
基于自然语言推理的零样本分类模型:StructBERT零样本分类-中文-base。
基于文本生成的零样本分类模型:全任务零样本学习-mT5分类增强版-中文-base。
为了更直观地体现零样本分类模型在低资源场景下的优势,下面我们先来看一个实际案例。
实际案例——工单分类
一些在线平台每天都会产生大量的问题工单,产研同学需要对这些工单进行归类和分析,进而定位问题、了解变化趋势并优化产品。由于产品的变化较快,因此产品的分类体系需要灵活调整,人工打标的方式无法满足日常的工单分析需求,费时费力。基于modelscope开源社区开放的领先算法模型,我们针对工单分类的需求,研发了分类算法,旨在帮助产研团队针对工单内容实现自动化归类,进而提升工单处理和产品迭代的效率。
在解决工单分类任务中,遇到的主要难点有:
业务方初期可投入的人力资源有限。
有效的标注数据很少,存在平均每个类别只有不到10个样本的情况。
常规的分类算法得到的模型效果非常之差,难以满足基本使用需求。
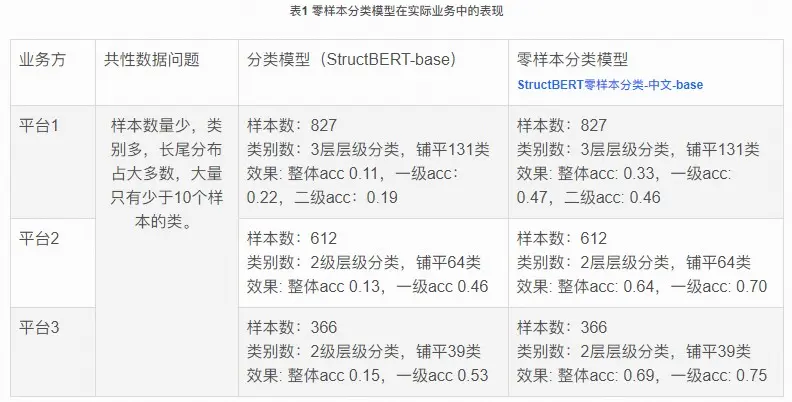
针对上述难点,我们选择了采用零样本分类模型进行算法的构建。通过零样本文本分类模型高质量建模工单文本与各个标签文本的相关性,再将预测结果进行整合排序,最终得到与工单文本最相关的标签。实验结果如下表所示,在3个低资源的工单分类任务上,该模型相较于普通分类模型均取得了明显的提升,其中:
平台1:整体准确率从0.11提升至0.33,一级类别准确率从0.22提升至0.47,二级类别准确率从0.19提升至0.46。
平台2:整体准确率从0.13提升至0.64,一级类别准确率从0.46提升至0.70。
平台3:整体准确率从0.15提升至0.69,一级类别准确率从0.53提升至0.75。
前言
零样本学习(Zero-Shot Learning)是一种机器学习范式,它使用在训练阶段从未学习过的样本和类别标签来测试模型。因此,零样本学习的模型应当具备一定的对从未学习过的分类任务直接进行预测的能力。机器学习(Machine Learning)已经在各个领域取得了广泛的应用,而其中分类是最基础的机器学习任务,它需要分析未分类数据,并确定如何将其归属到已知类别中。通常分类任务需要大量已知类别的数据来构建和训练模型,然而获取任何特定任务、特定领域的已标注数据都是一个非常昂贵且耗时的过程,这使得零样本学习最近变得越来越流行。
文本分类(Text Classification)是自然语言处理(NLP)领域中的一种任务,它指的是将文本数据(如新闻文章、电子邮件或社交媒体帖子)自动分配到一个或多个预定义的类别(如政治、体育、娱乐等)中。这可以通过训练机器学习模型来实现,该模型可以根据文本的词汇、语法等特征来预测它的类别。
