
大佬们Flink CDC中有空帮忙看下 还是这个问题?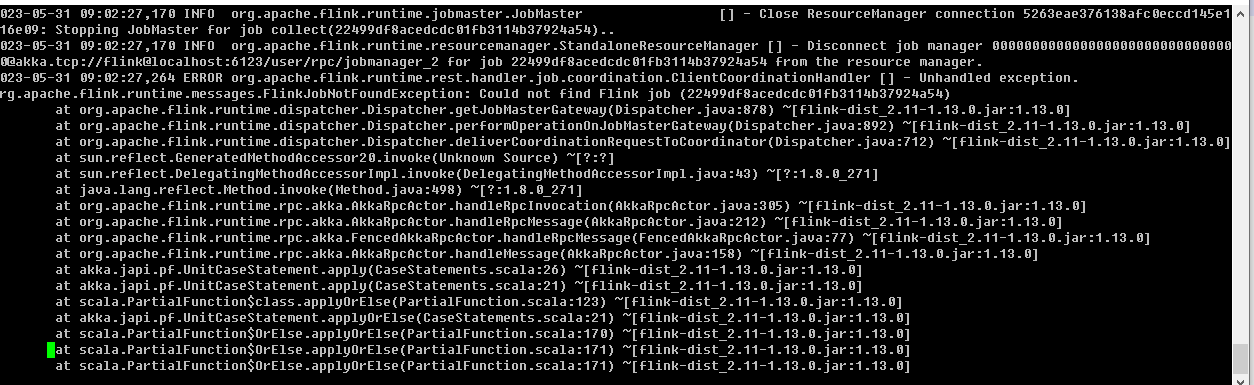 服务都起来了
服务都起来了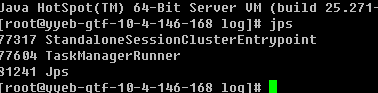
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
根据您提供的问题描述“大佬们Flink CDC中有空帮忙看下 还是这个问题? 服务都起来了”,结合知识库中的参考资料,以下是可能的原因分析和解决方案:
您的问题描述较为简略,建议明确以下几点: - 具体报错信息:是否有明确的错误日志或异常提示? - 作业状态:Flink作业是否正常运行,还是处于失败、重启或反压状态? - 数据同步情况:是否已经完成全量数据同步?增量数据是否正常消费?
如果可以提供具体的错误日志或现象描述,将有助于更精准地定位问题。
restart-strategy配置正确,避免作业因失败而无限重启。restart-strategy: fixed-delay
restart-strategy.fixed-delay.attempts: 2
restart-strategy.fixed-delay.delay: 10 s
全量数据同步完成后不读取增量数据:
SHOW VARIABLES LIKE 'expire_logs_days';
SET GLOBAL expire_logs_days=7;
跳过Snapshot阶段直接读取增量数据:
scan.startup.mode参数为latest-offset,从最新的Binlog位点开始消费。WITH (
'scan.startup.mode' = 'latest-offset'
)
SELECT、REPLICATION SLAVE和REPLICATION CLIENT权限。Binlog_Do_DB和Binlog_Ignore_DB配置是否过滤了目标库的Binlog:SHOW MASTER STATUS;
timestamp字段时区相差8小时,可能是时区配置不一致导致的:
WITH (
'server-time-zone' = 'Asia/Shanghai'
)
重复事件投递:如果使用Canal或Maxwell作为中间件,可能会在故障时投递重复事件。
table.exec.source.cdc-events-duplicate=true,并定义主键以去重。CREATE TABLE source_table (
id BIGINT PRIMARY KEY NOT ENFORCED,
...
) WITH (
'table.exec.source.cdc-events-duplicate' = 'true'
);
分片参数优化:对于大表的全量同步,建议调整分片参数以优化内存使用。
WITH (
'scan.incremental.snapshot.chunk.key-column' = 'id',
'scan.incremental.snapshot.chunk.size' = '10000'
)
如果仍有疑问,请随时补充详细信息,我们将为您提供进一步支持!
