
问题1:OCR接口调试工具试了,传pdf链接会报错,传图片的链接不会报错。你们接口是没有更新上去吧?我换了个小的pdf文件(20k)就可以调用了,1.5m的pdf就会报错。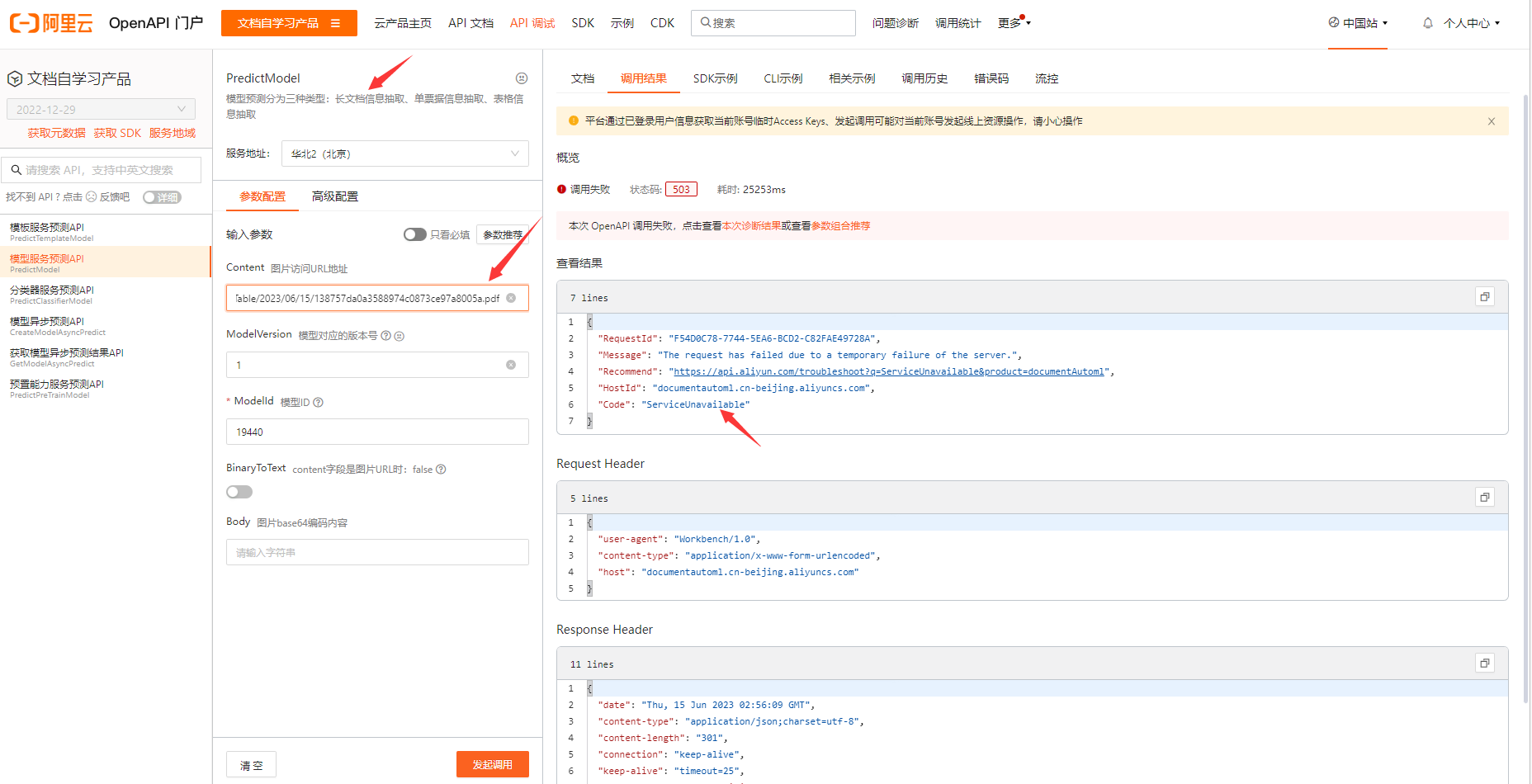 { "RequestId": "D6F4B1C1-AD55-53CF-BB90-3829D02D8D4D", "Message": "The request has failed due to a temporary failure of the server.", "Recommend": "https://api.aliyun.com/troubleshoot?q=ServiceUnavailable&product=documentAutoml", "HostId": "documentautoml.cn-beijing.aliyuncs.com", "Code": "ServiceUnavailable" } { "user-agent": "Workbench/1.0", "content-type": "application/x-www-form-urlencoded", "host": "documentautoml.cn-beijing.aliyuncs.com" } { "date": "Thu, 15 Jun 2023 03:09:54 GMT", "content-type": "application/json;charset=utf-8", "content-length": "301", "connection": "keep-alive", "keep-alive": "timeout=25", "access-control-allow-origin": "", "access-control-expose-headers": "", "x-acs-request-id": "D6F4B1C1-AD55-53CF-BB90-3829D02D8D4D", "x-acs-trace-id": "a9111acb007e97d9fb301856a33afba1" }问题2:换成base64也是报一样的错。
{ "RequestId": "D6F4B1C1-AD55-53CF-BB90-3829D02D8D4D", "Message": "The request has failed due to a temporary failure of the