
Seata全局锁超时出现场景是什么?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
Seata全局锁超时可能出现在以下场景:
全局锁超时是指在 Seata 管理的全局事务中,尝试获取全局锁失败并最终超时的情况。这种情况可能由以下几个场景引起:
资源竞争:当多个全局事务并发访问同一资源(比如同一行数据)时,可能会发生锁竞争。如果一个事务持有了锁,其他事务就必须等待直到锁被释放,这可能导致超时。
事务执行时间过长:如果一个全局事务执行的时间过长,其他事务在尝试获取同一资源的锁时,可能会因为等待时间过长而超时。
网络延迟:在分布式系统中,网络延迟可能导致锁请求的传输和响应变慢,从而引起超时。
锁配置不当:Seata 允许配置锁的超时时间。如果这个配置设置得太短,就可能导致在正常的事务处理时间内无法获取锁而超时。
死锁:虽然 Seata 设计了机制来避免死锁,但在复杂的分布式事务场景中,死锁仍然有可能发生,这可能导致锁超时。
系统负载过高:在系统负载非常高的情况下,数据库操作可能会变慢,导致获取锁的时间变长,从而引发超时。
服务异常:如果参与全局事务的某个服务异常,它可能无法释放已经持有的锁,其他事务在尝试获取这个锁时会超时。
超时问题一直是分布式应用中比较难解决的问题,我们无法准确知晓B服务是否执行以及其执行顺序。从数据的角度来看,这意味着B 账户的钱未必会被成功加起来。在服务化改造之后,每个节点仅获知部分信息,而事务本身需要全局协调所有节点,因此需要一个拥有上帝视角、能够获取全部信息的中心化角色,这个角色就是TC(transaction coordinator),它用于全局协调事务的状态。TM(Transaction Manager) 则是驱动事务生成提议的角色。但是,即使上帝也有打瞌睡的时候,他的判断也并不总是正确的,因此需要一个RM(resource manager) 角色作为灵魂的代表来验证事务的真实性。这就是TXC 最基本的哲学模型。我们从方法论上验证了它的数据一致性是非常完备的,当然,我们的认知是有边界的。也许未来会证明我们是火鸡工程师,但在当前情况下,它的模型已经足以解决大部分现有问题。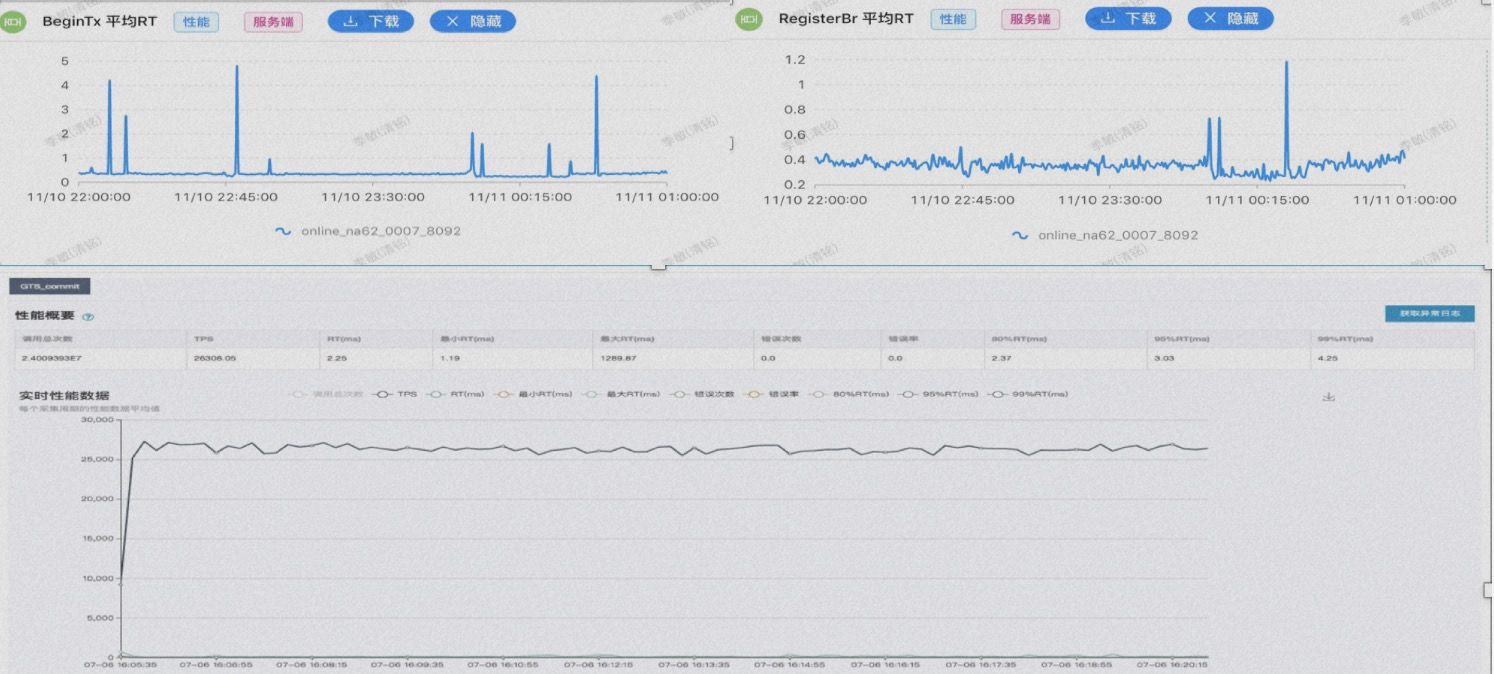
