
问题1:机器学习PAI官网关于Prophet的例子没有一个能跑得通的。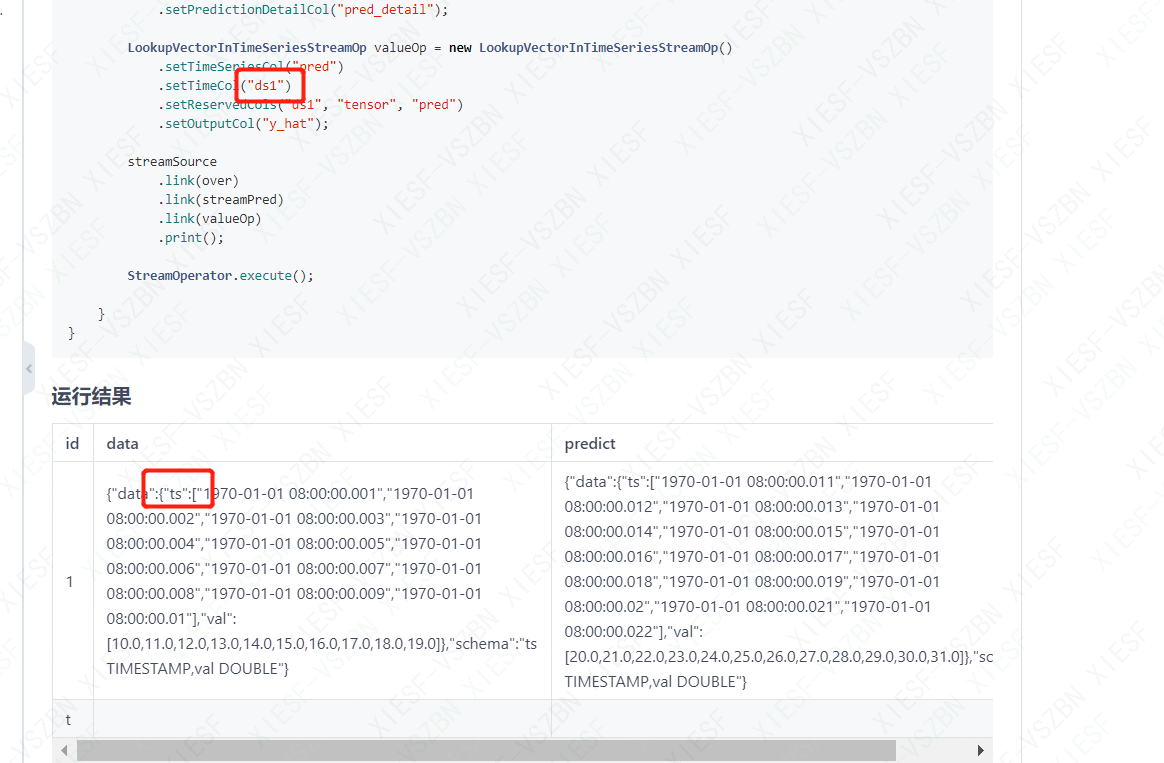 打印的key和定义的key都不一样,怎么回事?问题2:
