
dataworks导入的具体操作步骤是什么?
dataworks导入的具体操作步骤是什么?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
-
北京阿里云ACE会长
在DataWorks中,导入数据通常需要以下步骤:
创建数据源:在DataWorks控制台中,选择“数据开发”>“数据源”,然后单击“新建数据源”按钮,按照提示填写数据源的相关信息(例如类型、名称、描述、连接信息等)。
创建表:在DataWorks控制台中,选择“数据开发”>“数据开发空间”,然后单击“新建表”按钮,按照提示填写表的相关信息(例如名称、描述、字段定义等)。
导入数据:在DataWorks控制台中,选择“数据集成”>“数据同步”,然后单击“新建同步任务”按钮,在创建同步任务页面中,选择源数据源和目标数据源,然后配置同步任务的详细信息(例如同步方式、同步表、同步字段、过滤条件等)。
预览和测试:在创建同步任务后,可以单击“预览”按钮来预览同步的数据结果,或单击“测试”按钮来测试同步任务的正确性和可用性。
2023-07-31 21:45:59赞同 1 展开评论 -
要导入数据到DataWorks,你可以按照以下步骤进行操作:
-
登录DataWorks控制台:打开浏览器,访问DataWorks的控制台网址,并使用有效的账号和密码登录。
-
创建项目:在DataWorks控制台上创建一个项目,用于组织和管理数据工作流以及相关资源。选择合适的地域、命名空间等选项,并设置项目的基本信息。
-
创建数据源:在项目中创建一个数据源,用于连接和访问需要导入的数据。选择合适的数据源类型(如RDS、MaxCompute等),并填写相应的连接信息,例如数据库地址、用户名、密码等。
-
创建表或数据集:根据需要,在项目中创建表或数据集,用于存储导入的数据。选择正确的存储位置和格式,并定义表结构(字段名称、类型等)。
-
创建数据集成节点:在数据工作流中创建一个数据集成节点,用于实现数据的导入操作。选择合适的数据源和目标表或数据集,并配置数据传输规则,如选择需要导入的数据范围、筛选条件等。
-
配置调度周期:根据需求,设置数据集成节点的调度周期,以确定数据导入的频率和时间。
-
调试和运行:在完成以上配置后,可以先进行调试,检查是否能够成功导入数据。如果一切正常,可以手动运行数据集成节点,或设置自动调度,使其按照预定的周期自动执行数据导入任务。