零样本文本分类(Zero-Shot Text Classification)是一种文本分类方法,其优势在于它不需要任何预先标记的训练样本来分类文本。 这意味着,即使在缺乏预先标记的数据的情况下,也可以对文本进行分类。传统的文本分类方法需要大量预先标记的训练样本来训练模型,但在实际应用中,很难收集到足够的预先标记的样本。 因此,零样本文本分类可以作为一种替代方案,以便在缺乏预先标记的数据的情况下进行文本分类。图1展示了零样本分类的测试效果,从图中不难发现,零样本分类模型可以支持标签的自定义,从而使得可以对任何文本分类任务进行推理。
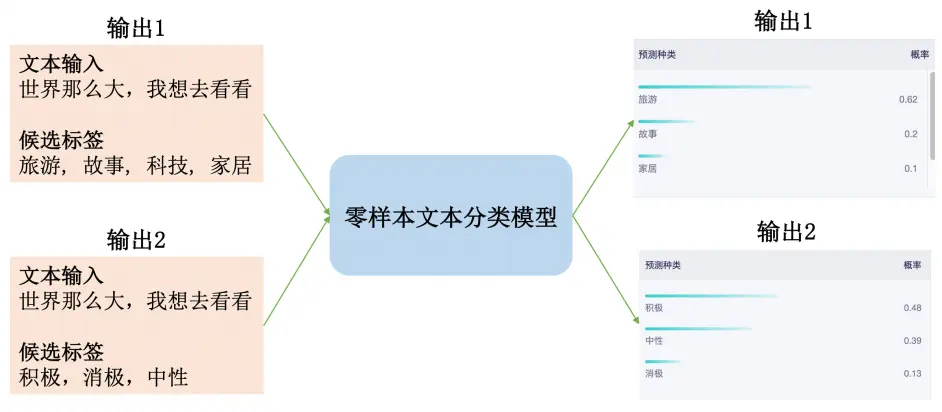
图1 零样本分类模型用例测试
常见的零样本分类模型主要可以分为以下两类。
基于自然语言推理的模型
模型特点:在训练阶段仅使用NLI相关数据集进行训练,在进行零样本分类时,需要将样本转换成nli样本形式。
模型优势:进行推理时,在各种分类任务上的表现比较均衡,受到训练数据的影响较小,分类结果稳定。
模型缺点:每次推理时都需要推理n个样本(其中n为标签数量),模型推理时间随标签数量线性增长。
基于文本生成的模型
模型特点:需要设计prompt来结合文本和标签,让模型生成文本对应的标签。
模型优势:推理效率较高,每次推理只需要推理1个样本。
模型缺点:由于是生成模型,生成的结果可能不稳定,即生成的文本不存在与候选标签中。同时该模型在训练时使用了大量文本分类数据集进行训练,因此在不同分类任务上表现出的性能可能存在较大差异。
下面我们将对这两个模型分别进行介绍。
基于自然语言推理的零样本文本分类模型
该系列模型基于StructBERT[1]在xnli_zh数据集(将英文数据集重新翻译得到的中文数据集)上面进行训练得到。
自然语言推理(Natural Language Inference, NLI)是指利用自然语言的语法和语义知识来判断一个给定的文本片段(如两个句子)的关系,例如它们是否是矛盾、是否相关或是否是一个是另一个的后续。而使用预训练的自然语言推理模型来实现零样本分类的方式,如图2所示,是将要分类的文本设置为自然语言推理的前提,然后使用每个标签构建一个假设,接着对每个假设进行推理得到文本所属的标签,即去判断给定文本片段与给定的标签之间的关系。
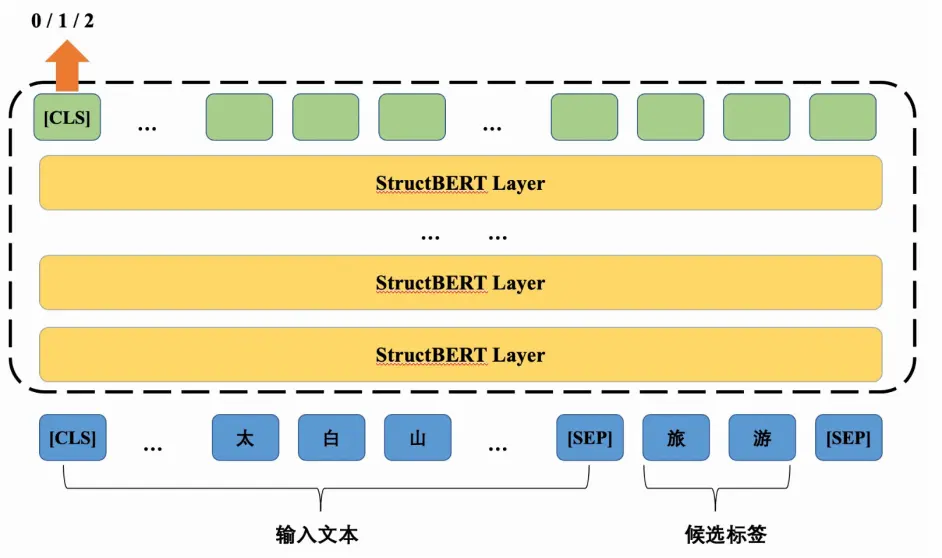
图2 基于NLI的零样本分类模型图
模型测试
实验环境准备
依据ModelScope的介绍,实验环境可分为两种情况。笔者在此推荐使用第2种方式,点开就能用,省去本地安装环境的麻烦,直接体验ModelScope。
1 本地环境安装
可参考ModelScope环境安装。
2 Notebook
ModelScope直接集成了线上开发环境,用户可以直接在线训练、调用模型。
打开零样本分类模型,点击右上角“在Notebook中打开”,选择机器型号后,即可进入线上开发环境。
