
"你好,我根据操作maxcompute spark 在idea调试,不能正常执行,这个是什么情况呢https://help.aliyun.com/document_detail/102430.html?spm=a2c4g.479449.0.0.8f70f54eMdaT6z 根据这个文档操作的,SparkPi可以,JavaSparkSQL这个类不行,好像出现格式问题,这种hive和odps哪里需要配置一下嘛?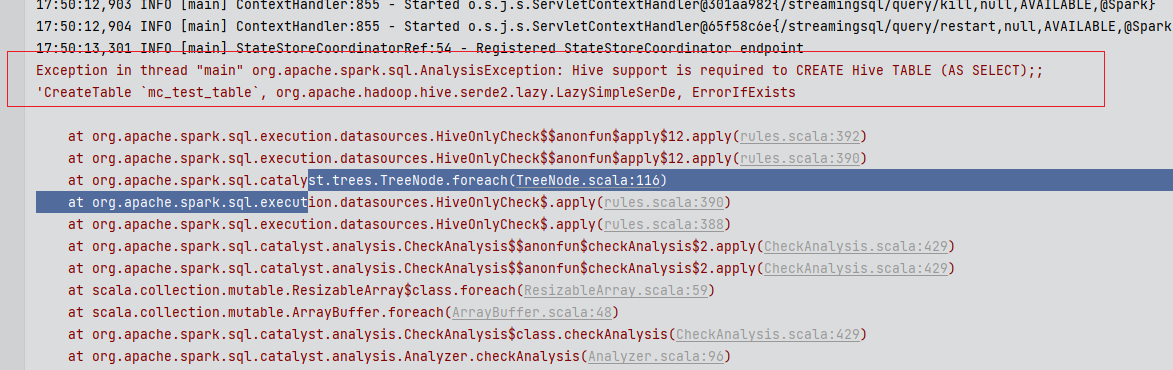 下载的时候是2.3,但是我的maxcompute 是2.4.5,我把它改成2.4.5了,我加了hive的校验策略之后变成这样了,是这里本地也要加一些参数嘛
下载的时候是2.3,但是我的maxcompute 是2.4.5,我把它改成2.4.5了,我加了hive的校验策略之后变成这样了,是这里本地也要加一些参数嘛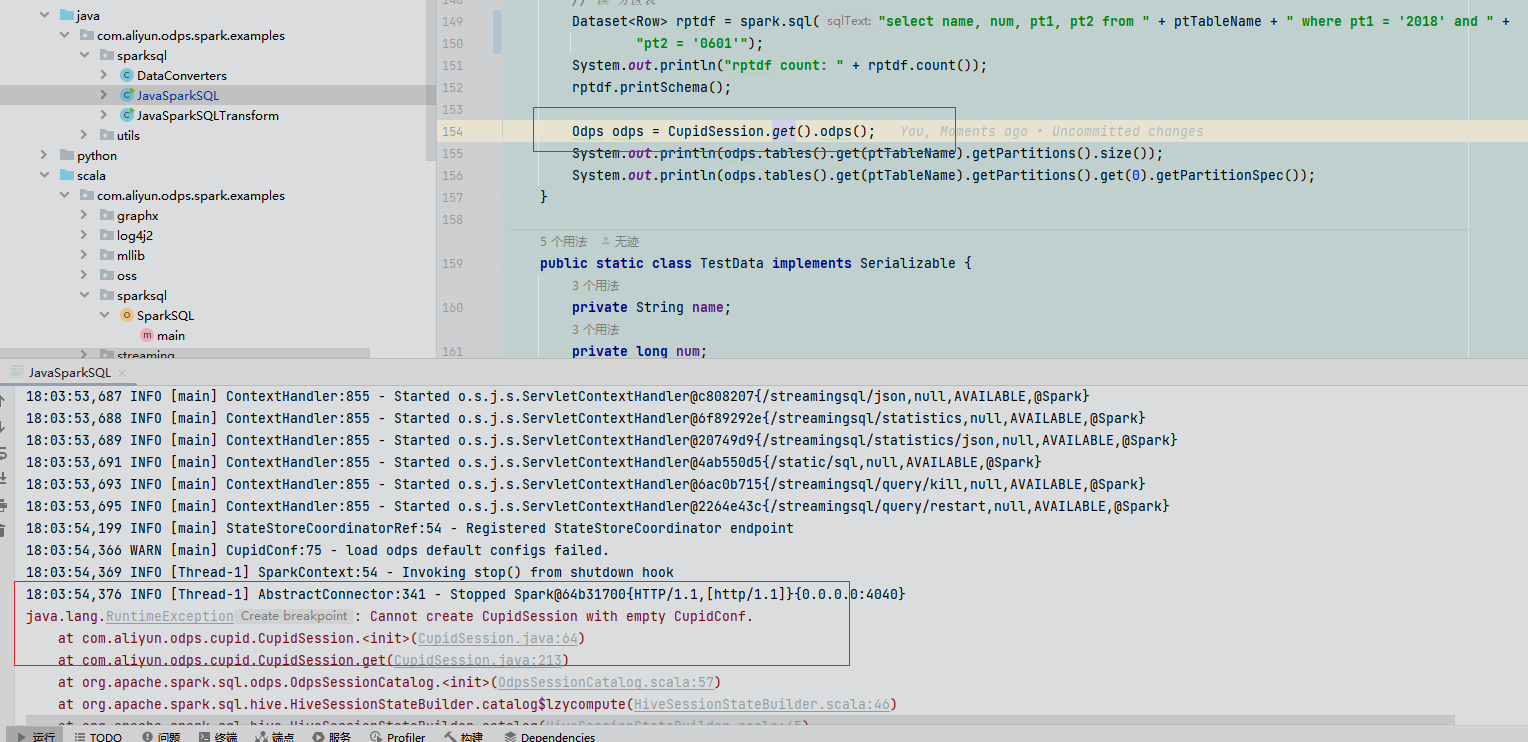 我修改了之后报上面新的错误,这个是这里需要做一些配置吗CupidConf,我看mc spark在idea执行分区表指定分区值插入会报错,在odps是正常的,这是正常现象吗,不存在分区值
我修改了之后报上面新的错误,这个是这里需要做一些配置吗CupidConf,我看mc spark在idea执行分区表指定分区值插入会报错,在odps是正常的,这是正常现象吗,不存在分区值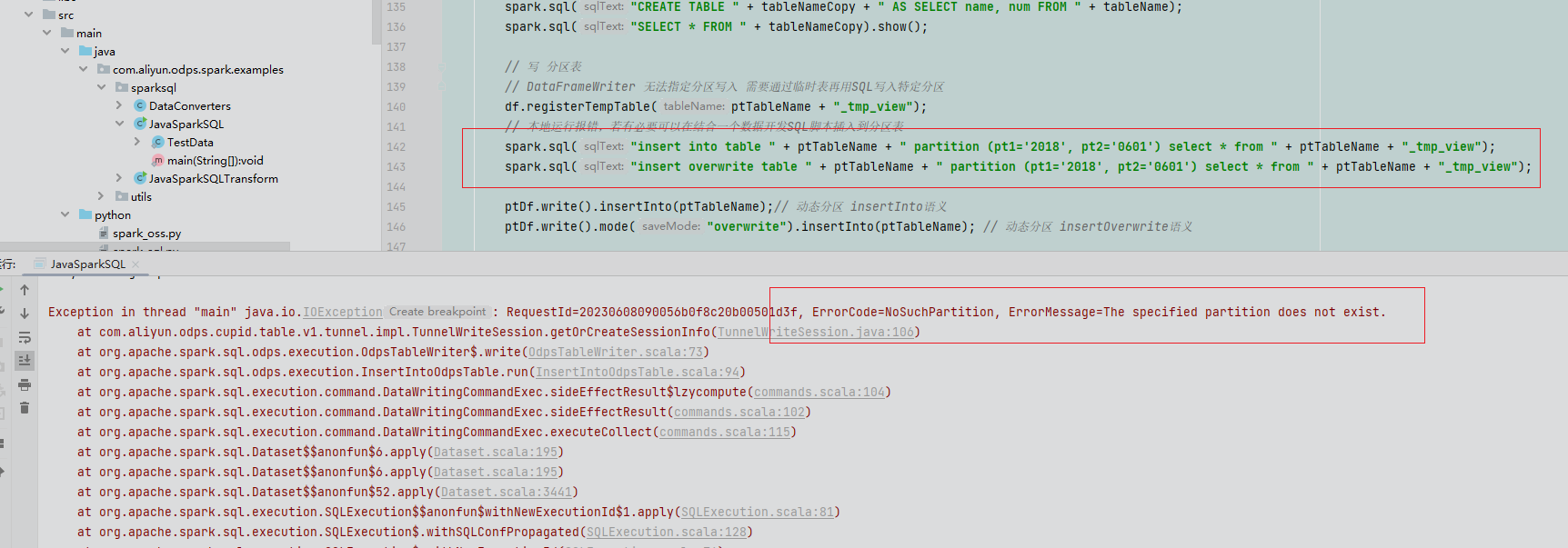 就是指定插入的分区值,显示指不存在,但是在odps执行是正确的,代码的话是官网文档下载的代码,https://help.aliyun.com/document_detail/149317.html?spm=a2c4g.148914.0.0.7c6d83adirwGut 这里下载的https://help.aliyun.com/document_de....7c6d83adirwGut,上传到odps可以 "
