
请问modelscope中这个究竟怎么改?
问题1:请问modelscope中这个究竟怎么改?  我改成了这个multi_modal_embedding.py,该目录下有
我改成了这个multi_modal_embedding.py,该目录下有  ,这些文件数据预处理成了
,这些文件数据预处理成了  这种方式后报错这种方式,
这种方式后报错这种方式, 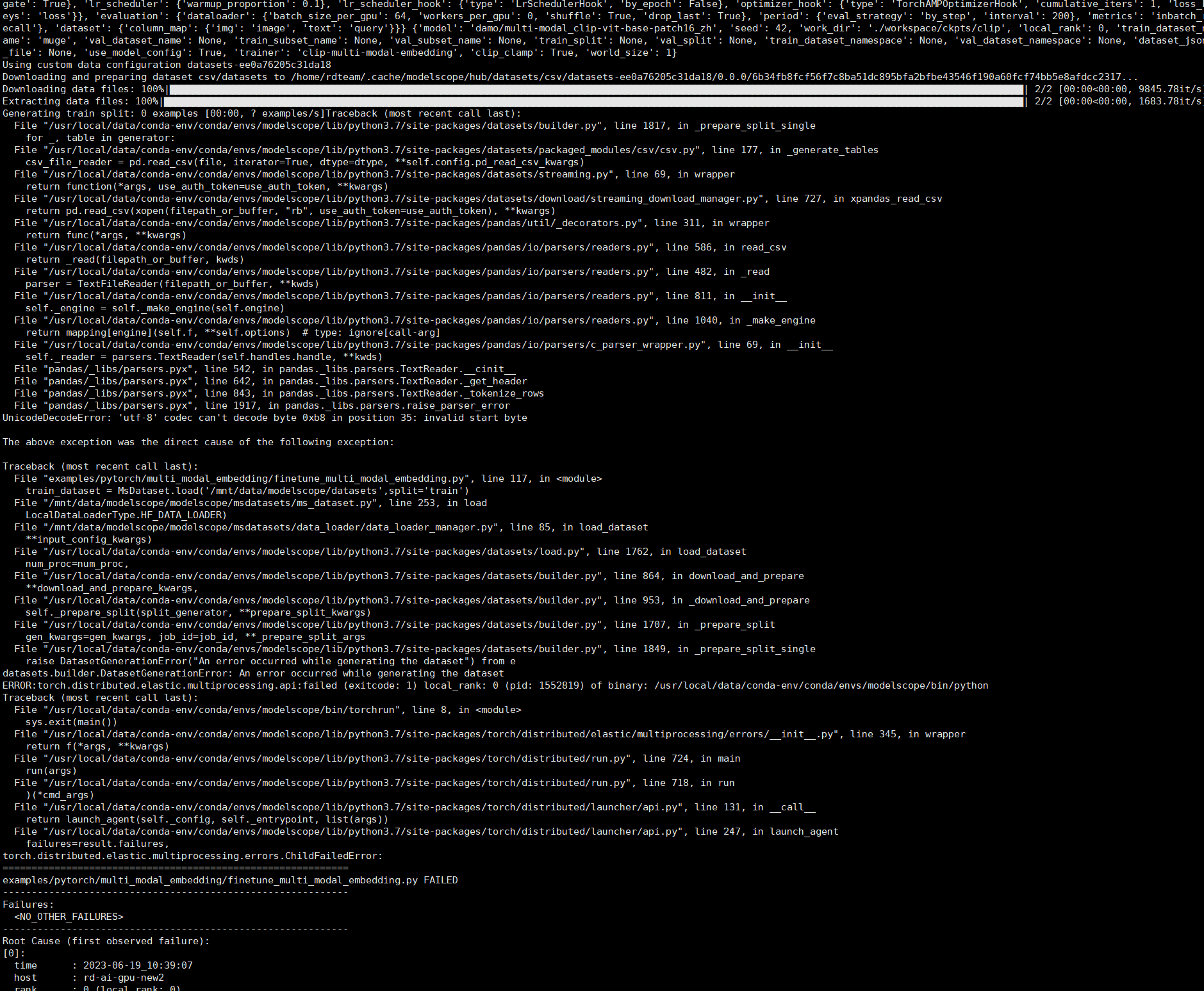 不是这样弄嘛?