——参考链接。
Seata全局锁超时可能出现的场景主要有以下几类:
分布式事务中有一方或多方宕机导致长时间占用锁资源,超出全局锁超时时间。
业务处理逻辑有错误导致事务未正常提交也未回滚,锁持久化时间过长。
高并发场景下,锁表的加锁与解锁响应速度无法跟上事务请求速度。
分布式事务参与者处理能力不足,有大量任务在排队等待,延长全局处理时间。
配置的全局锁超时时间设置得过短,无法完成正常的事务逻辑流程。
业务逻辑中有阻塞等待比如IO等操作,导致整个事务时间过长。
分布式环境延时高,网络不稳定可能造成消息确认超时问题。
SeataServer或注册中心单点故障导致无法解锁持有的资源。
Seata 全局锁超时的出现场景主要是在分布式事务中,当多个事务同时访问同一个数据资源时,为了保证数据的一致性和隔离性,Seata 会使用全局锁来对资源进行加锁保护。如果一个事务在获取全局锁后,在规定的锁等待时间内没有完成对资源的操作,那么全局锁就会超时,导致其他等待访问该资源的事务无法继续执行。
具体来说,Seata 全局锁超时的场景包括但不限于以下情况:
系统负载过高:当系统负载过高,导致事务处理速度变慢时,可能出现全局锁超时的现象。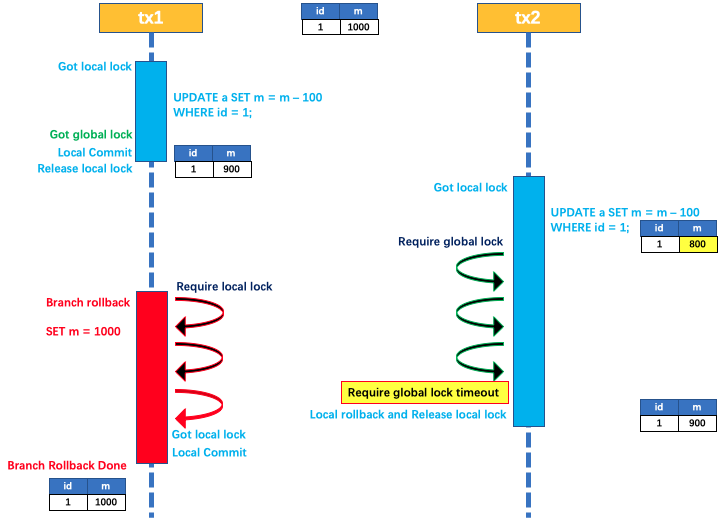
资源竞争激烈:当多个事务竞争同一个资源时,如果其中一个事务获取全局锁后长时间未完成操作,可能导致全局锁超时。
为避免 Seata 全局锁超时的出现,可以采取以下措施:
Seata全局锁超时通常出现在以下场景:
分布式事务中的多个节点同时对同一资源进行操作,导致资源竞争,进而引发全局锁超时。
分布式事务中的某个节点由于网络延迟、系统负载等原因无法及时响应,导致全局锁等待超时。
分布式事务中的某个节点出现故障或异常,无法释放全局锁,导致其他节点等待超时。
为了解决Seata全局锁超时问题,可以采取