打印的key和定义的key都不一样,怎么回事?问题2: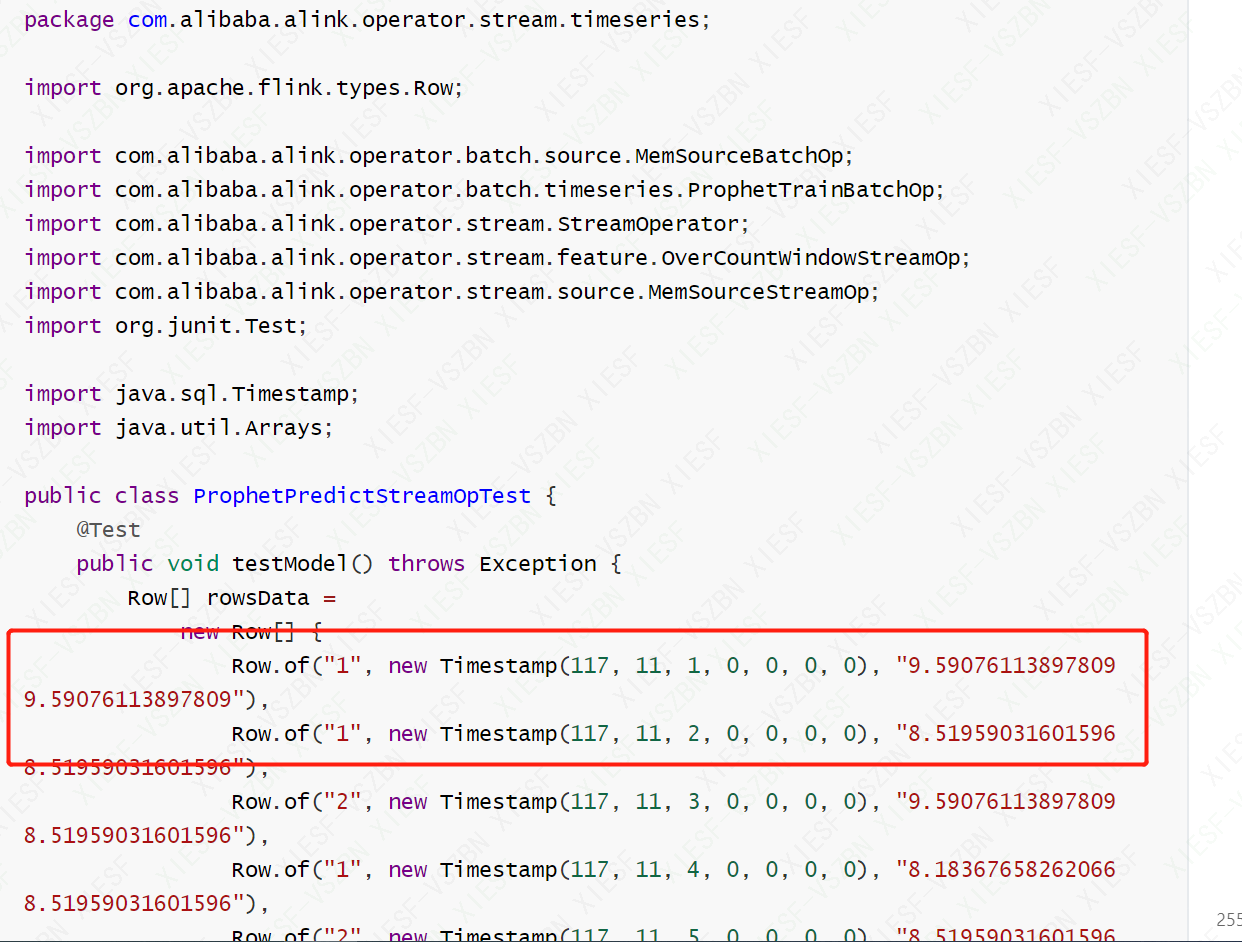
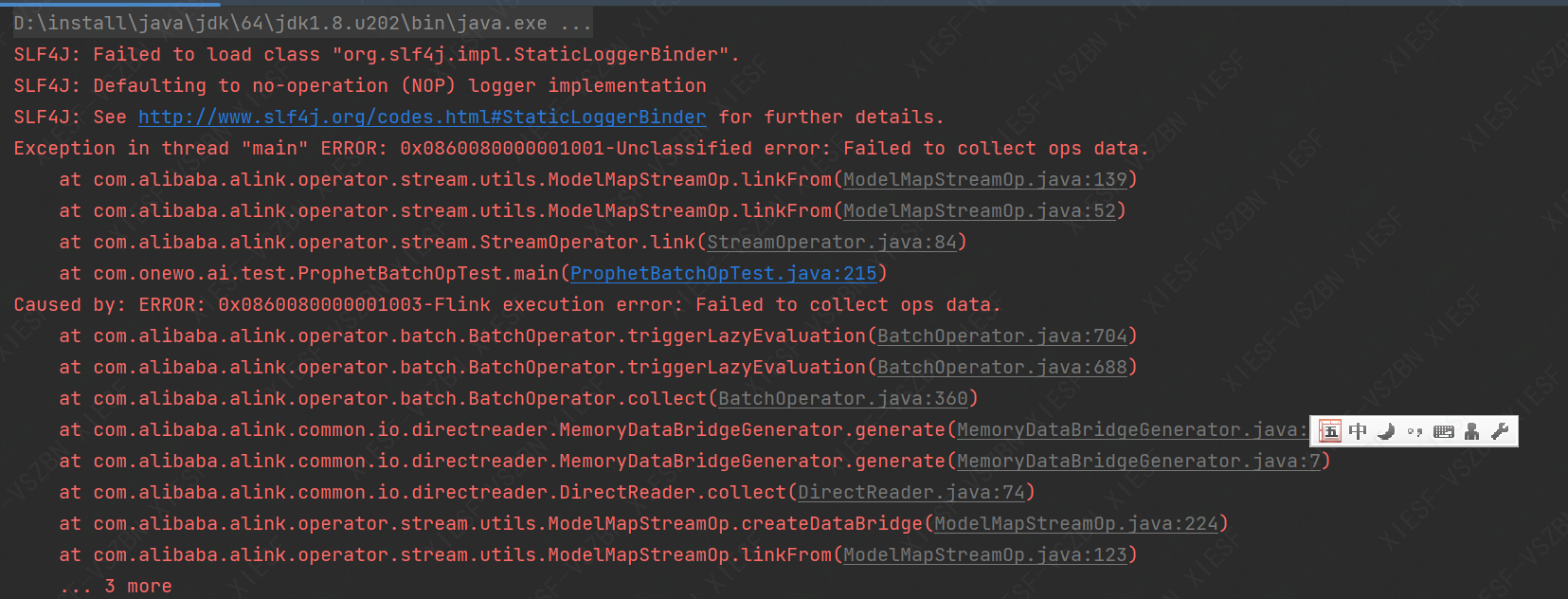
 代码和报错如上图,麻烦看看代码一不一样?
