
DataWorks中mongodb写rds报错,怎么办?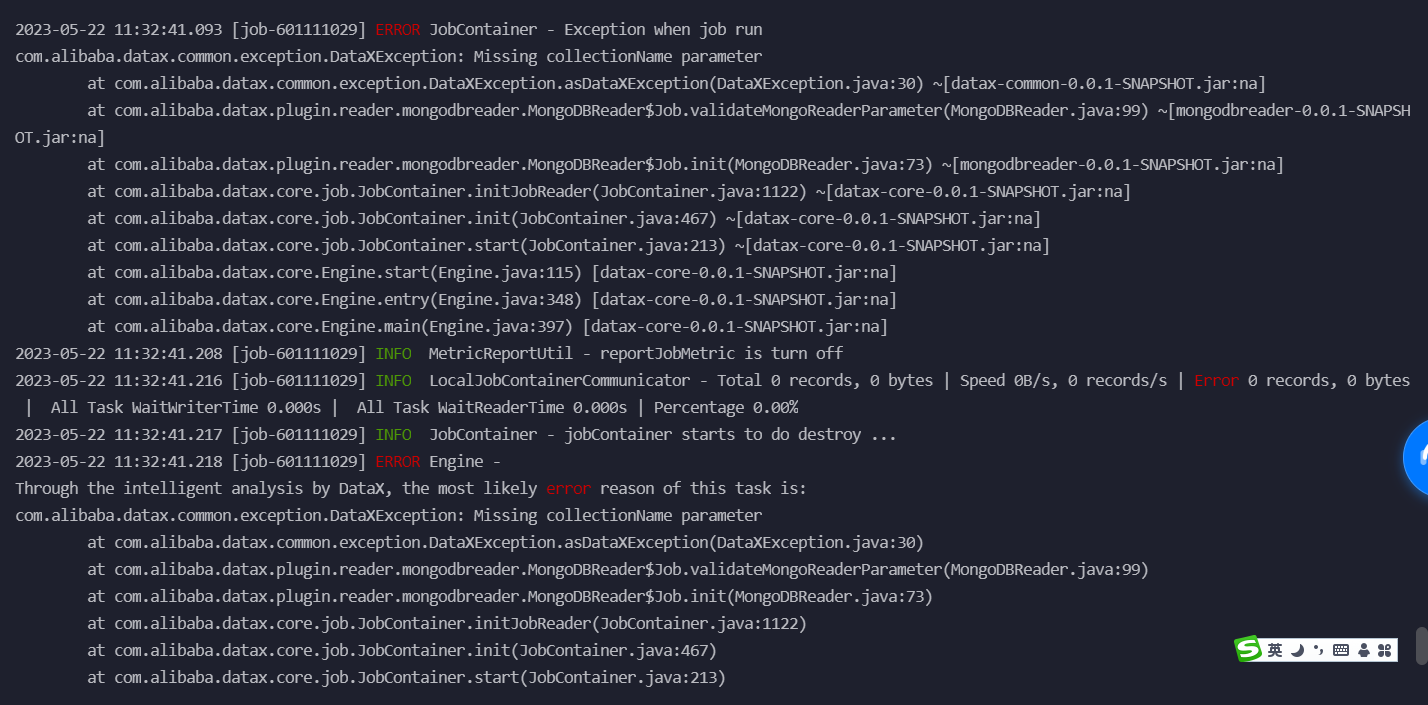
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在DataWorks中将MongoDB数据写入RDS时,可能会遇到报错问题。以下是针对常见报错的详细分析和解决方案:
可能原因: - 网络连接问题导致通信失败。 - RDS实例的白名单配置不正确。
解决方法: - 检查网络连通性,确保DataWorks与RDS之间的网络是通畅的。 - 确认RDS实例的白名单设置是否包含DataWorks资源组的IP地址。如果未添加,请将正确的IP地址加入白名单。 - 如果使用的是独享资源组,还需检查VPC配置是否正确。
可能原因: - 亚马逊RDS的负载均衡健康检查机制可能导致主机被阻塞。
解决方法: - 关闭亚马逊RDS的负载均衡健康检查功能。关闭后,Host is blocked问题将不再出现。
可能原因: - 数据库账号或密码错误。 - 实例连接地址中的鉴权数据库信息不正确。
解决方法: - 检查RDS的用户名和密码是否正确。如果密码中包含特殊字符(如!@#$%^&*()),需要对特殊字符进行转义处理。 - 确保连接串中指定了正确的鉴权数据库。例如,如果账号属于admin数据库,则需在连接串中明确指定。
可能原因: - 写入数据量过大,导致请求超时或失败。
解决方法: - 减小单次写入的数据量,分批写入数据。 - 增加写入任务的超时时间配置,确保有足够的时间完成写入操作。
可能原因: - 全量拉取数据过大,导致任务运行超时。
解决方法: - 加大并发:增加同步任务的并发数,提升数据处理能力。 - 减小BatchSize:降低每次读取的数据量,避免单次操作耗时过长。 - 调整超时配置:在MongoDB Reader的parameter参数中,增加cursorTimeoutInMs配置,并将其值设置为较大的数值(如3600000ms)。
可能原因: - MongoDB副本集实例发生了主备切换,导致当前连接的节点变为从节点,无法执行写入操作。
解决方法: - 手动切换节点角色:将业务实际连接的节点切换为主节点。 - 使用ConnectionStringURI地址连接:推荐生产环境的应用程序通过ConnectionStringURI地址连接MongoDB实例,以避免主备切换对业务的影响。 - 设计重连机制:为业务逻辑添加自动重连和异常处理能力,确保在连接中断后能够快速恢复。
col1至col6)。请检查字段映射配置,确保源端和目标端字段一致。根据具体报错信息,您可以按照上述步骤逐一排查并解决问题。如果问题仍未解决,建议结合日志信息进一步分析,或联系阿里云技术支持获取帮助。您可以复制页面截图提供更多信息,我可以进一步帮您分析问题原因。
DataWorks基于MaxCompute/Hologres/EMR/CDP等大数据引擎,为数据仓库/数据湖/湖仓一体等解决方案提供统一的全链路大数据开发治理平台。

