL 中的任务需要十几分钟的执行时间:
数据量较大:如果任务涉及处理大量的数据,例如大批量的写入、更新或复杂的查询操作,那么执行时间会相应增加。数据量的大小直接影响了任务的处理时间。
复杂的查询逻辑:某些任务可能包含复杂的查询逻辑,例如连接多个表、多重嵌套查询、使用聚合、排序等操作。这些复杂查询可能需要更长的时间来执行。
硬件资源限制:如果硬件资源(例如CPU、内存、磁盘IO)不足,可能会导致任务执行速度变慢。当系统负载较高并且资源竞争激烈时,任务的执行时间可能会延长。
索引缺失或过期:如果任务涉及到查询操作,而相关的索引缺失或者过期,数据库需要进行全表扫描来满足查询条件,这将导致任务的执行时间延长。
锁冲突:在并发环境下,如果多个任务之间存在锁冲突,会导致任务的等待时间增加,从而延长任务的执行时间。
要解决任务执行时间过长的问题,您可以考虑以下步骤:
优化查询:检查任务中的查询语句,确保它们被正确地编写并合理利用索引。尽量避免复杂查询逻辑和不必要的计算。
调整硬件资源:评估系统的硬件配置,确保有足够的计算资源、内存和磁盘IO能力来支持任务的执行。如果需要,可以考虑增加硬件资源。
索引优化:分析任务中经常使用的查询条件,并创建相应的索引来提高查询性能。
并发控制:通过合理的事务管理和锁机制,减少锁冲突和资源竞争,从而缩短任务的等待时间。
数据分区与分片:如果数据量较大,可以考虑对数据进行分区或分片,以减少单个任务需要处理的数据量,从而提高任务的执行效率。
以下是一些可能的原因:
数据量过大:如果要处理的数据量非常大,SQL 任务的执行时间可能会较长。在这种情况下,可以考虑优化 SQL 查询语句,例如使用索引来加速查询,或者对大表进行分区或分片来减少查询范围。
查询语句复杂:如果 SQL 查询语句过于复杂,例如包含大量的子查询或连接操作,也可能会导致任务执行时间较长。在这种情况下,可以考虑简化查询语句或者对复杂查询进行优化。
数据库连接池限制:如果连接池限制过低,可能会导致任务等待连接池中的连接,从而影响任务的执行效率。在这种情况下,可以考虑增加连接池大小,或者优化连接池的使用方式。
数据库资源限制:如果数据库的计算或存储资源不足,可能会导致任务执行缓慢。在这种情况下,可以考虑增加数据库的计算或存储资源,或者优化数据库的配置参数。
这里读任务和写任务总个数是被resource queue限制的,查询慢内存不高,应该是大部分任务被写任务把连接占用了,读任务需要等待排队导致的。此回答整理自钉群“云原生数据仓库AnalyticDB PostgreSQL版交流群”
阿里云自主研发的云原生数据仓库,具有高并发读写、低峰谷读写、弹性扩展、安全可靠等特性,可支持PB级别数据存储,可广泛应用于BI、机器学习、实时分析、数据挖掘等场景。包含AnalyticDB MySQL版、AnalyticDB PostgreSQL 版。


