
问题一: 为什么在阿里语音AI中语音识别,自己录的语音不行,不能转成文字?文字生成的音频就能正常使用 采样率: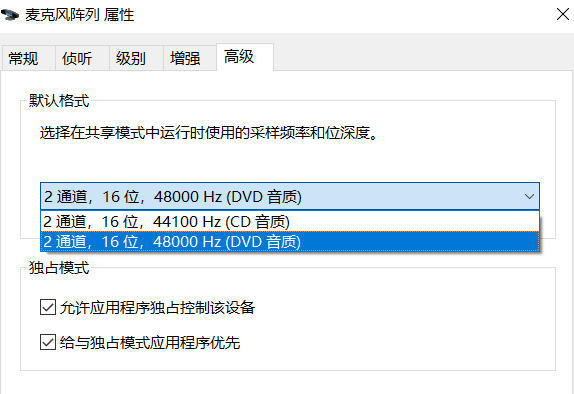 录制的音频返回的都是个“嗯” 问题二? 请问6k 8k这里是多少?
录制的音频返回的都是个“嗯” 问题二? 请问6k 8k这里是多少?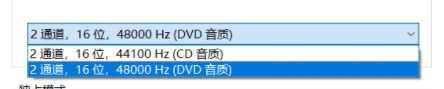 问题三:
问题三:  采样率转换多少才是8k? 问题四:
采样率转换多少才是8k? 问题四: 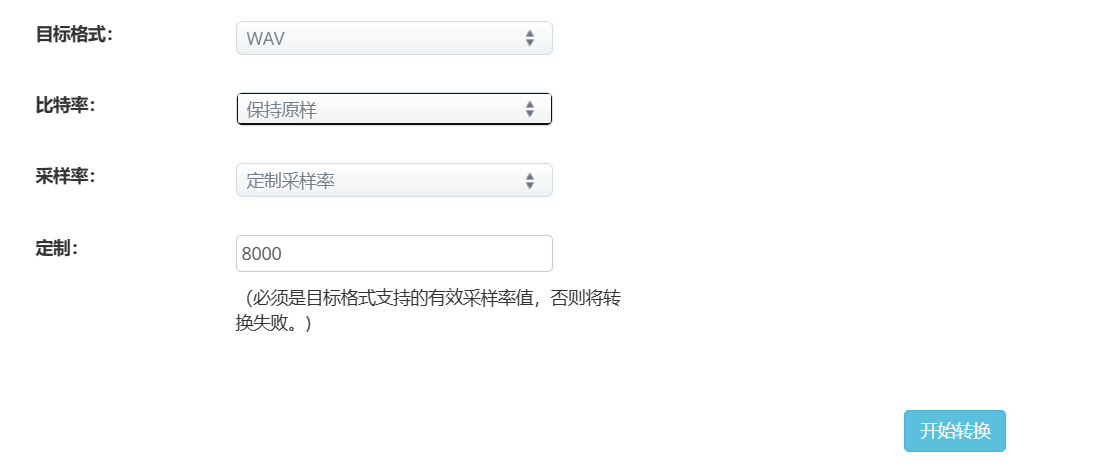 这样可以吗,还是比特率也要?不知道定制8000有没有效 问题五: 我不是第三方,我在和前端对接,用别人三方网页转换一下8k的录音能不能用 网上好像都没有8k音频呢?
这样可以吗,还是比特率也要?不知道定制8000有没有效 问题五: 我不是第三方,我在和前端对接,用别人三方网页转换一下8k的录音能不能用 网上好像都没有8k音频呢? 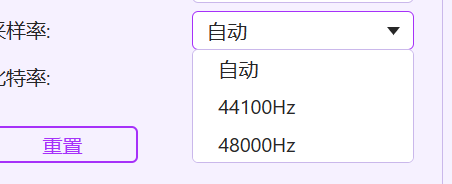 最多的是这种 问题六: 前端有8000 16000这个采样率,但是传过来的音频转换是个嗯是为什么?
最多的是这种 问题六: 前端有8000 16000这个采样率,但是传过来的音频转换是个嗯是为什么?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在语音识别过程中,有几个因素可能导致自己录制的语音无法转换为文字,而文字生成的音频则可以正常使用。以下是可能的原因:
语音质量差异:录制的语音可能受到背景噪音、干扰声、语速不匀等因素的影响,导致语音质量较差。这可能导致语音识别算法难以准确地识别和转换语音为文字。
语音录制条件:录制语音时的录音设备和录音环境可能不理想,可能存在麦克风质量低下、录音环境嘈杂、回声等问题。这些因素会影响语音的清晰度和准确性,从而影响语音识别结果。
语音识别模型:语音识别系统通常使用深度学习模型,这些模型需要大量的训练数据来识别不同的语音特征和语言模式。如果自己录制的语音与训练模型的数据不匹配,识别准确性可能会受到影响。
针对这些问题,可以尝试以下方法来提高自己录制的语音识别准确性:
改善录制条件:选择一个安静的环境,避免嘈杂的背景声音,并确保麦克风的质量良好。
清晰地发音:尽量清晰地发音,避免模糊或含糊不清的语音。适当地控制语速和语调,以便语音识别算法能够更好地捕捉语音特征。
使用专业设备:考虑使用专业的语音录制设备,如高质量的麦克风,以提高录制语音的质量。
选择适当的识别模型:如果有选择模型的选项,可以尝试不同的语音识别模型,找到最适合录制语音的模型。
请注意,语音识别的准确性不仅受录制语音的质量影响,还受到语音识别系统本身的性能和算法的影响。不同的语音识别服务提供商和技术平台可能会有不同的准确性和适应性。
针对问题一的回答: 我们只支持8和16k的采样率 针对问题二的回答: 8000 16000 针对问题三的回答: 您现在是48000 合成的时候 设置8000或者16000,48000这个需要改下。 针对问题四的回答: 采样率不能选择8000是不 其他的应该没事。 针对问题五的回答: 这个是前端默认的采样率把 一般是44,但是 我们的识别是需要是8000或者16000 针对问题六的回答: 需要转码 采样率不合适的话 会出嗯-此回答来自钉群“阿里语音AI【6群】”