实验测试
(注:下面使用的样本及其获选标签,模型在训练过程中从未学习过。)
加载模型
使用以下两行命令即可进行零样本分类的模型加载。
from modelscope.pipelines import pipeline
classifier = pipeline('zero-shot-classification', 'damo/nlp_structbert_zero-shot-classification_chinese-base')
运行后,ModelScope自动将指定的模型下载至缓存目录中。
设置标签
与一般的文本分类模型不同,零样本分类模型可以自己设定对应的标签,模型将根据给定的标签进行分类。此处我们先将文本标签设置如下。
labels = ['家居', '旅游', '科技', '军事', '游戏', '故事']
进行分类
接着输入文本,并使用pipeline进行分类。
sentence = '世界那么大,我想去看看'
classifier(sentence, candidate_labels=labels)
最后,我们得到了以下结果:
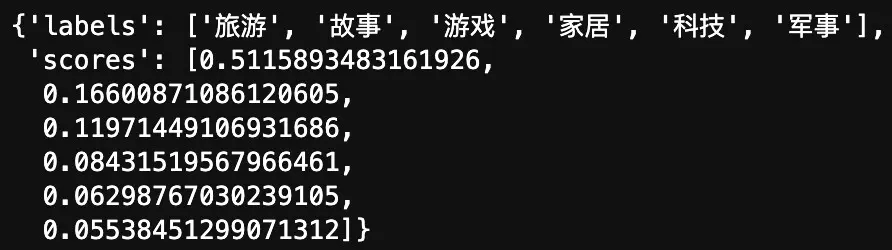
从返回的结果中,可以发现样本属于旅游的概率远大于其他类别。即模型认为输入'世界那么大,我想去看看',在标签体系 ['家居', '旅游', '科技', '军事', '游戏', '故事'] 中应当属于旅游类别。
多标签分类
零样本分类模型除了能解决多分类问题之外,还能解决多标签分类问题。
上述分类中,我们还有一个参数没有用到,即multi_label。从零样本分类模型的介绍中可以发现,这个参数是用于设置分类任务是否为多标签分类的。接着,我们也来尝试一下多标签分类任务。首先,设置标签如下:
labels = ["不开心", "不高心", "高兴", "开心"]
接着输入文本,并使用pipeline进行分类,并设置multi_label=True。
sentence = '世界那么大,我想去看看'
result = classifier(sentence, candidate_labels=labels, multi_label=True)
最后我们得到了以下结果。
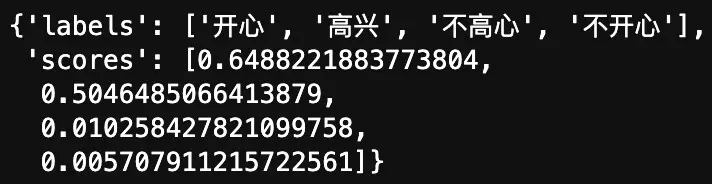
其中scores代表的是每个标签的概率,预测结果可以认为是开心和高兴,因他们的概率大于0.5。
模型原理
基于NLI的零样本分类模型主要是应用了NLI模型的推理能力,它将获选标签逐一与待分类文本结合,构建成句子对的样本形式后,再对每个样本进行推理判断两者之间的关系,最后再将每个样本的预测结果进行结合根据其相关性的概率进行分类。
自然语言推理
该零样本分类模型在训练时只使用了自然语言推理相关的数据集,并未使用任何文本分类数据集进行训练。
