
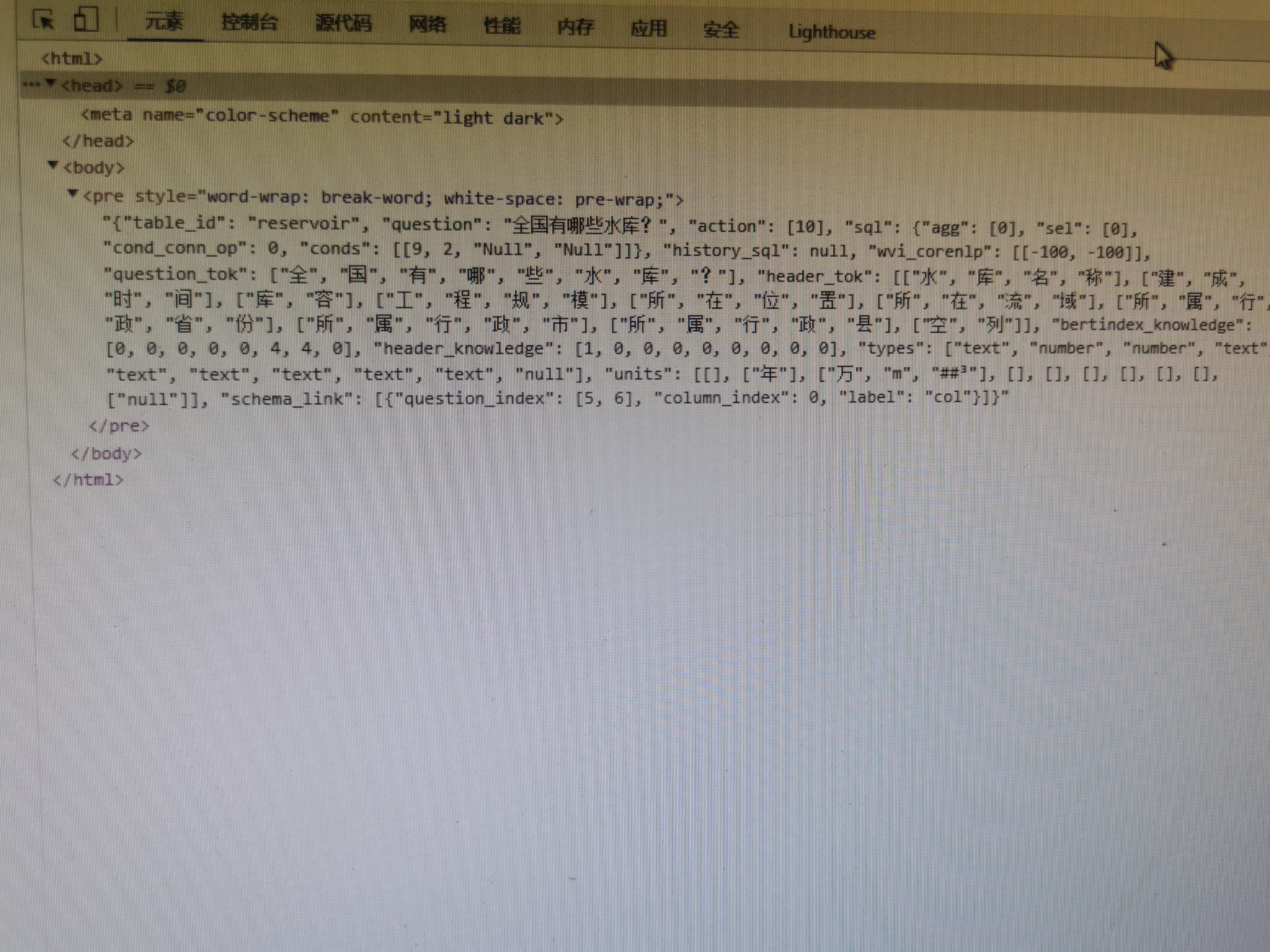
 问一下大佬这个text2sql 数据集是怎么构建的?
问一下大佬这个text2sql 数据集是怎么构建的?
text2sql 数据集的构建通常涉及将自然语言问题转换为对应的结构化SQL查询的过程,以实现对数据库的操作。虽然直接提供的参考资料中没有详尽介绍text2sql数据集的具体构建方法,但我们可以根据相关知识和通用步骤来概述其构建流程:
定义领域与数据源:
收集自然语言问题:
手动或半自动标注SQL查询:
数据清洗与验证:
划分数据集:
元数据与说明文档:
发布与共享:
综上所述,text2sql数据集构建是一个涉及领域知识、数据处理、编程技能及法律合规等多方面考量的复杂过程,旨在为机器学习模型提供丰富的训练资源,以实现自然语言到结构化查询的精准转换。
ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!欢迎加入技术交流群:微信公众号:魔搭ModelScope社区,钉钉答疑群:44837352