就是指定插入的分区值,显示指不存在,但是在odps执行是正确的,代码的话是官网文档下载的代码,https://help.aliyun.com/document_detail/149317.html?spm=a2c4g.148914.0.0.7c6d83adirwGut 这里下载的https://help.aliyun.com/document_de....7c6d83adirwGut,上传到odps可以 "
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
"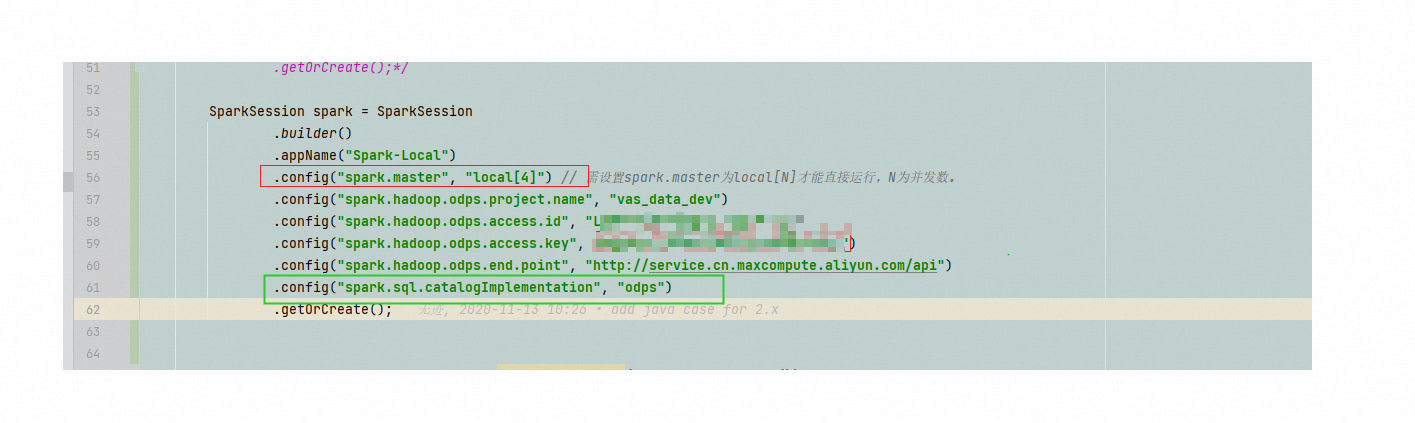 这个参数去掉试一下,这样试一下? 1.你自建一个file里边配置一下ak信息 odps.project.name= odps.access.id= odps.access.key= odps.end.point= 2. 代码里这样写 import org.apache.spark.sql.{SaveMode, SparkSession}
这个参数去掉试一下,这样试一下? 1.你自建一个file里边配置一下ak信息 odps.project.name= odps.access.id= odps.access.key= odps.end.point= 2. 代码里这样写 import org.apache.spark.sql.{SaveMode, SparkSession}