-
监控和管理:在DataWorks控制台上监控数据导入任务的执行情况,查看日志和报告,以便及时发现和解决问题。根据需要,进行后续的数据处理操作或分析工作。
请注意,以上步骤仅为一般性的操作流程,具体的导入步骤可能会因为使用的数据源、数据格式等而有所差异。建议参考DataWorks的官方文档或联系相关技术支持获取更详细和准确的操作指导。
2023-07-01 17:50:14赞同 展开评论 -
-
在迁移助手的左侧导航栏,单击DataWorks迁移 > DataWorks导入。在DataWorks导入页面,单击右上方的新建导入任务。在新建导入任务对话框中,配置各项参数。
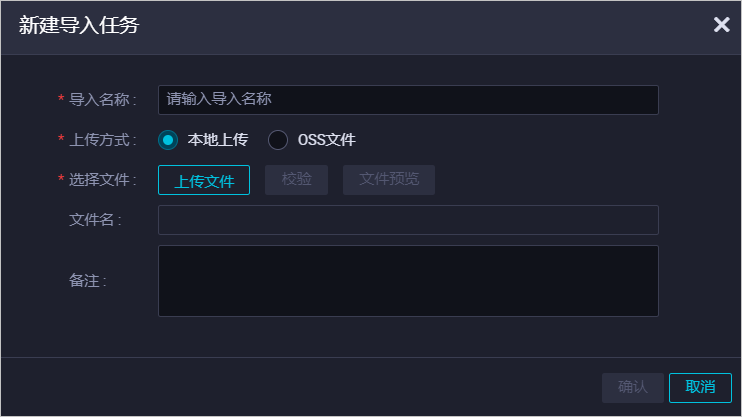 参数 描述 导入名称 导入名称仅支持大小写字母、中文、数字、下划线(_)和英文句号(.)。 上传方式 包括本地上传和OSS文件: 备注 对导入任务进行简单描述。单击确认,进入导入任务设置页面。导入任务前,您需要校检导入文件的格式和内容。通过校检后,才可以单击确认。配置导入任务。配置导入任务时,必须配置引擎实例映射(下图以MaxCompute计算引擎示例)。其它配置为可选操作,您可以根据业务需求设置。说明 如果是同租户、同地域下不同工作空间的互导,您只需要设置引擎实例映射。在引擎实例映射区域,
参数 描述 导入名称 导入名称仅支持大小写字母、中文、数字、下划线(_)和英文句号(.)。 上传方式 包括本地上传和OSS文件: 备注 对导入任务进行简单描述。单击确认,进入导入任务设置页面。导入任务前,您需要校检导入文件的格式和内容。通过校检后,才可以单击确认。配置导入任务。配置导入任务时,必须配置引擎实例映射(下图以MaxCompute计算引擎示例)。其它配置为可选操作,您可以根据业务需求设置。说明 如果是同租户、同地域下不同工作空间的互导,您只需要设置引擎实例映射。在引擎实例映射区域,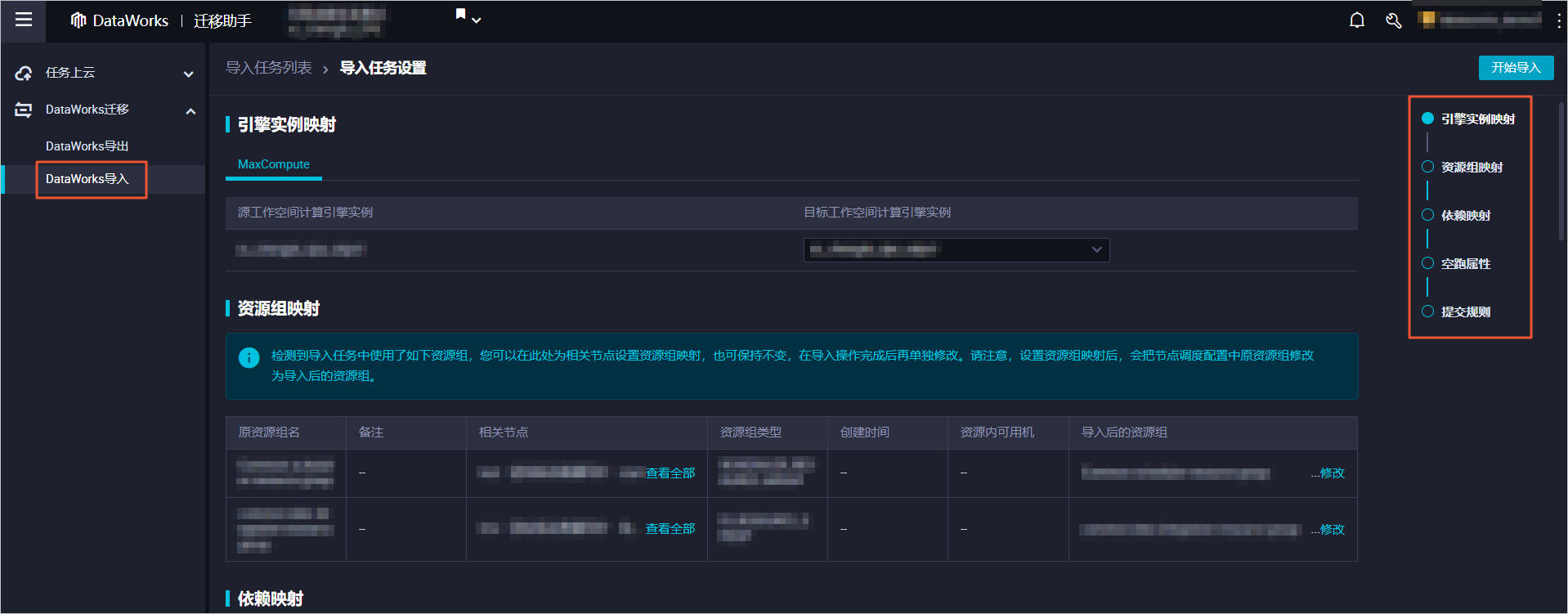 设置源工作空间和目标工作空间的计算引擎实例映射关系。目标工作空间计算引擎实例显示的是目标工作空间中计算引擎的显示名称,而不是计算引擎的项目名称。您可以参考进入工作空间配置,进入工作空间配置页面,在计算引擎信息区域,查看相应计算引擎的显示名称。如下示例为MaxCompute计算引擎的显示名称。如果源工作空间绑定多种类型的计算引擎,目标工作空间仅绑定一种类型的计算引擎,则目标工作空间无其它类型节点的创建权限,导致导入任务失败。可选:在资源组映射区域,修改源工作空间和目标工作空间的资源组映射关系,避免出现运行任务时无法找到资源组的情况。
