
DataWorks中我的数据库中根据任务sql查询有数据,且本地执行数据会导入odps中,但定时任务跑起来没有数据录入,时间参数使用的是定时任务的参数
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
选择数据源。配置同步任务的数据来源和数据去向。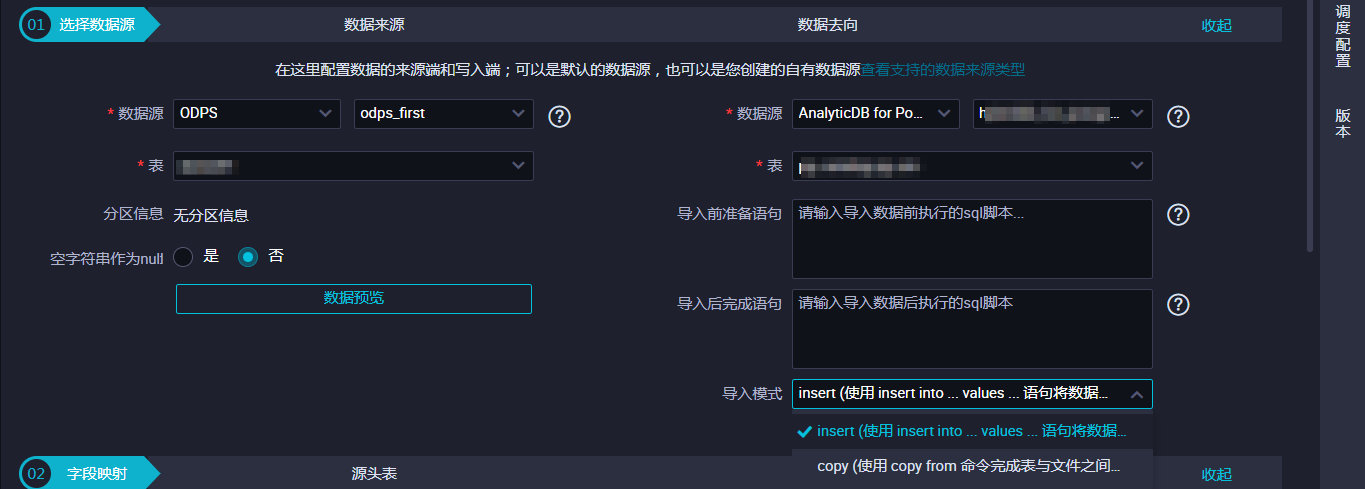 参数 描述 数据源 即上述参数说明中的datasource,通常选择您配置的数据源名称。 表 即上述参数说明中的table,选择需要同步的表。 导入前准备语句 即上述参数说明中的preSql,输入执行数据同步任务之前率先执行的SQL语句。 导入后完成语句 即上述参数说明中的postSql,输入执行数据同步任务之后执行的SQL语句。 导入模式 即上述参数说明中的writeMode,包括insert和copy两种模式。字段映射,即上述参数说明中的column。左侧的源头表字段和右侧的目标表字段为一一对应的关系。
参数 描述 数据源 即上述参数说明中的datasource,通常选择您配置的数据源名称。 表 即上述参数说明中的table,选择需要同步的表。 导入前准备语句 即上述参数说明中的preSql,输入执行数据同步任务之前率先执行的SQL语句。 导入后完成语句 即上述参数说明中的postSql,输入执行数据同步任务之后执行的SQL语句。 导入模式 即上述参数说明中的writeMode,包括insert和copy两种模式。字段映射,即上述参数说明中的column。左侧的源头表字段和右侧的目标表字段为一一对应的关系。 参数 描述 同名映射 单击同名映射,可以根据名称建立相应的映射关系,请注意匹配数据类型。 同行映射 单击同行映射,可以在同行建立相应的映射关系,请注意匹配数据类型。 取消映射 单击取消映射,可以取消建立的映射关系。 自动排版 可以根据相应的规律自动排版。通道控制。
参数 描述 同名映射 单击同名映射,可以根据名称建立相应的映射关系,请注意匹配数据类型。 同行映射 单击同行映射,可以在同行建立相应的映射关系,请注意匹配数据类型。 取消映射 单击取消映射,可以取消建立的映射关系。 自动排版 可以根据相应的规律自动排版。通道控制。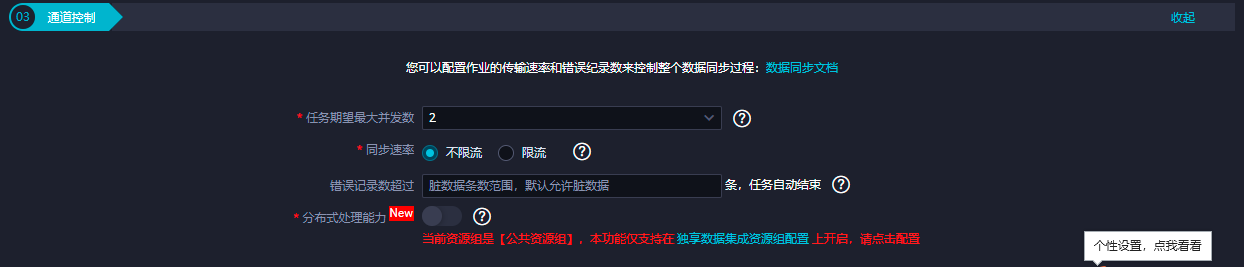 参数 描述 任务期望最大并发数 数据同步任务内,可以从源并行读取或并行写入数据存储端的最大线程数。向导模式通过界面化配置并发数,指定任务所使用的并行度。 同步速率 设置同步速率可以保护读取端数据库,以避免抽取速度过大,给源库造成太大的压力。同步速率建议限流,结合源库的配置,请合理配置抽取速率。 错误记录数 错误记录数,表示脏数据的最大容忍条数。 分布式处理能力 数据同步时,可以将任务切片分散到多台执行节点上并发执行,提高同步速率。该模式下,配置较大任务并发数会增加数据存储访问压力,如需使用该功能,请提前评估数据存储的访问负载。该功能仅支持在独享数据集成资源组配置,详情请参见独享数据集成资源组和新增和使用独享数据集成资源组。 https://help.aliyun.com/document_detail/137781.html,此回答整理自钉群“DataWorks交流群(答疑@机器人)”
参数 描述 任务期望最大并发数 数据同步任务内,可以从源并行读取或并行写入数据存储端的最大线程数。向导模式通过界面化配置并发数,指定任务所使用的并行度。 同步速率 设置同步速率可以保护读取端数据库,以避免抽取速度过大,给源库造成太大的压力。同步速率建议限流,结合源库的配置,请合理配置抽取速率。 错误记录数 错误记录数,表示脏数据的最大容忍条数。 分布式处理能力 数据同步时,可以将任务切片分散到多台执行节点上并发执行,提高同步速率。该模式下,配置较大任务并发数会增加数据存储访问压力,如需使用该功能,请提前评估数据存储的访问负载。该功能仅支持在独享数据集成资源组配置,详情请参见独享数据集成资源组和新增和使用独享数据集成资源组。 https://help.aliyun.com/document_detail/137781.html,此回答整理自钉群“DataWorks交流群(答疑@机器人)”
DataWorks基于MaxCompute/Hologres/EMR/CDP等大数据引擎,为数据仓库/数据湖/湖仓一体等解决方案提供统一的全链路大数据开发治理平台。

