
各位有没有碰到发起全局事务超时,seata服务报如下INFO io.seata.core.rpc.DefaultServerMessageListenerImpl - SeataMergeMessage timeout=60000,transactionName=
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
SeataMergeMessage timeout=60000,transactionName=xxx,表示在发起SeataMergeMessage timeout=60000,transactionName=xxx,表示在发起全局事务时,如果超过60秒(默认超时时间为60秒)没有收到Seata服务端的响应,则会触发超时异常。
这种情况可能是由于以下原因导致的:
针对以上情况,可以尝试以下解决方案:
增加Seata服务的超时时间,可以通过修改seata-server的配置文件来实现。具体操作如下:
seata.rpc.tm.retry.maxAttempts: 5
seata.rpc.tm.retry.interval: 1000
seata.rpc.tm.retry.initialInterval: 1000
其中,retry.maxAttempts表示最大重试次数,retry.interval表示每次重试之间的间隔时间,retry.initialInterval表示初始重试间隔时间。
检查Seata服务端的日志,查找是否有异常信息或错误提示,以便进一步排查问题。
如果Seata服务端负载过高,可以考虑优化业务逻辑或者增加服务器资源来提高处理能力。
楼主你好,根据你的问题来看,可能是全局事务在指定的超时时间内没有完成,并且达到了RPC通信的超时时间。你可以增加全局事务的超时时间,在代码中或者Seata的配置文件中找到全局事务的超时时间设置项,例如seata.tm.commit.retry.count和seata.tm.commit.retry.timeout,适当增加其值来延长全局事务的超时时间。
注意:本回答参考了阿里云Seata官方文档。
这条日志表示 Seata 服务接收到了一个合并消息(SeataMergeMessage),这个消息通常是由多个请求合并而成,以减少网络传输的次数和提高效率。timeout=60000 表示设置的事务超时时间是 60000 毫秒(即 60 秒),而 transactionName= 后面应该是跟着事务的名字,但在这个日志中看起来是空的。
这个日志是一个 INFO 级别的日志,通常表示信息性的消息,不是错误或警告。然而,如果 transactionName 部分为空,这可能意味着在发送消息时没有提供事务名称,这可能是正常的,也可能是配置不当或使用不当的迹象。
这种情况通常是由于全局事务在 Seata 中的某个阶段(如提交或回滚)未能在默认的超时时间内完成,从而导致 Seata 服务输出超时的日志信息。
这个问题可能由以下原因引起:
分支事务处理时间过长: 全局事务包含多个分支事务,如果某个分支事务的处理时间超过了 Seata 配置的默认超时时间,就会导致整个全局事务超时。这可能是由于分支事务中的数据库操作、业务逻辑等耗时较长导致的。