设置源工作空间和目标工作空间的计算引擎实例映射关系。目标工作空间计算引擎实例显示的是目标工作空间中计算引擎的显示名称,而不是计算引擎的项目名称。您可以参考进入工作空间配置,进入工作空间配置页面,在计算引擎信息区域,查看相应计算引擎的显示名称。如下示例为MaxCompute计算引擎的显示名称。如果源工作空间绑定多种类型的计算引擎,目标工作空间仅绑定一种类型的计算引擎,则目标工作空间无其它类型节点的创建权限,导致导入任务失败。可选:在资源组映射区域,修改源工作空间和目标工作空间的资源组映射关系,避免出现运行任务时无法找到资源组的情况。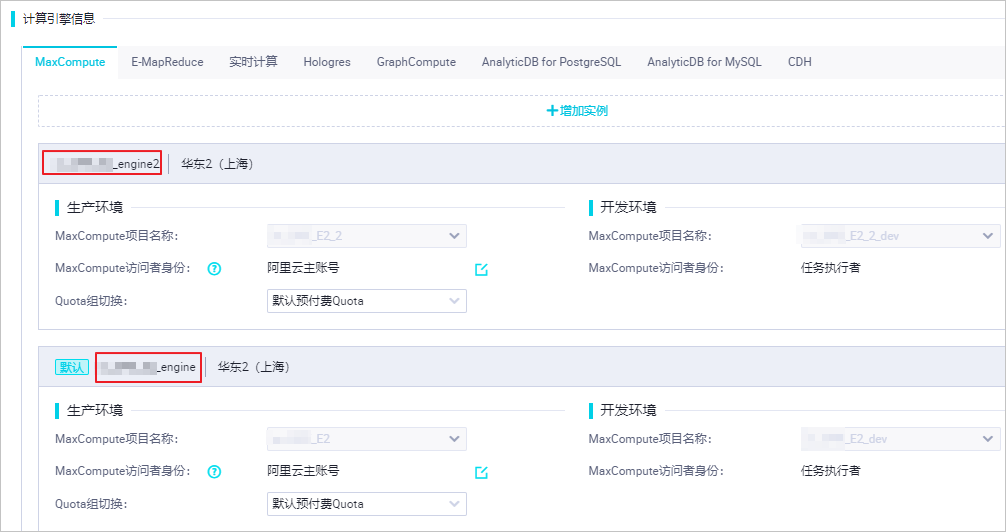 可选:在依赖映射区域,为相关节点设置项目映射。在导入任务时,有任务代码使用源工作空间名称。您可以修改新项目名,修改范围为任务代码、本节点输入名称和输出名称。待导入完成后,会快速替换为新的工作空间名称。可选:在空跑属性区域,单击相应节点后的设置空跑。您也可以选中多个需要空跑的节点,单击批量设 https://help.aliyun.com/document_detail/172914.html,此回答整理自钉群“DataWorks交流群(答疑@机器人)”2023-07-01 17:15:57赞同 展开评论
可选:在依赖映射区域,为相关节点设置项目映射。在导入任务时,有任务代码使用源工作空间名称。您可以修改新项目名,修改范围为任务代码、本节点输入名称和输出名称。待导入完成后,会快速替换为新的工作空间名称。可选:在空跑属性区域,单击相应节点后的设置空跑。您也可以选中多个需要空跑的节点,单击批量设 https://help.aliyun.com/document_detail/172914.html,此回答整理自钉群“DataWorks交流群(答疑@机器人)”2023-07-01 17:15:57赞同 展开评论


DataWorks基于MaxCompute/Hologres/EMR/CDP等大数据引擎,为数据仓库/数据湖/湖仓一体等解决方案提供统一的全链路大数据开发治理平台。