server.", "Recommend": "https://api.aliyun.com/troubleshoot?q=ServiceUnavailable&product=documentAutoml", "HostId": "documentautoml.cn-beijing.aliyuncs.com", "Code": "ServiceUnavailable" } { "user-agent": "Workbench/1.0", "content-type": "application/x-www-form-urlencoded", "host": "documentautoml.cn-beijing.aliyuncs.com" } { "date": "Thu, 15 Jun 2023 03:09:54 GMT", "content-type": "application/json;charset=utf-8", "content-length": "301", "connection": "keep-alive", "keep-alive": "timeout=25", "access-control-allow-origin": "", "access-control-expose-headers": "", "x-acs-request-id": "D6F4B1C1-AD55-53CF-BB90-3829D02D8D4D", "x-acs-trace-id": "a9111acb007e97d9fb301856a33afba1" }问题2:换成base64也是报一样的错。
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
抱歉给你带来困惑。根据你的描述,阿里云OCR接口在处理大于1MB的PDF文件时出现报错。这可能是因为接口对于文件大小有一定的限制。
为了解决该问题,你可以尝试以下两种方法之一:
将PDF文件转换为图片:可以使用PDF处理工具或库将PDF文件转换为图片格式(如JPEG、PNG),然后将得到的图片链接传递给OCR接口进行识别。
分割PDF文件:如果你需要识别的PDF文件包含多页,你可以将PDF文件分割为多个小文件,每个文件只包含少数几页。然后,将这些小文件的链接依次传递给OCR接口进行识别。
以上方法仅是临时的解决方案,用于处理大型PDF文件。如果你有更多的需求和要求,建议联系阿里云技术支持,以获取更详细和准确的解决方案。
针对问题1的回答:文件光下载就15s 网络太慢了。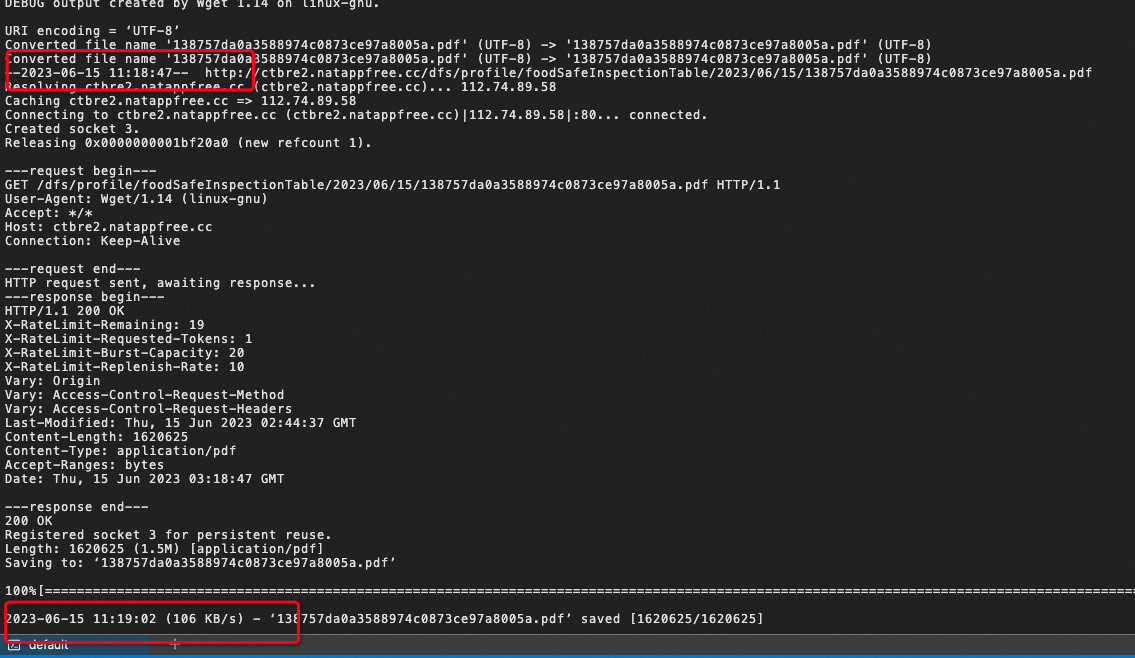 针对问题2的回答:
针对问题2的回答: 根据前面你反馈的信息,不是我们这边网络的问题。是您这边网速过慢,PDF太大传输超时。建议换一个网络试试。 此回答整理自钉群“【官方】阿里云OCR文档自学习用户答疑群”
根据前面你反馈的信息,不是我们这边网络的问题。是您这边网速过慢,PDF太大传输超时。建议换一个网络试试。 此回答整理自钉群“【官方】阿里云OCR文档自学习用户答疑群”


