
本文介绍阿里达摩院NLP团队在垂直领域(地址文本、电商文本)NER的优化探索,相关工作发表于 COLING 2022:https://arxiv.org/pdf/2208.12995.pdf
**论文标题:**Domain-Specific NER via Retrieving Correlated Samples
代码链接:https://github.com/modelscope/AdaSeq/tree/master/examples/RaNER
基于大量有标注数据的有监督机器学习是目前命名实体识别 (Named Entity Recognition, NER) 技术的主流,但是这一范式可能会在某些特殊领域上遇到问题,比如地址文本上的NER。
下图展示了地址元素NER的一个例子,模型需要识别出给定地址文本中的 省-Prov, 市-City, 兴趣点-POI 等地址元素。在此例子中,模型错误的预测出了“白城镇”和“赉县火车站”,如果不知道正确答案“白城”和“镇赉县”的相关背景知识,即便是人来识别也会出现同样的错误,因为这是十分符合地址元素的常规模式的,即“XX镇”和“XX火车站”。
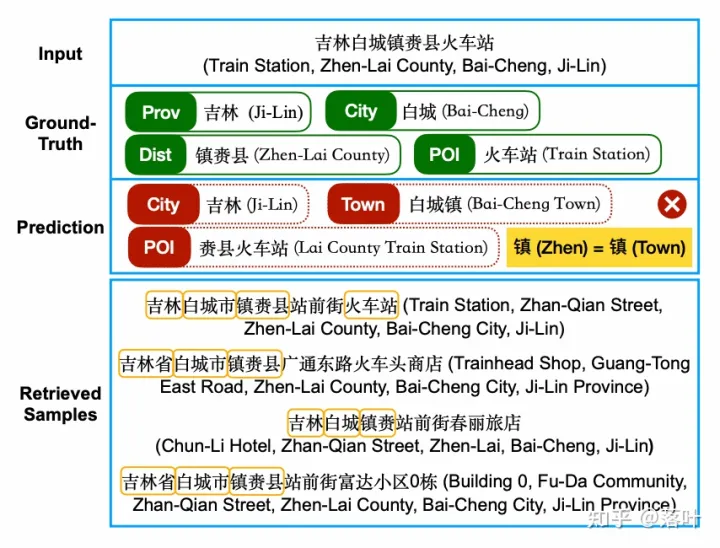
而如果我们能够获取到很多相似的样本补充信息,我们就可以从样本观察、归纳、总结出“白城”是一个市,“镇赉县”是一个县。
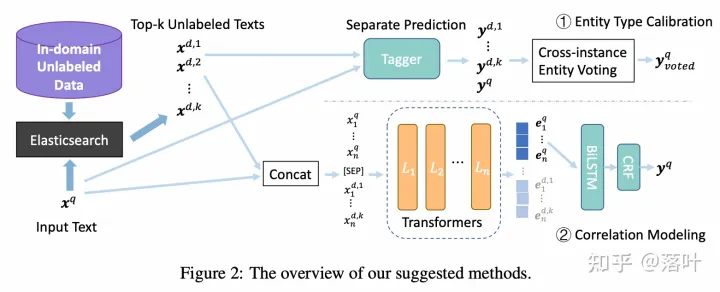
为了让模型也能建模和获取相似样本所蕴含的知识,我们使用 elasticsearch 为输入文本检索top k无标注相似样本,然后探索了两种建模方法。
最简单的一种方法就是,先平行的对所有相似样本,然后对相同的文本片段进行标签的多数投票,比如所有的“白城”的标签进行投票,大多数都是 city 标签,那么我们最终输入文本中的“白城”就是city。
针对地址领域的文本特性,我们在实体投票时,会将常用的后缀去除,也就是说“白城”和“白城市”是一起计算投票,这一trick很有效。