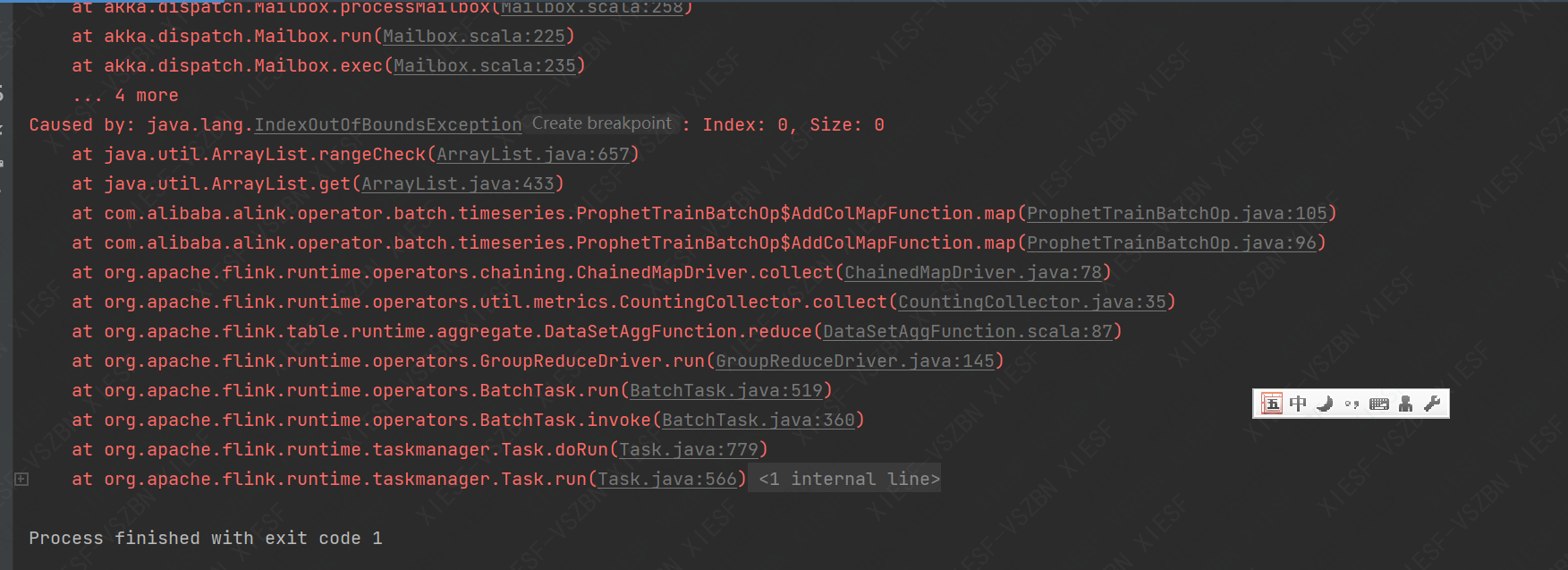
代码和报错如上图,麻烦看看代码一不一样?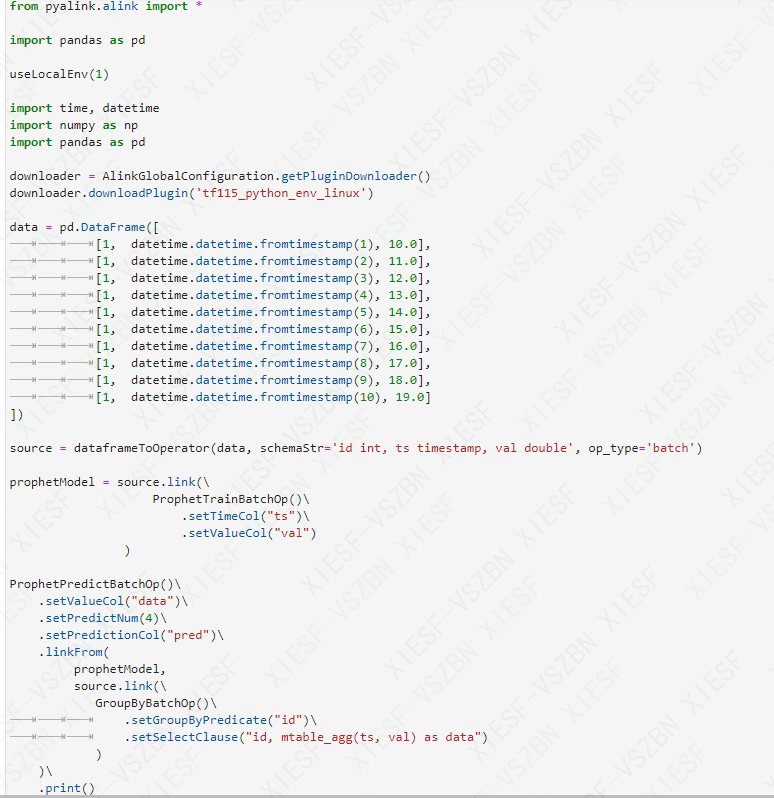 还有上图Prophet预测 (ProphetPredictBatchOp)这个示例代码报以下错误。
还有上图Prophet预测 (ProphetPredictBatchOp)这个示例代码报以下错误。 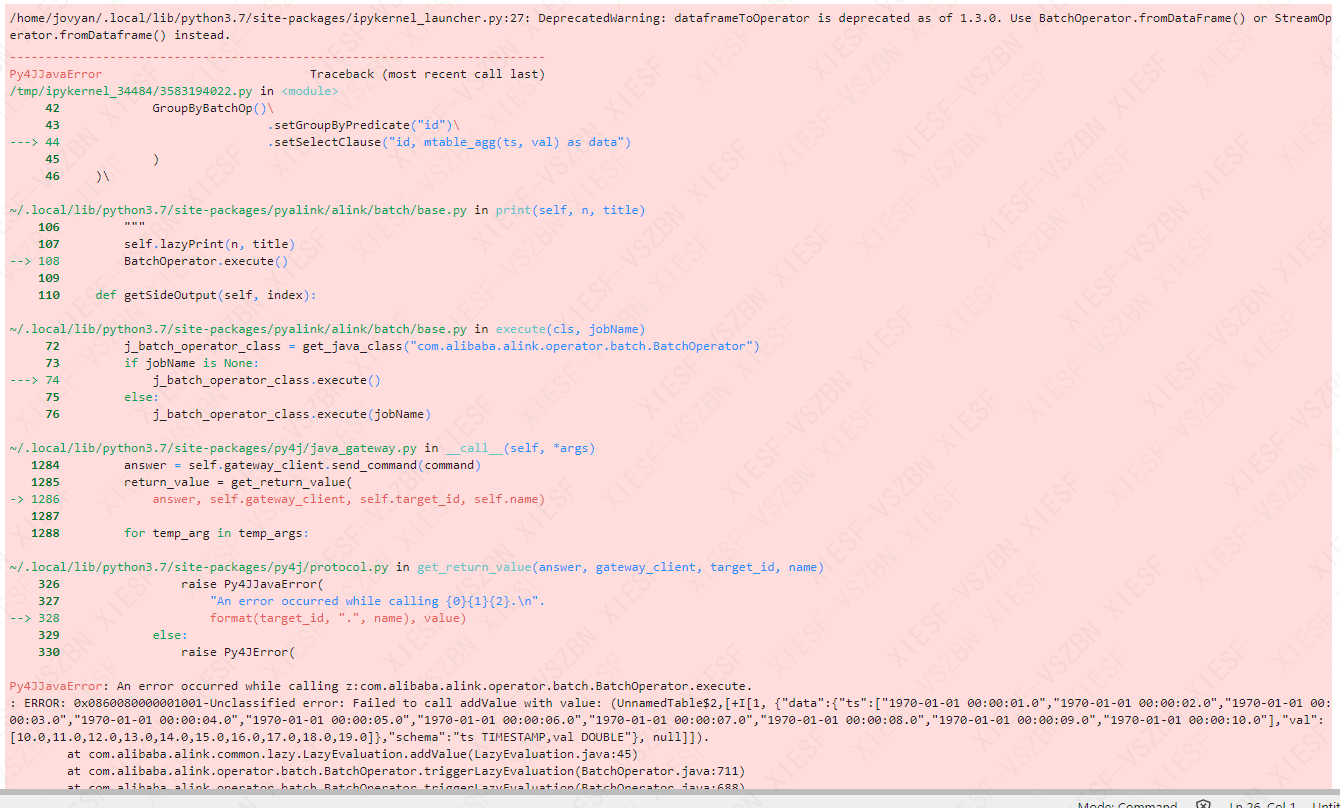 可以验证一下。
可以验证一下。
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
您在使用阿里云机器学习PAI官网提供的 Prophet 例子时,打印的 key 和定义的 key 不一致的原因可能是因为数据格式不一致所致。
在 Prophet 例子中,尤其是时间序列预测任务,我们需要按照预先定义好的时间序列格式进行数据组织。在使用 Prophet 进行预测时,我们首先需要对数据进行以下处理:
ds 列,并且是 Pandas 中的 Datetime 格式。可以使用 pd.to_datetime() 函数将时间戳转换为 Datetime 格式。y 列,并且是数值类型。可以使用 Pandas 的 astype() 函数将数据类型转换为数值类型。具体地,在阿里云机器学习PAI官网提供的 Prophet 例子中,您需要按照如下方式修改数据集:
