
flinkcdc可以基于查询做同步吗?不通过日志,根据记录的时间戳做增量同步(不考虑删除的场景);
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
Flink CDC(Change Data Capture)是基于数据库的日志实现的增量数据同步工具,它通过解析数据库的事务日志来捕获数据的变化,并将变化的数据传递给下游处理。Flink CDC通常用于将数据从数据库同步到其他数据存储或数据处理系统。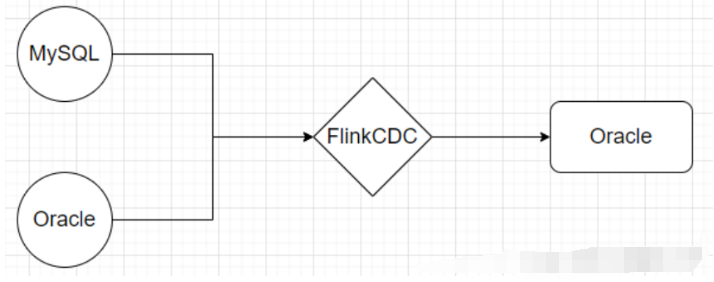
基于查询的增量同步是一种不使用数据库日志的方式,而是根据记录的时间戳来判断数据的增量变化。这种方式在某些场景下是可行的,但需要注意以下几点:
1、需要有一个可靠的时间戳字段:在数据库中,每条记录需要有一个可靠的时间戳字段来表示数据的更新时间。这个字段可以是数据库自带的时间戳字段,或者是应用程序自定义的字段。通过查询这个时间戳字段,可以确定哪些数据是新增或更新的。
2、需要定期轮询数据:为了获取增量数据,需要定期轮询数据库,查询时间戳大于上次轮询时间的数据。这会增加对数据库的查询压力,并且可能会导致一定的延迟。
3、不支持删除场景:基于查询的增量同步只能捕获到新增和更新的数据,无法捕获删除操作。如果需要同步删除操作,仍然需要使用CDC或其他方式来捕获数据库的日志。
总体而言,基于查询的增量同步可以在某些场景下使用,但相比于使用CDC,它可能会增加查询压力和延迟,并且无法捕获删除操作。如果需要更精确、高效、全面的增量数据同步,推荐使用CDC等基于日志的方式来实现。
楼主你好,阿里云Flink CDC可以基于查询做同步,不仅可以基于日志做增量同步,而且可以根据记录的时间戳做增量同步。具体实现步骤如下:
在Flink CDC配置中,启用“启用查询模式”选项。
配置查询语句,指定需要同步的表和列。例如:
SELECT id, name, age FROM my_table WHERE update_time > ${last_commit_timestamp}
其中,${last_commit_timestamp} 是Flink CDC内置的变量,代表上一次同步操作的时间戳。这个变量在每次同步时会被替换为上一次同步操作的时间戳。
通过上述步骤配置后,Flink CDC会定期执行查询语句,从源数据表中读取符合条件的数据,并将数据同步到目标系统中。需要注意的是,由于基于查询做同步无法像日志一样支持数据删除操作,因此需要在源表中禁止删除操作,或者在同步到目标系统时忽略删除操作。
是的,Flink CDC 可以基于查询进行增量同步,而不依赖于日志。这种方式被称为基于时间戳的增量同步,它通过在源表上运行查询来获取指定时间戳之后的变更数据。
基于时间戳的增量同步通常适用于不考虑删除场景的情况,因为查询只能获取到存在的记录,并不能获取已被删除的记录。
要实现基于查询的增量同步,您可以使用 Flink Table & SQL API 的功能来定义流处理作业。以下是实现的一般步骤:
在作业中创建源表:使用 Flink Table API 或 Flink SQL 定义源表,将源数据库中的表映射为 Flink 中的表结构。
执行查询:使用 Table API 或 SQL 查询语句来选择特定时间戳之后的记录。例如,可以使用 WHERE 子句和大于(>)操作符来过滤出变更时间大于给定时间戳的记录。
将结果写入目标表:使用 Flink 提供的连接器或自定义的输出格式将查询结果写入目标数据库表。
需要注意的是,基于查询的增量同步需要对源表的结构和数据进行适当的处理和转换。您可能需要根据目标表的结构进行投影、过滤、类型转换等操作,以确保同步的数据格式一致性。