这种方法不需要重新训练模型,只需要对所有的文本进行预测,然后投票统计即可。
为了更进一步的在模型编码时捕捉相似样本所蕴含的信息,我们使用 cross-encoder 对输入文本和相似样本进行联合编码。
具体的,我们将输入文本和其多个相似样本拼接到一起,输入预训练语言模型提取特征编码,然后只保留输入文本的特征用于NER解码,相似文本的特征直接扔掉。
我们在 CCKS 2021 地址解析数据集 上进行实验,在内部的4亿无标注地址文本库上使用 elasticsearch 为每条有标注数据检索相似样本。
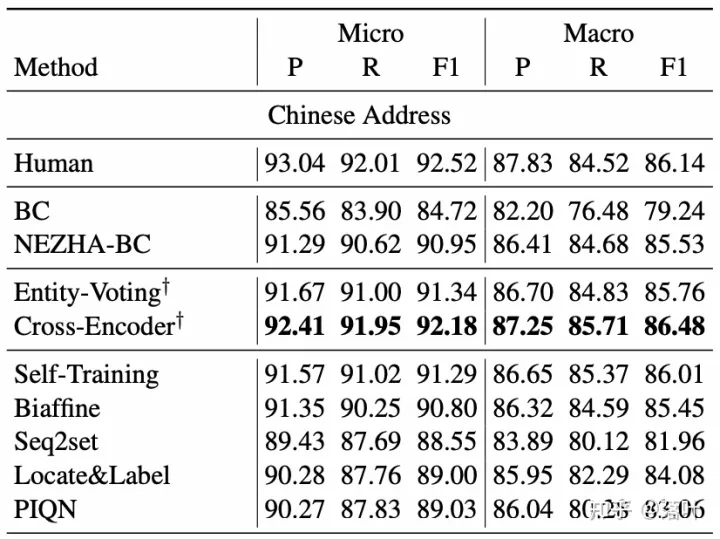
我们使用预训练模型 NEZHA 和 BiLSTM-CRF 模型 作为 baseline 结构,详细参数设置请参见论文3.1节。实验结果见下表,可以看到基于相似样本的实体投票 (Entity-Voting) 可以相比基线模型 (NEZHA-BC) 有一定提升,而基于相似样本的 Cross-Encoder 建模能进一步提升性能。
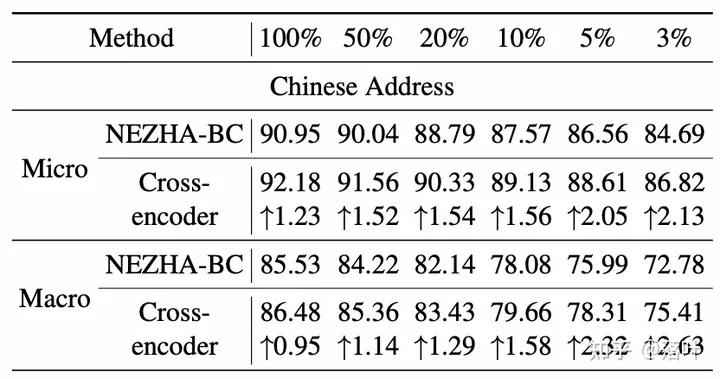
我们也对最有效的 Cross-Encoder 方法进行了更多实验,比如随机采样50%,10%等比例的训练数据,模拟低资源场景,发现训练数据越少,提升越多。另外类似的,拼接的相似样本越多,提升越多。
基于相同的技术,我们也在电商NER数据上进行了实验,同样有效。
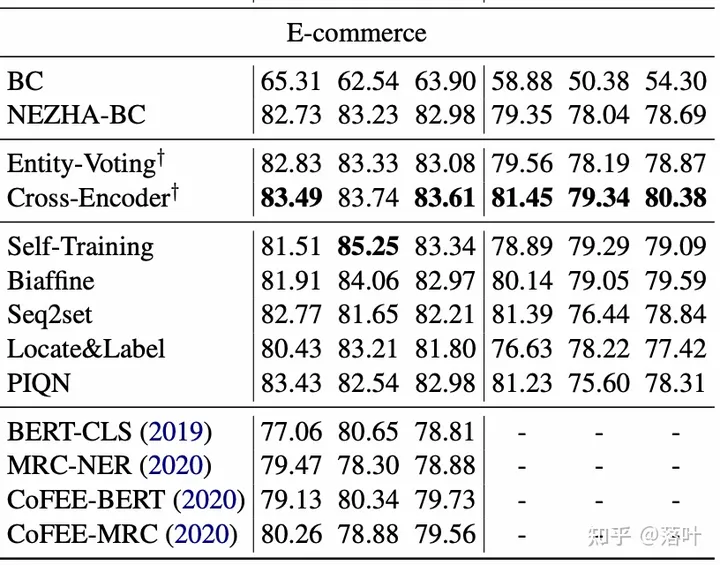
在本文中,我们提出检索使用相似样本来提升垂直领域NER性能,以及 Entity-Voting 和 Cross-Encoder 两个简单的相似样本建模方法,在 地址 和 电商 两个特殊领域上的实验验证了方法的有效性。
如对相关技术比较感兴趣,欢迎关注我们的「AdaSeq序列理解技术」专栏,github主页,加入我们的钉钉群 (4170025534) 进行技术交流。