df = df.sort_values('date')
在上述代码中,将数据根据时间戳列 date 进行排序,确保时间顺序正确。
df['ds'] = pd.to_datetime(df['date'], format='%Y-%m-%d %H:%M:%S')
在上述代码中,使用 pd.to_datetime() 函数将时间戳列 date 转换为 Datetime 格式,存储在 ds 列中。
df['y'] = df['value'].astype(float)
在上述代码中,使用 Pandas 的 astype() 函数将数据类型转换为浮点类型,存储在 y 列中。
如果您对数据集进行了以上的处理,那么在使用 Prophet 进行预测时,打印出来的 key 应该和定义的 key 一致。
Prophet是由Facebook开发的一个开源时间序列预测框架,其主要目的是为非专业的数据科学家提供一个易于使用且高效的工具来进行时间序列的预测和建模。Prophet具有高度灵活性和可扩展性,能够自动处理一些常见的时间序列问题,如季节性、节假日和异常值等。
Prophet的使用非常简单,你只需要安装Prophet包并遵循以下步骤:
准备你的数据:Prophet需要你的数据拥有两列,一列是时间戳(ds),一列是要预测的数值(y)。
创建Prophet模型:使用Prophet的Python API创建一个Prophet模型,并设置一些超参数,如季节周期和节假日等信息。
拟合模型:使用拟合方法将模型拟合到你的数据。
预测未来值:使用模型进行预测,并获取预测结果。
以下是一个简单的例子:
# 导入必要的库
from fbprophet import Prophet
import pandas as pd
# 创建一个数据框,包含需要预测的时间序列数据
df = pd.read_csv('example.csv')
# 将时间戳转换为标准日期格式
df['ds'] = pd.to_datetime(df['ds'])
# 创建一个Prophet模型并拟合数据
model = Prophet()
model.fit(df)
# 预测未来的数据
future = model.make_future_dataframe(periods=365)
forecast = model.predict(future)