object SparkSQL_idea { def main(args: Array[String]): Unit = { // val spark = GetAllData.getSparkSession() val spark = SparkSession .builder() .appName(""SparkSQL"") .config(""spark.master"", ""local[2]"") .config(""spark.sql.catalogImplementation"", ""hive"") .config(""spark.sql.sources.default"", ""hive"") .config(""spark.sql.broadcastTimeout"", 20 * 60) .config(""spark.sql.crossJoin.enabled"", true) .config(""odps.exec.dynamic.partition.mode"", ""nonstrict"") .getOrCreate()
import spark._
import sqlContext.implicits._
val rdf = sql(""select * from bank_data limit 100"")
println(s""rdf count, ${rdf.count()}"")
rdf.printSchema()
}
}加一个本地的file文件写配置,把代码里的配置,写到一个文件里,这样 ,此回答整理自钉群“MaxCompute开发者社区2群(答疑@机器人)”"
,此回答整理自钉群“MaxCompute开发者社区2群(答疑@机器人)”"
MaxCompute(原ODPS)是一项面向分析的大数据计算服务,它以Serverless架构提供快速、全托管的在线数据仓库服务,消除传统数据平台在资源扩展性和弹性方面的限制,最小化用户运维投入,使您经济并高效的分析处理海量数据。