Seata 服务配置问题: 检查 Seata 服务的配置文件,查看全局超时时间(globalTransactionTimeout)是否合理。可以适当调整这个值来延长全局事务的超时时间。
网络或性能问题: 如果网络延迟较高或者 Seata 服务本身的性能存在问题,也可能导致事务超时。确保网络通信畅通,Seata 服务能够正常响应请求。
为了进一步定位问题,可以考虑以下步骤:
查看事务日志: 在 Seata 服务的日志中,查找关于具体事务的日志信息,看看是否有其他相关的错误或异常信息。
查看分支事务状态: 使用 Seata 提供的工具或查询接口,查看分支事务的状态,确认是否有某个分支事务一直处于某个阶段未能完成。
性能分析: 使用性能分析工具,了解 Seata 服务的性能瓶颈或者耗时较长的操作。
从你提供的日志信息来看,这里提到的是"SeataMergeMessage timeout=60000",这意味着在尝试合并事务消息时超时时间为60000毫秒(即60秒)。
以下是一些建议和可能的原因:
Seata服务可能会报超时错误,这可能是由于集群中存在close状态的索引导致的。您可以通过使用GET /_cat/indices?v命令查看索引状态,如果存在close状态的索引,可以通过POST //_open将其打开。
SeataMergeMessage timeout=60000,transactionName=xxx,表示在发起SeataMergeMessage timeout=60000,transactionName=xxx,表示在发起全局事务时,如果超过60秒(60000毫秒)没有收到响应,则会触发超时。
这种情况可能是由于以下原因导致的:
针对以上原因,可以尝试以下解决方案:
您提到的这个问题可能是由于 Seata 服务在发起全局事务时超时导致的。要解决这个问题,您可以尝试以下方法:
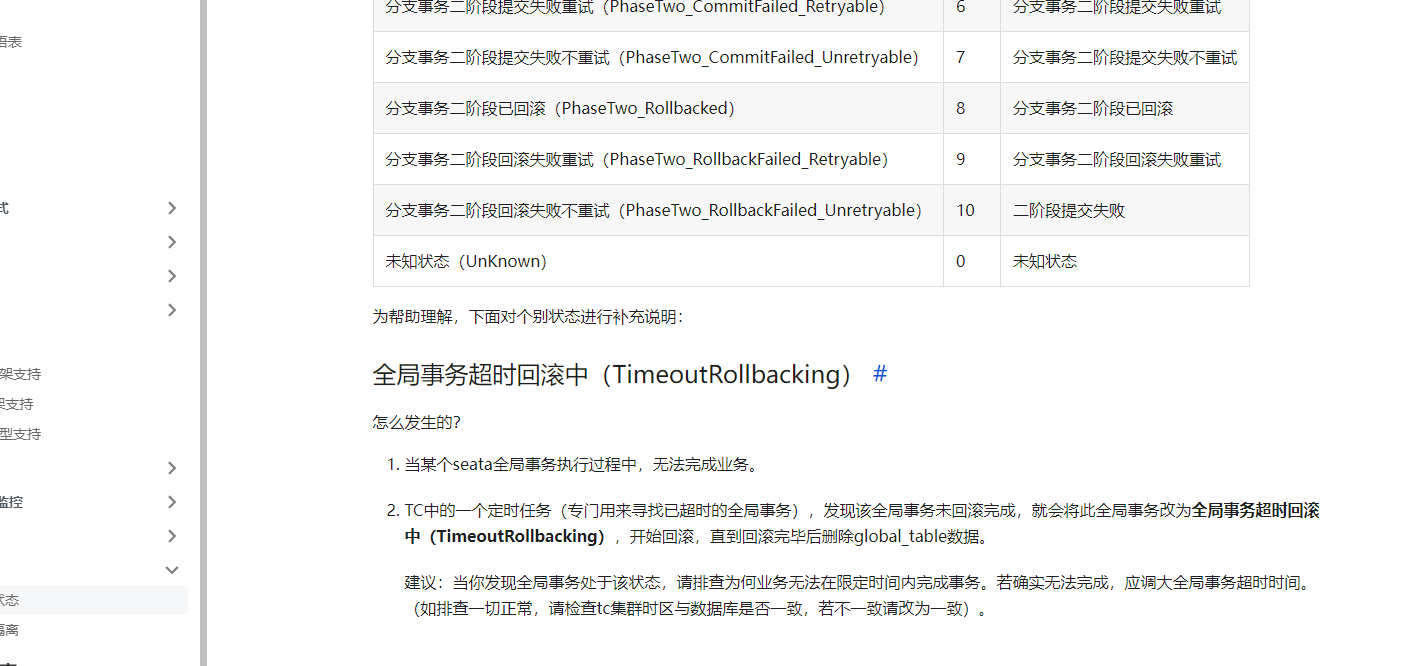
全局事务超时回滚中(TimeoutRollbacking)
怎么发生的?
https://seata.io/zh-cn/docs/user/appendix/global-transaction-status/
当某个seata全局事务执行过程中,无法完成业务。
TC中的一个定时任务(专门用来寻找已超时的全局事务),发现该全局事务未回滚完成,就会将此全局事务改为全局事务超时回滚中(TimeoutRollbacking),开始回滚,直到回滚完毕后删除global_table数据。
建议:当你发现全局事务处于该状态,请排查为何业务无法在限定时间内完成事务。若确实无法完成,应调大全局事务超时时间。(如排查一切正常,请检查tc集群时区与数据库是否一致,若不一致请改为一致)。
阿里云拥有国内全面的云原生产品技术以及大规模的云原生应用实践,通过全面容器化、核心技术互联网化、应用 Serverless 化三大范式,助力制造业企业高效上云,实现系统稳定、应用敏捷智能。拥抱云原生,让创新无处不在。