不是这样弄嘛? 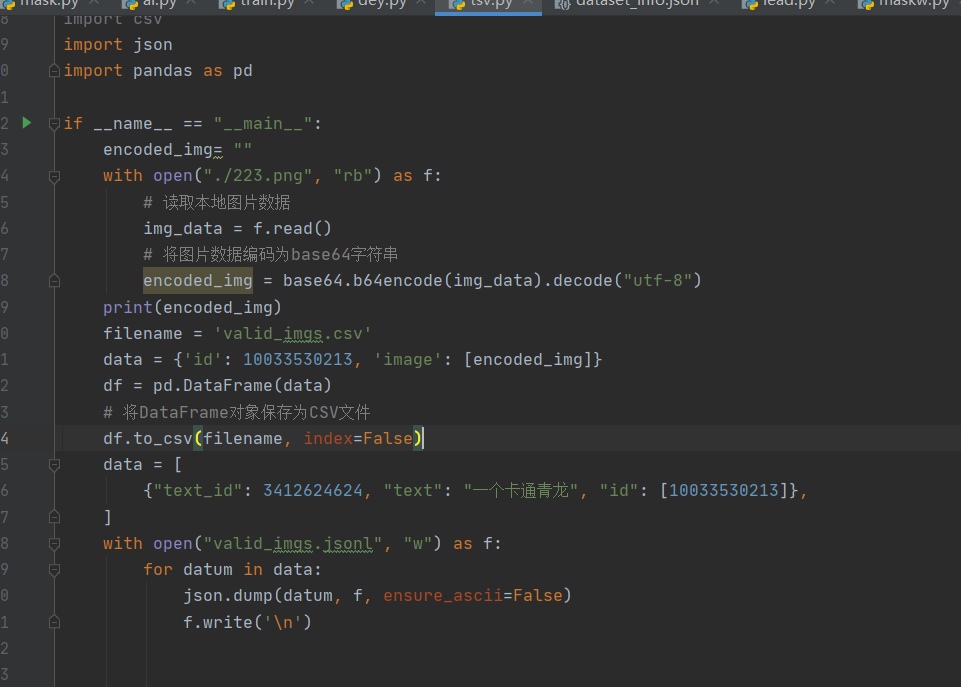 这是我的数据格式处理部分。 用这个例子可以跑,数据源啥都没有改目前我就是想换成自己的数据这个是数据整理,然后对这里面的代码,改成了自己整理的数据。读取数据是正常的 问题2:代码是这个数据预处理不是这样的嘛import base64import csvimport jsonimport pandas as pddef encode_image_to_base64(filename): with open(filename, "rb") as f: img_data = f.read() encoded_img = base64.b64encode(img_data).decode("utf-8") return encoded_imgif name == "main": image_filename = "../223.png" encoded_img = encode_image_to_base64(image_filename) data = {'id': 10033530213, 'image': [encoded_img]} df = pd.DataFrame(data) for name in ['train', 'valid']: csv_filename = f'{name}_imgs.csv' jsonl_filename = f'{name}_imgs.jsonl' df.to_csv(csv_filename, index=False) data = [ {"text_id": 3412624624, "text": "一个卡通青龙", "id": [10033530213]}, ] with open(jsonl_filename, "w") as f: for datum in data: json.dump(datum, f, ensure_ascii=False) f.write('\n')
这是我的数据格式处理部分。 用这个例子可以跑,数据源啥都没有改目前我就是想换成自己的数据这个是数据整理,然后对这里面的代码,改成了自己整理的数据。读取数据是正常的 问题2:代码是这个数据预处理不是这样的嘛import base64import csvimport jsonimport pandas as pddef encode_image_to_base64(filename): with open(filename, "rb") as f: img_data = f.read() encoded_img = base64.b64encode(img_data).decode("utf-8") return encoded_imgif name == "main": image_filename = "../223.png" encoded_img = encode_image_to_base64(image_filename) data = {'id': 10033530213, 'image': [encoded_img]} df = pd.DataFrame(data) for name in ['train', 'valid']: csv_filename = f'{name}_imgs.csv' jsonl_filename = f'{name}_imgs.jsonl' df.to_csv(csv_filename, index=False) data = [ {"text_id": 3412624624, "text": "一个卡通青龙", "id": [10033530213]}, ] with open(jsonl_filename, "w") as f: for datum in data: json.dump(datum, f, ensure_ascii=False) f.write('\n')
-
北京阿里云ACE会长
需要将 MsDataset.load 函数中的参数修改为自己的训练数据集和验证数据集名称,以及数据集所在的路径。
具体来说,需要将以下行中的参数修改为您自己的数据集名称和路径:
scheme
Copy
train_dataset = MsDataset.load('/mnt/data/modelscope/datasets', split='train')
eval_dataset = MsDataset.load('/mnt/data/modelscope/datasets', split='validation')
例如,如果您的训练数据集名称为 my_train_dataset,路径为 /path/to/my_train_dataset,验证数据集名称为 my_validation_dataset,路径为 /path/to/my_validation_dataset,则您需要将代码修改为:angelscript
Copy
train_dataset = MsDataset.load('my_train_dataset', namespace='modelscope', split='train')
eval_dataset = MsDataset.load('my_validation_dataset', namespace='modelscope', split='validation')train_dataset.makedirs(args.work_dir, exist_ok=True)
eval_dataset.makedirs(args.work_dir, exist_ok=True)
其中,makedirs 函数用于创建工作目录,并确保其存在。2023-07-18 15:30:15赞同 展开评论 -
意中人就是我呀!
"回答1:如果用github的code能够跑通,然后读出的数据和你修改后的数据是一样的话,不应该报错的。 现在看起来就是数据的编码有问题。 回答2:dataset的column name没有和muge对齐。 此回答整理自钉群“魔搭ModelScope开发者联盟群 ①”"
2023-06-28 13:37:46赞同 展开评论

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!欢迎加入技术交流群:微信公众号:魔搭ModelScope社区,钉钉群号:44837352