自然语言推理主要是判断两个句子(前提和假设,Premise and Hypothesis)之间的语义关系,一般定义有(Entailment, Contradiction, Neutral)三个类别,可以当成是一个三分类任务。下面举了3个例子让大家切实感受一下自然语言推理任务。
自然语言推理举例
前提:中间坐着的修鞋匠,就是张永红的父亲
假设:修鞋匠是女的
语义关系:Contradiction(矛盾)
解释:张永红的父亲,当然是男的!
前提:中间坐着的修鞋匠,就是张永红的父亲
假设:修鞋匠是男的
语义关系:Entailment(蕴含)
解释:张永红的父亲是男的,所以前提句子中已经包含了假设句的语义。
前提:中间坐着的修鞋匠,就是张永红的父亲
假设:张永红是男的
语义关系:Neutral(中立)
解释:前提和假设并没有关系。
零样本分类
那么如何基于自然语言推理进行零样本分类任务呢?
通过研读模型零样本分类模型中给出的论文,再结合对ModelScope源码的调试,我们可以发现,答案其实很简单。只要依次将每个的标签当成假设,输入的文本当成前提,进行自然语言推理任务之后,再对所有标签的预测结果进行处理,即可实现零样本分类。
设置三个标签:家居,旅游,科技
输入文本:世界那么大,我想去看看
对以上输入进行零样本分类的时候,将生成以下三个自然语言推理任务的样本:
1. 前提:世界那么大,我想去看看,假设:家居
2. 前提:世界那么大,我想去看看,假设:旅游
3. 前提:世界那么大,我想去看看,假设:科技
对三个样本进行自然语言推理的预测之后,最后将预测结果进行整合,即可实现零样本分类任务。例如多分类任务中,可以将“前提句”蕴含“假设句”概率最大的那个假设作为最后的标签。
本章小结
从模型原理的解析中可以发现基于自然语言推理的零样本文本分类模型在进行分类时,需要将候选标签逐一与文本进行结合生成对应的NLI的样本,这意味着有N个候选标签,就需要生成N个待推理样本。因此,该模型的推理效率可能较低,是一种用时间成本来获取更高准确率的方案。但该方案在抹零战役工单分类任务的低资源场景下,表现出了优异的性能。因此,在推理时间不敏感的低资源场景下的文本分类任务,该模型非常适用。
基于文本生成的零样本分类模型
该模型在mT5模型的基础上,使用3000万数据进行全中文任务的训练,支持各类任务的零样本/少样本学习,并引入了零样本分类增强的技术,使模型输出稳定性大幅提升。 模型特点:
零样本分类增强:该针对零样本分类输出不稳定的情况(即生成的内容不在所给的标签之中),进行了数据增强,在零样本分类稳定性评测中,该模型输出稳定性可达98.51%。
任务统一框架:把所有任务,如文本分类、相似度计算、文本生成等,都使用一个text-to-text的框架进行解决。
该模型除了支持零样本分类外,还可以支持其他任务的零样本学习。支持任务包含:
