
请教一下 Flink这个为什么没有自动清理 越来越多?
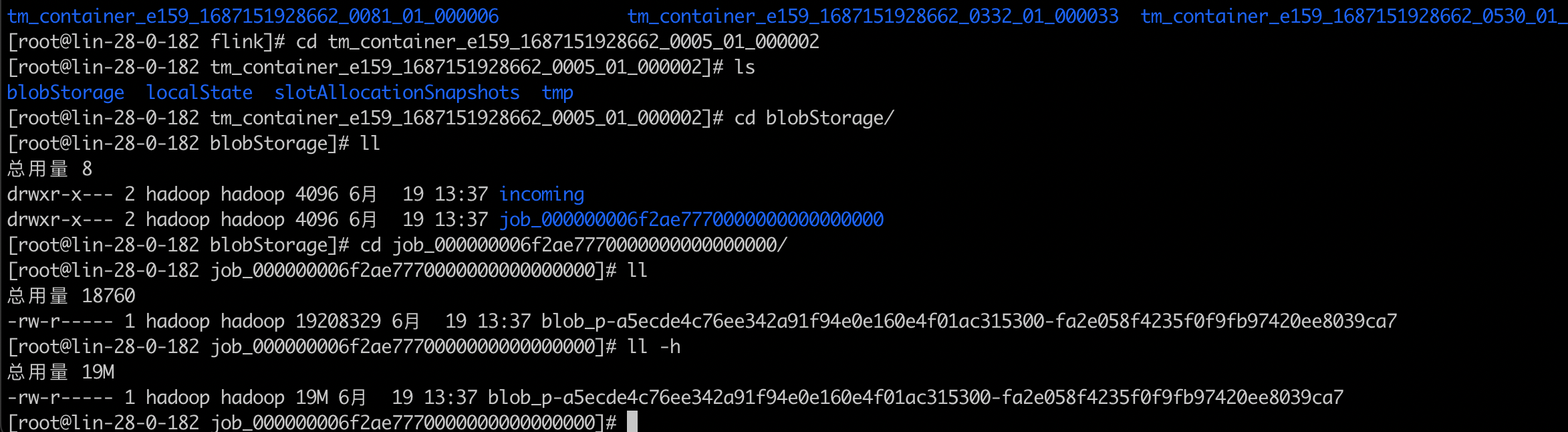 里面的文件19M
里面的文件19M
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
Checkpoint 目录中生成了大量的 Checkpoint 数据,而这些数据没有被自动清理,导致 Checkpoint 目录越来越大。在 Flink 中,Checkpoint 是一种保证数据一致性和故障恢复的机制,会自动定期生成 Checkpoint 数据以备份数据并支持故障恢复。当然,如果不对 Checkpoint 数据进行清理和管理,会导致 Checkpoint 目录越来越大,最终可能会导致磁盘空间耗尽。
为了解决这个问题,可以尝试以下几个方法:
手动清理 Checkpoint 目录:可以手动删除不需要的 Checkpoint 数据,以释放磁盘空间。通常情况下,可以删除旧的 Checkpoint 数据,保留最近的几个 Checkpoint 数据,例如最近 3-5 个 Checkpoint 数据。
调整 Checkpoint 配置:可以通过调整 Flink 的 Checkpoint 配置,来控制 Checkpoint 数据的生成和清理。例如,可以调整 Checkpoint 的生成周期、最大保留时间和最大保留数量等参数,以满足实际需求。
使用外部存储:可以将 Checkpoint 存储到外部存储中,例如 HDFS 或者 S3 等分布式文件系统,以避免 Checkpoint 目录越来越大的问题。在使用外部存储时,需要注意配置和管理存储容量和存储策略,以避免存储空间不足或者过期数据无法清理的问题。
Flink 在默认情况下会自动清理过期的状态数据和检查点(checkpoints),以避免无限制地占用磁盘空间。然而,如果你发现 Flink 中的文件越来越多,并且没有被自动清理,可能存在以下几种情况:
1. 配置错误:请确保 Flink 的配置文件中指定了正确的状态后端(state backend)和检查点目录。在 flink-conf.yaml 文件中,该配置通常是 state.backend.fs.checkpointdir 或 state.savepoints.dir。
2. 没有启用自动清理:在 Flink 中,自动清理通常通过定时任务进行。请确认你的 Flink 作业是否处于运行状态,并已经设置了适当的清理策略和时间间隔。可以通过设置 state.cleanup.interval 属性来配置清理任务的频率。
3. 清理策略问题:Flink 支持多种清理策略,如基于时间或基于大小的清理策略。你可以根据实际需求选择适合的策略并进行配置。例如,可以使用 state.cleanup.interval 属性来指定清理任务的触发频率,并使用 state.cleanup.mode 属性来选择清理模式。具体的配置参数取决于你所使用的状态后端和清理策略。
4. 系统资源限制:自动清理操作需要一定的系统资源(CPU、内存和磁盘),以及足够的时间来执行。如果系统资源耗尽或负载过高,可能会导致清理任务无法按计划运行。请确保你的系统具有足够的资源,并根据实际情况进行调整。
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。