以下措施:
优化业务代码,避免多个节点同时对同一资源进行操作,减少资源竞争。
调整全局锁的并发级别和超时时间,避免长时间等待。
增加更多的服务器节点,提高系统的并发能力,减少节点故障或异常对全局锁的影响。
对异常情况进行监控和预警,及时发现并处理问题。
Seata全局锁超时可能出现以下场景:
在 Seata 中,全局锁超时可能会在以下场景中出现:
高并发事务:当系统中存在大量的并发事务并且这些事务都需要获取相同资源(如数据库行、表等)的锁时,由于竞争激烈,可能导致全局锁超时。这可能是因为某些事务占用锁的时间过长,导致其他事务无法及时获取到锁。
事务执行时间过长:如果某个事务的执行时间非常长,超出了 Seata 设置的全局锁超时时间,那么该事务可能会被强制回滚并释放锁,从而导致全局锁超时。
锁冲突:如果多个事务尝试同时获取相同资源的锁,并且存在锁冲突(如读-写冲突或写-写冲突),则可能导致全局锁超时。例如,一个事务正在进行写操作,而另一个事务正试图以写模式获取同一资源的锁。
锁粒度太细:如果对于某个资源,锁的粒度设置得过细,导致锁的竞争过于频繁,可能会增加全局锁超时的风险。在设计分布式事务时,需要谨慎考虑锁的粒度和并发性。
为了避免全局锁超时的出现,可以采取一些措施:
Seata全局锁超时主要出现在以下场景: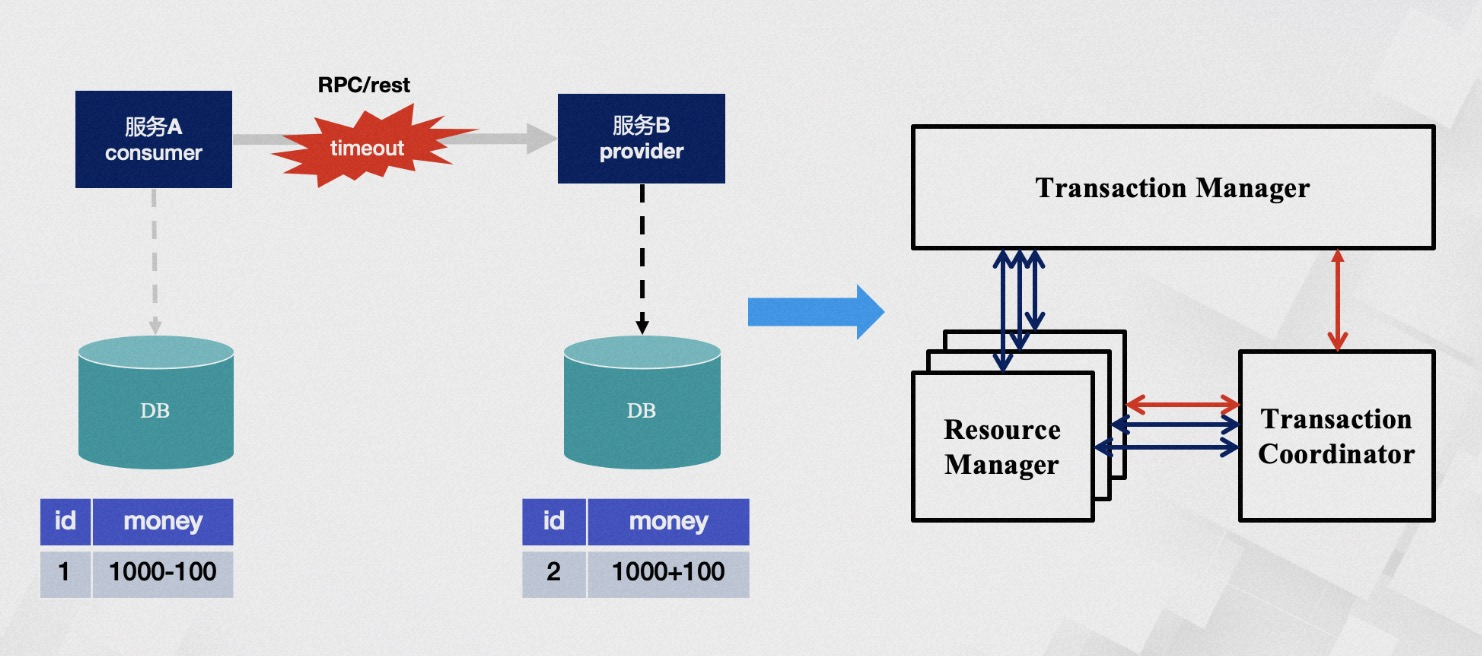
全局锁超时可能出现在以下场景:当多个事务并发执行,并且这些事务都需要对同一行数据进行修改,Seata的全局锁模式就会触发。如果其中一个事务长时间无法获取到全局锁,那么其他事务就需要等待,直到超时。例如,在一些业务场景下,如订单创建和库存扣减,这两个操作都需要对数据库同一笔数据进行修改,如果使用Seata的AT模式,可能会因为全局锁的争用导致某些操作失败。
阿里云拥有国内全面的云原生产品技术以及大规模的云原生应用实践,通过全面容器化、核心技术互联网化、应用 Serverless 化三大范式,助力制造业企业高效上云,实现系统稳定、应用敏捷智能。拥抱云原生,让创新无处不在。