文本分类:给定一段文本和候选标签,模型可输出文本所属的标签。
自然语言推理:给定两段文本,判断两者关系。
阅读理解:给定问题和参考文本,输出问题的答案。
问题生成:给定答案和参考文本,生成该答案对应的问题。
摘要生成:给定一段文本,生成该文本的摘要。
标题生成:给定一段文本,为其生成标题。
评价对象抽取:给定一段文本,抽取该段文本的评价对象。
翻译:给定一段文本,将其翻译成另一种语言。
T5全称是Text-to-Text Transfer Transformer,是一种模型架构或者说是一种解决NLP任务的一种范式。它的主要目标就是使用文本生成的方式来解决各种自然语言处理任务,例如机器翻译、摘要、问答等。T5通过使用一种统一的编码和解码方法来解决不同的任务,从而避免了为每个任务单独设计模型的问题,在训练过程中使用了大量的数据和计算资源,以便在比较小的数据集上训练任务特定的模型。并且在大型的数据集上进行了广泛的评估,在许多自然语言处理任务中表现出优越的性能。
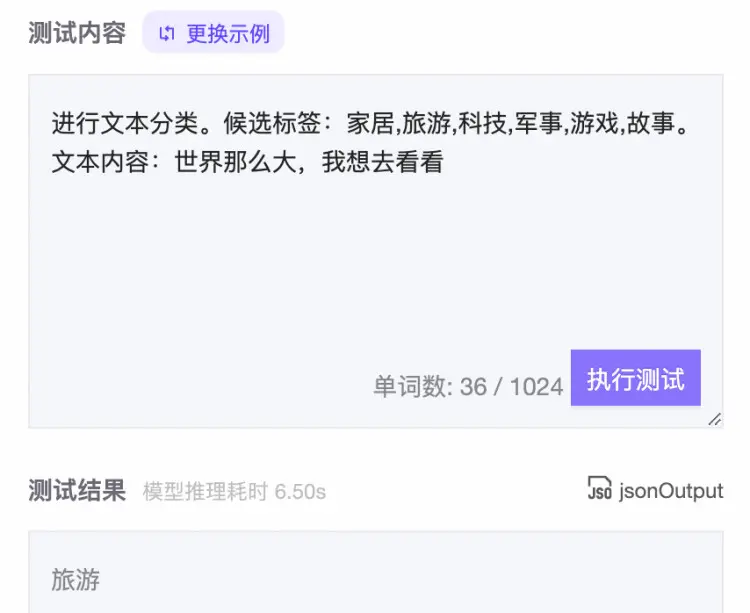
零样本文本分类
使用生成模型进行零样本分类的主要思路是将候选标签与待分类文本按照一定格式进行拼接后作为模型输入,期望模型可以输入文本所属的标签。图4展示了在ModelScope上进行测试的结果(该用例并未在训练过程中学习过)。
零样本分类增强
由于文本生成模型的输出具有一定的随机性,在使用基于文本生成的零样本学习模型进行零样本分类时,模型输出的结果可能并不在所给的候选标签之中,从而导致模型不可用。因此,我们使用了一种数据增强的方式来提升模型在零样本分类中的稳定性,并设计了零样本分类稳定性评测对模型分类的稳定性进行指标的量化。
零样本分类稳定性评测
评测方式
从40万条文本中随机挑选了1万条文本作为待分类文本,再为每条文本从130个标签库中随机挑选随机数量的标签作为候选标签,最后结合文本和候选标签得到评测数据集。
对于每个模型均使用其在训练时使用的prompt构建模型输入。如果模型最终的输出存在于候选标签中,则认为该模型在该样本上的预测稳定,否则认为模型不稳定。
评测结果
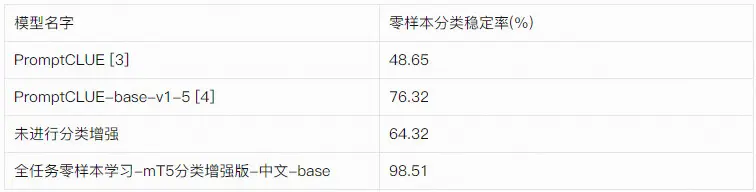
从评测结果中可以发现,经过零样本分类增强之后,该模型零样本分类稳定率从64.32提升到了98.51。
样例测试
测试流程
使用模型指定的prompt构建输入,进行第一次分类。
如果分类结果稳定,即输出的内容属于候选标签,那么将输出的标签从候选标签中剔除。
再次根据指定的prompt构建输入,进行分类。
重复步骤b和步骤c,直到分类结果不稳定或候选标签已清空。
测试用例
测试用例使用PromptCLUE中所给的demo用例。
待分类文本:如果日本沉没,中国会接收日本难民吗?
