
MaxCompute这个表里的input_bytes和实际logview差好几倍,确认差别是优化器优化前的数据量吗?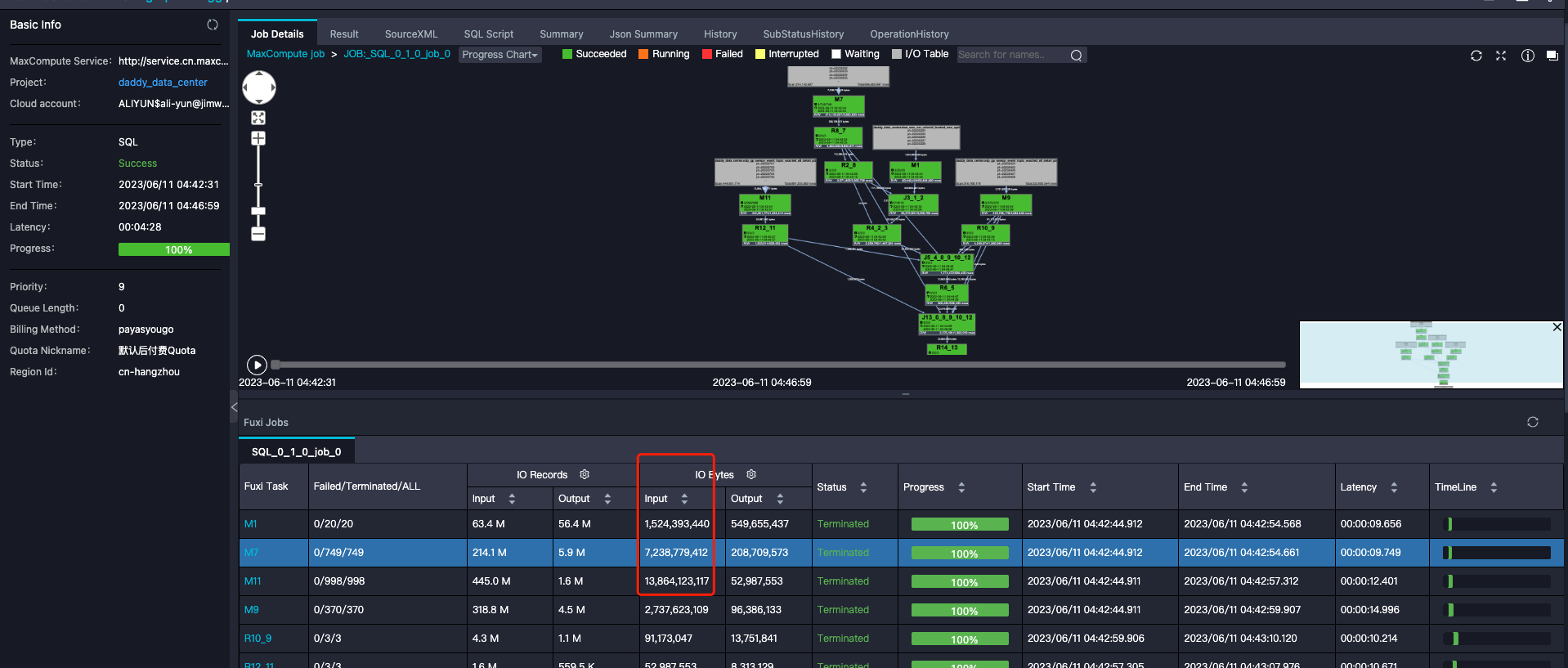
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在MaxCompute中,input_bytes与Logview中显示的数据量存在较大差异的情况,可能与优化器的处理逻辑有关。以下是可能导致这种现象的原因及分析方法:
MaxCompute的优化器在执行SQL任务时,会对输入数据进行统计和预估。如果表的元数据(如列统计信息、直方图等)不准确或缺失,优化器可能会基于保守策略生成较大的预估数据量。
- 原因:优化器在任务执行前会根据表的元数据估算输入数据量,而实际运行时可能会因为过滤条件、分区裁剪等操作减少数据量。 - 解决方法: - 使用ANALYZE TABLE命令刷新表的统计信息,确保优化器能够获取更准确的元数据。 sql ANALYZE TABLE <tablename> COMPUTE STATISTICS; - 如果表是外部表,可以启用在线统计收集功能,动态生成统计信息: sql SET odps.meta.exttable.stats.onlinecollect=true;
在Logview中看到的实际数据量可能已经经过了分区裁剪或过滤条件的处理,而input_bytes可能是优化器在任务提交时的原始输入数据量。
- 原因: - 如果SQL中包含分区过滤条件(如WHERE ds='20231001'),优化器可能在任务执行时减少了实际读取的数据量。 - 数据倾斜也可能导致部分Task处理的数据量远小于其他Task,从而影响Logview中的统计数据。 - 解决方法: - 检查SQL中是否包含分区过滤条件,并确认分区裁剪是否生效。 - 在Logview中查看每个Task的输入输出数据量分布,判断是否存在数据倾斜问题。
在复杂SQL任务中,某些中间计算步骤可能会导致数据膨胀,进而影响Logview中显示的数据量。
- 原因: - JOIN操作可能导致笛卡尔积或重复数据膨胀。 - GROUP BY或Aggregation操作可能生成大量中间结果。 - 解决方法: - 调整JOIN顺序,避免因数据分布不均导致的膨胀。 - 使用物化视图缓存中间结果,减少重复计算。
如果表中存在字段加密行为,或者使用了特定的存储格式(如ORC、CFile等),可能会导致存储量与实际数据量之间存在差异。
- 原因: - 字段加密会增加存储开销,导致input_bytes大于实际数据量。 - 不同存储格式的压缩率不同,可能影响Logview中显示的数据量。 - 解决方法: - 检查表的字段定义,确认是否存在加密字段。 - 确认表的存储格式,并评估其压缩效率。
如果SQL任务涉及动态分区写入,可能会在Logview中看到额外的元数据更新操作,导致数据量统计出现偏差。
- 原因: - 动态分区写入会在任务结束后更新表的元数据,这部分操作可能被计入Logview的统计数据。 - 解决方法: - 检查SQL是否涉及动态分区写入,并确认元数据更新是否影响了统计数据。
input_bytes与Logview中显示的数据量差异,通常是由优化器的预估逻辑、分区裁剪、数据倾斜、中间结果膨胀或存储格式等因素引起的。建议按照以下步骤排查问题: 1. 刷新表的统计信息,确保优化器获取准确的元数据。 2. 检查SQL中是否包含分区过滤条件,并确认分区裁剪是否生效。 3. 分析Logview中的Task分布,判断是否存在数据倾斜或中间结果膨胀。 4. 检查表的字段定义和存储格式,确认是否存在加密或压缩效率问题。
通过以上方法,您可以有效定位并解决input_bytes与Logview数据量差异的问题。
MaxCompute(原ODPS)是一项面向分析的大数据计算服务,它以Serverless架构提供快速、全托管的在线数据仓库服务,消除传统数据平台在资源扩展性和弹性方面的限制,最小化用户运维投入,使您经济并高效的分析处理海量数据。

