
 机器学习中读oss数据,是读文件,还是只是输出oss的文件路径?我试了一下,它的输出只是文件路径而已,没有输出文件的内容
机器学习中读oss数据,是读文件,还是只是输出oss的文件路径?我试了一下,它的输出只是文件路径而已,没有输出文件的内容
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
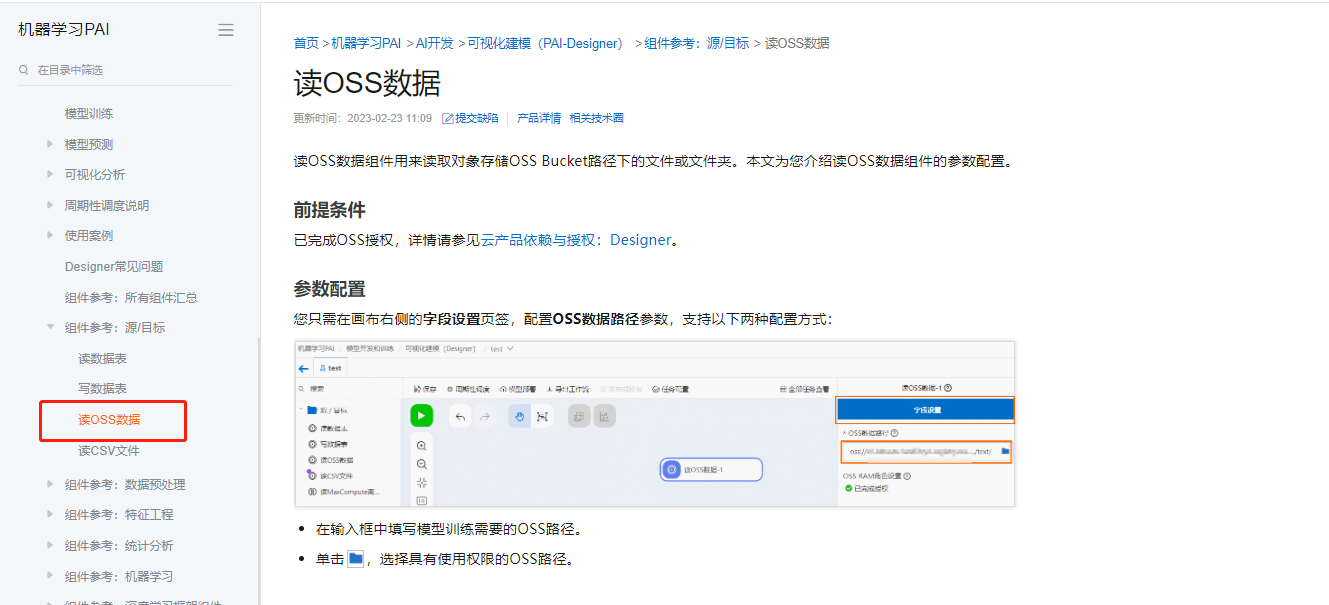
阿里云机器学习PAI可以通过读取OSS文件的方式获取数据,并对数据进行分析和处理。
在PAI中,通常会使用OSS URI(Uniform Resource Identifier)指定要读取的OSS文件路径。因此,PAI会直接从OSS中读取文件内容,而不是只输出文件路径。
具体来说,您只需要在PAI作业的配置中指定OSS URI,并使用相应的数据引擎(例如TensorFlow、PyTorch等)来读取数据即可。
以下是一个使用TensorFlow读取OSS文件的示例代码:
import tensorflow as tf
image_uri = 'oss://your-bucket/your-path/image.jpg'
image_data = tf.keras.utils.get_file('image.jpg', image_uri)
image = tf.io.decode_jpeg(image_data, channels=3) # 解码JPEG文件为Tensor
在上述示例中,get_file()方法可以自动从image_uri指定的OSS文件路径中下载文件,并返回文件内容。然后,可以使用decode_jpeg()方法解码JPEG文件,最终得到一个Tensor对象。
机器学习读取OSS数据是根据提供的OSS文件路径读取文件内容数据,读取或者写入数据到OSS,指的就是读取指定文件路径下的文件本身的数据内容哈。
是的,这个需要搭配其他组件使用,运行的oss这个节点会把路径传给下游组件,下游组件根据路径读取数据,此回答整理自钉群“机器学习PAI交流群(答疑@值班)”
在机器学习中,通常需要读取OSS中的数据进行训练和预测。一般来说,读取OSS中的数据需要先获取文件路径,然后再进行读取。因为OSS是一种对象存储服务,不同于传统的文件系统,它把数据以对象的形式存储,每一个对象都有一个唯一的Object Key,类似于文件路径。所以在读取OSS数据时,需要先根据Object Key获取文件路径,然后再进行读取操作。通常,数据量较大的情况下,我们会使用分布式的方式读取数据,以提高读取效率。
人工智能平台 PAI(Platform for AI,原机器学习平台PAI)是面向开发者和企业的机器学习/深度学习工程平台,提供包含数据标注、模型构建、模型训练、模型部署、推理优化在内的AI开发全链路服务,内置140+种优化算法,具备丰富的行业场景插件,为用户提供低门槛、高性能的云原生AI工程化能力。