候选标签:故事,文化,娱乐,体育,财经,房产,汽车,教育,科技,军事,旅游,国际,股票,农业,游戏
测试结果
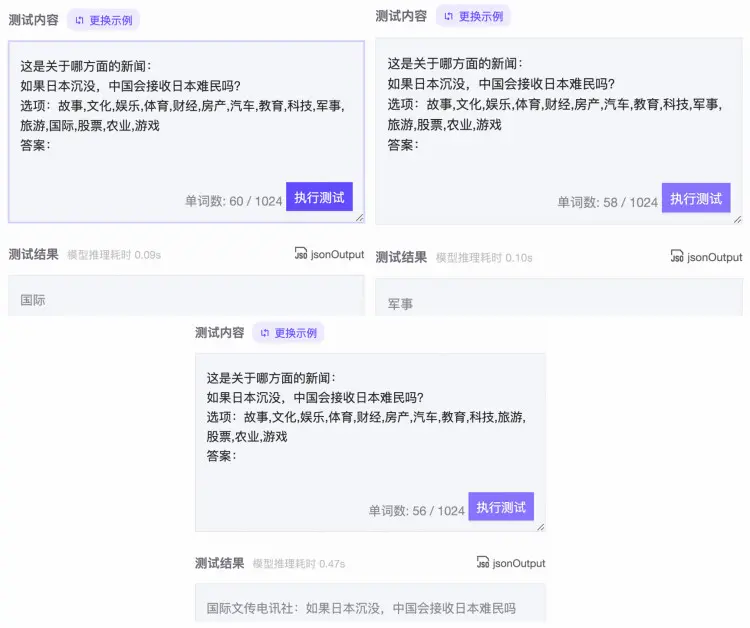
PromptCLUE测试结果
从测试结果中可以发现,Prompt CLUE在第3次分类时,已经出现了模型不稳定的情况。
全任务零样本学习-mT5分类增强版-中文-base
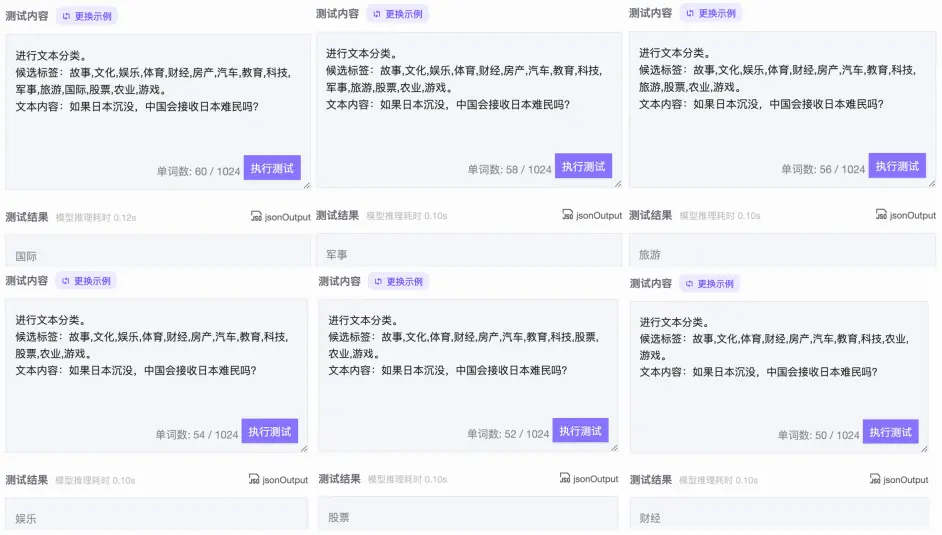
全任务零样本学习-mT5分类增强版-中文-base测试结果
在测试过程中,该模型可以一直保持输出稳定直到候选标签被完全清空。
零样本学习评测
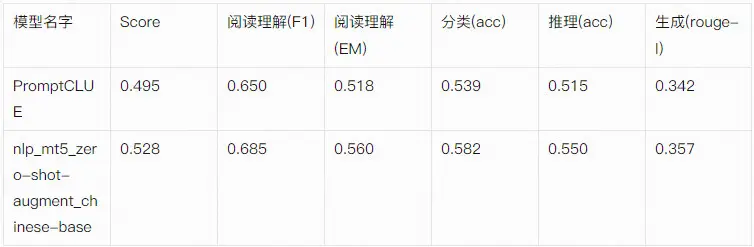
基于文本生成的零样本学习模型不仅支持零样本分类,同时还可以支持其他任务,如阅读理解、摘要生成、翻译等。因此,该模型选用了pCLUE[5]进行评测,同时与PromptCLUE进行了对比。整体评测结果如下:
本章小结
使用文本生成的方式实现零样本分类时,可以将所有候选标签进行结合,只需要生成一个样本进行分类。相比基于NLI的零样本分类模型,在推理效率上优势比较大。但该模型会带来了分类结果不稳定的问题,即输出的文本不存在于候选标签中。而全任务零样本学习-mT5分类增强版-中文-base通过一种数据增强的方式大幅提升了在文本分类场景下的稳定性,在零样本分类稳定性评测中表现出的准确率可达98.51%,远大于其他模型,但在稳定性方面依然不如基于nli的模型。因此,该模型适用于对推理时间较为敏感的低资源文本分类场景。
总结
本文主要介绍了两类可以用于零样本文本分类的模型。
a基于自然语言推理的零样本分类模型:适用于对模型推理时间不敏感的低资源文本分类场景,在抹零战役工单分类任务中,表现出了优异的性能。
