
问题描述
当我在spark中调取fastjson2解析字段时并转换为自定义对象时,getString不知道为什么爆出oom
环境信息
OS信息: Centos7 JDK信息: 1.8.0_202 版本信息:Fastjson2 2.0.4
重现步骤
spark在map中使用fastjson2,getString解析对应字段时爆出oom
相关日志输出
java.lang.OutOfMemoryError at com.alibaba.fastjson2.JSONWriterUTF16JDK8.writeString(JSONWriterUTF16JDK8.java:77) at com.alibaba.fastjson2.writer.ObjectWriterImplMap.write(ObjectWriterImplMap.java:351) at com.alibaba.fastjson2.writer.ObjectWriterImplList.write(ObjectWriterImplList.java:254) at com.alibaba.fastjson2.writer.ObjectWriterImplMap.write(ObjectWriterImplMap.java:380) at com.alibaba.fastjson2.writer.ObjectWriterImplMap.write(ObjectWriterImplMap.java:380) at com.alibaba.fastjson2.JSON.toJSONString(JSON.java:925) at com.alibaba.fastjson2.JSONObject.getString(JSONObject.java:281) at com.ishumei.warehouse.dwd.DwdSqMainDiV2$$anonfun$sparkRun$1$$anonfun$apply$1.apply(DwdSqMainDiV2.scala:50) at com.ishumei.warehouse.dwd.DwdSqMainDiV2$$anonfun$sparkRun$1$$anonfun$apply$1.apply(DwdSqMainDiV2.scala:27) at scala.collection.Iterator$$anon$11.next(Iterator.scala:410) at scala.collection.Iterator$$anon$11.next(Iterator.scala:410) at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIteratorForCodegenStage3.sort_addToSorter_0$(Unknown Source) at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIteratorForCodegenStage3.processNext(Unknown Source) at org.apache.spark.sql.execution.BufferedRowIterator.hasNext(BufferedRowIterator.java:43) at org.apache.spark.sql.execution.WholeStageCodegenExec$$anonfun$11$$anon$1.hasNext(WholeStageCodegenExec.scala:624) at org.apache.spark.sql.execution.aggregate.SortAggregateExec$$anonfun$doExecute$1$$anonfun$3.apply(SortAggregateExec.scala:80) at org.apache.spark.sql.execution.aggregate.SortAggregateExec$$anonfun$doExecute$1$$anonfun$3.apply(SortAggregateExec.scala:77) at org.apache.spark.rdd.RDD$$anonfun$mapPartitionsWithIndexInternal$1$$anonfun$12.apply(RDD.scala:823) at org.apache.spark.rdd.RDD$$anonfun$mapPartitionsWithIndexInternal$1$$anonfun$12.apply(RDD.scala:823) at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52) at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:324) at org.apache.spark.rdd.RDD.iterator(RDD.scala:288) at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52) at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:324) at org.apache.spark.rdd.RDD.iterator(RDD.scala:288) at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:99) at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:55) at org.apache.spark.scheduler.Task.run(Task.scala:121) at org.apache.spark.executor.Executor$TaskRunner$$anonfun$11.apply(Executor.scala:407) at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1408) at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:413) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) at java.lang.Thread.run(Thread.java:748)
最后定位到:
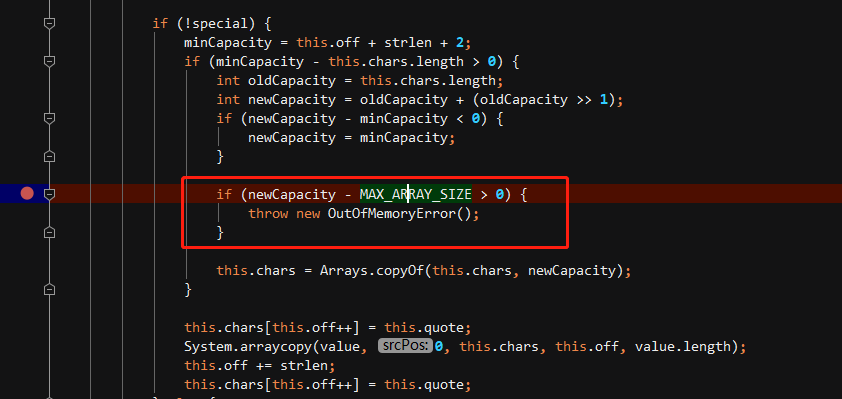

是数据的字符串超出了最大限制吗?
原提问者GitHub用户meimiao0730
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在2.x版本中,ReferenceDetection是缺省关闭的,你需要显式打开。
JSON.toJSONString(obj, JSONWriter.Feature.ReferenceDetection)
更多的Feature,你可以看这里
https://github.com/alibaba/fastjson2/blob/main/docs/features_cn.md
原回答者GitHub用户wenshao