# 输出预测结果
print(forecast[['ds', 'yhat', 'yhat_lower', 'yhat_upper']].tail())
在这个例子中,我们首先导入了必要的库,然后创建一个包含需要预测的时间序列数据的数据框。我们将时间戳转换为标准日期格式,并创建一个Prophet模型并拟合数据。然后,我们使用模型进行预测,并输出预测结果。在这个例子中,我们使用了365天的时间来预测未来的数据。
请注意,这只是Prophet的一个简单示例。Prophet有很多其他的超参数和选项,您可以根据您的需求进行调整。
针对问题1的回答:我刚跑了下这个Case,是可以跑的,下图是我这边的结果。文档上是之前老的结果,这个不好意思,后面我们修改下。 另外,能把错误发一下吗?看看具体的原因。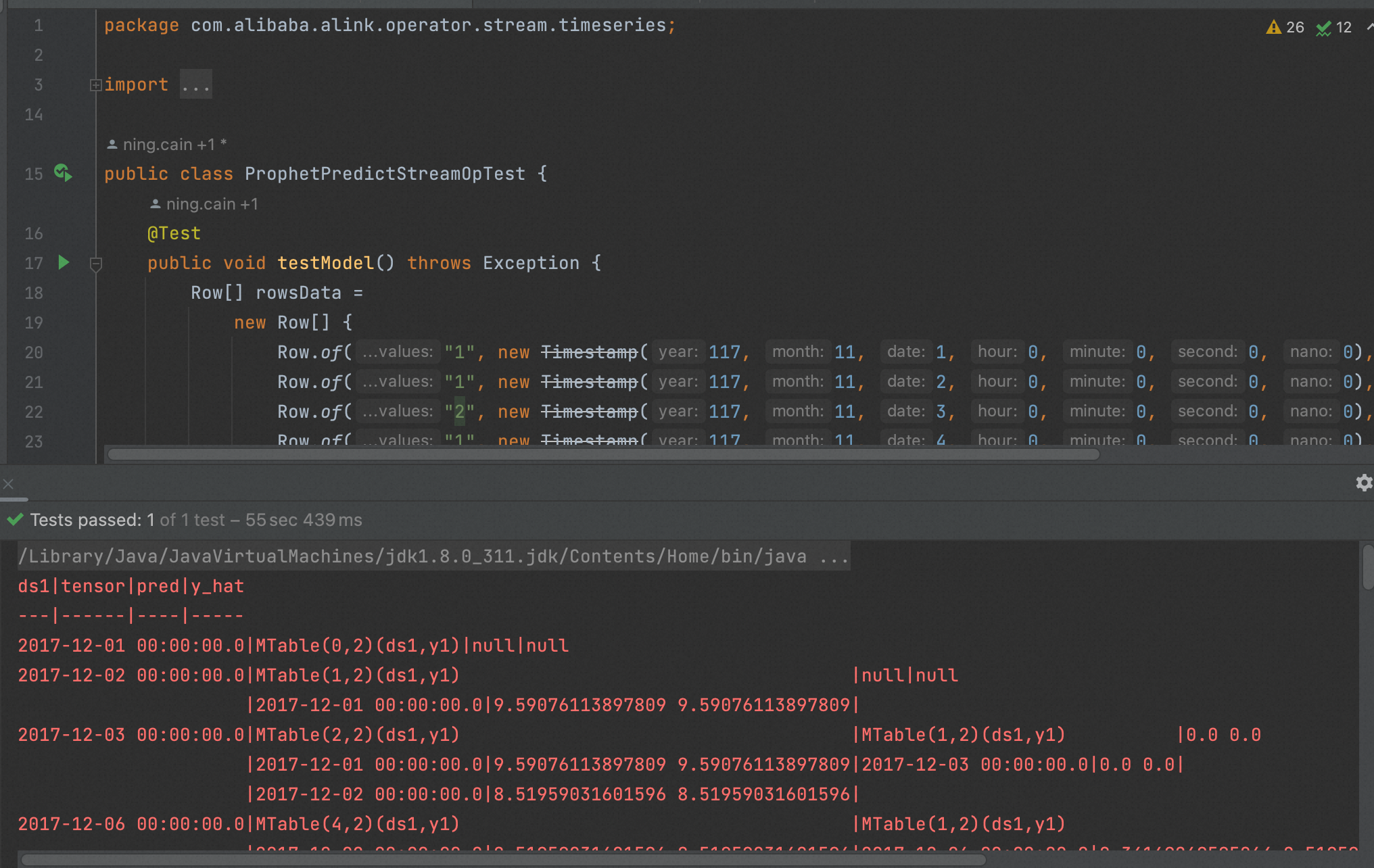 此回答整理自钉群“Alink开源--用户群”
此回答整理自钉群“Alink开源--用户群”
人工智能平台 PAI(Platform for AI,原机器学习平台PAI)是面向开发者和企业的机器学习/深度学习工程平台,提供包含数据标注、模型构建、模型训练、模型部署、推理优化在内的AI开发全链路服务,内置140+种优化算法,具备丰富的行业场景插件,为用户提供低门槛、高性能的云原生AI工程化能力。