b基于文本生成的零样本学习模型:适用于对模型推理时间要求较高的低资源本文分类场景,同时还能进行其他任务的零样本学习。而本文介绍的模型在分类场景下进行了特定的数据增强,大幅提高了分类的稳定性,相比于其他模型更加适合应用于零样本文本分类场景。
参考文献
[1] Wang W, Bi B, Yan M, et al. Structbert: Incorporating language structures into pre-training for deep language understanding[J]. arXiv preprint arXiv:1908.04577, 2019.
[2] Raffel C, Shazeer N, Roberts A, et al. Exploring the limits of transfer learning with a unified text-to-text transformer[J]. The Journal of Machine Learning Research, 2020, 21(1): 5485-5551.
[3]https://www.modelscope.cn/models/ClueAI/PromptCLUE/summary
[4]https://www.modelscope.cn/models/ClueAI/PromptCLUE-base-v1-5/summary
[5]https://github.com/CLUEbenchmar
作者:ModelScope官方账号 https://www.bilibili.com/read/cv21819582/ 出处:bilibili
你好,想问下可以对StructBERT零样本分类模型使用进行微调,以提升其在特定领域的分类效果么?如何可以数据集应该如何设置呢?我看本身使用的数据集包括premise (Value)、hypothesis (Value)、label (Value)这三个字段,不是很理解label的0,1,2是根据什么设定的。 谢谢!