此外,还需要考虑如何处理并发更新和事务处理。例如,如果在同一时间戳下同时存在多条变更记录,您可能需要定义合适的策略来处理冲突或选择合适的数据。
请注意,实现基于查询的增量同步需要考虑到具体数据库的特性和限制,以及 Flink Table & SQL API 的功能和语法。因此,查阅相关文档、示例和社区资源将有助于更好地理解和实现这种模式的增量同步。
Flink CDC可以基于查询做同步,但是不建议使用查询来做增量同步,因为查询的性能较差,而且容易出现数据倾斜等问题。如果要基于查询做同步,建议使用Flink的snapshot功能,通过扫描全表快照来获取数据,然后再进行增量同步。
不过,如果你只需要做增量同步,而且不考虑删除的场景,可以使用Flink的snapshot功能来扫描全表快照,然后根据时间戳进行增量同步
Flink CDC 主要是基于日志的 Change Data Capture 技术,通过解析数据库的日志来捕获数据的增量变化。它可以实现高效的增量数据同步和流式处理。
然而,如果你希望基于查询而不是日志做增量同步,并根据记录的时间戳进行增量同步(不考虑删除场景),Flink CDC 并不直接支持这种方式。因为基于查询的增量同步需要实时或定期地轮询查询变化的数据,而这种方式可能对数据库造成较大的负载,并且不能像日志捕获方式那样高效和实时。
对于使用查询的增量同步需求,一种常见的做法是使用数据库本身的特性,如触发器(Triggers)或者数据库的事件监听机制,来捕获记录的变化并进行同步。你可以根据数据库的具体特性和功能,设计触发器或者事件监听器,监控变化的数据,并将其发送到 Flink Job 进行处理和同步。
需要注意的是,基于查询的增量同步对数据库的负载和性能影响较大,需要谨慎考虑和评估。同时,你还需要自行实现查询逻辑和数据捕获机制,这可能需要编写定制化的代码和逻辑。
Flink CDC 目前主要是基于日志(如 MySQL 的 binlog、PostgreSQL 的 WAL)进行数据同步的,可以实现增量数据的捕获和传输。但对于基于查询的增量同步,Flink CDC 目前并不直接支持。
基于查询的增量同步是一种将数据库中已有的数据与查询条件结合,根据记录的时间戳或其他标识来获取增量数据的方式。这种方式通常需要借助数据库的功能或自定义逻辑来实现。
如果你想实现基于查询的增量同步,可以考虑以下两种方法:
使用数据库的功能:某些数据库提供了类似于 Oracle 的 Change Data Capture(CDC)或 PostgreSQL 的逻辑复制机制,可以根据记录的时间戳或其他标识获取增量数据。你可以通过配置和使用这些功能来实现增量数据的捕获,并将其发送到 Flink 进行处理。
自定义逻辑:如果数据库没有提供相应的功能,你可以编写自定义的逻辑来实现基于查询的增量同步。例如,你可以定期执行查询语句,根据指定的时间戳或其他标识获取增量数据,并将其发送到 Flink 进行处理。
是的,Flink CDC支持基于查询做同步,也支持根据记录的时间戳做增量同步。您可以在Flink CDC的配置文件中,指定查询语句和增量同步的参数,以实现数据同步。
需要注意的是,基于查询做同步的方式,可能会导致数据同步速度较慢,因为Flink CDC需要从源数据库中读取所有符合查询条件的数据,并将其写入目标数据库中。同时,如果您的源数据库中存在删除的数据,那么这些数据也会被写入目标数据库中,可能会导致数据不一致的问题。
因此,如果您的数据量较大,或者您的源数据库中存在删除的数据,那么建议您使用增量同步的方式,以优化数据同步速度和数据一致性。

