
论文地址:1905.00641.pdf (arxiv.org)
根据李沐老师的 如何读论文【论文精读】 这篇教程

视频源地址:如何读论文【论文精读】_哔哩哔哩_bilibili
读论文主要从六个方面着手:
1.论文标题
2.论文摘要
3.论文介绍
4.论文提出的算法
5.论文的实验
6.论文的结论
套用公式(其中因已有读者对论文进行详尽翻译,在此直接引用,斜体为引用项,侵删):
1.论文标题:
Retinaface
2.论文摘要:
虽然在不受控条件下的人脸检测已经取得了非常显著的进展,在自然环境下准确有效的人脸检测依然具有挑战。本文提出了一种单级(single-stage)人脸检测器:RetinaFace. 通过联合外监督(extra-supervised)和自监督(self-supervised)的多任务学习,RetinaFace对各种尺度条件下的人脸可以做到像素级别的定位。本文作了以下几个贡献:
1、 我们手工标注了WIDER FACE数据集上的五点,在外监督信号的辅助下获得了难人脸检测的显著提升。(zhuanlan.zhihu.com/p/10)
2、添加了一个自监督网格编码分支,用于预测一个逐像素的3D人脸信息。该分支与已存在的监督分支并行。
3、在WIDER FACE测试集上,RetinaFace(AP = 91.4%)比最好的模型AP高出1.1%
4、在IJB-C测试集上,RetinaFace使当前最好的ArcFace在人脸认证(face verification)上进一步提升(TAR=89.59 FAR=1e-6)
5、通过利用轻量级的骨架网络,RetinaFace可以在单一CPU上对一张VGA分辨率的图像实时运行
标注和代码获取地址
Deep Insightinsightface/tree/master/RetinaFace
本节概念:TAR True Accept Rate 正确接受率; FAR False Accept Rate 错误接受率 ;
VGA分辨率:图像大小640×480 HD图像:1920×1080 4K图像:4096×2160
3.论文介绍:
自动人脸定位是人脸图像分析如人脸属性(表情,年龄,ID识别)的先决步骤。人脸识别传统的窄定义为:在没有任何尺度和位置先验信息的条件下估计人脸的包围框。然而在本文中,人脸定位是一个更宽泛的定义,包括人脸检测,人脸对齐,像素级别的人脸分解以及_3D密度回归__。那种密集的人脸定位可以为所有不同尺度的人脸提供准确的人脸位置信息。_
与通用的目标检测方法不同的是,人脸检测的特征宽高比变化很小(1:1到1:1.5),但是尺度变化非常大(从几个像素到几千个像素)。最近最好的方法关注于单级设计,在特征金字塔上进行密集的人脸位置和尺度采样,相比两级级联方法,这种设计获得了不错的性能和速度提升。依据这种路线,我们提升的单级人脸检测框架,并且通过利用强监督和自监督型号的多任务损失,提出了当前最好的密集人脸定位方法。思想如图1:
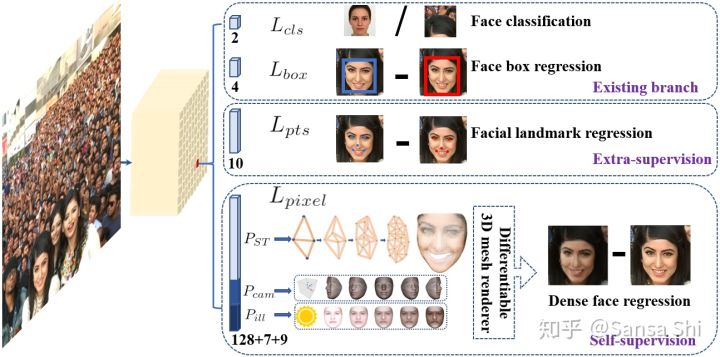
图 1:单级逐像素人脸定位方法利用外监督和自监督的多任务学习同时包含人脸框分类及回归分支。每个positive anchor输出:人脸得分,人脸框,5个人脸关键点,投射的图像平面上的3D人脸顶点
特别的,人脸定位训练过程包含分类和人脸框回归损失。在一个联合级联框架中将人脸检测和对齐结合,获得的人脸形状可以为人脸分类提供更好的特征。基于这种思想,MTCNN和STN同时检测人脸和五个关键点。基于训练数据的限制,JDA,MTCNN ,STN并没有验证小人脸是否可以从5个关键点的外监督中受益。本文想要回答的一个问题是,是否可以通过5个关键点重建的外监督信号将WIDER FACE难测试集当前最好的性能90.3%向前推进。
在Mask R-CNN中,通过增加目标淹没的分支并与检测框识别和回归分支并行,检测性能显著提升。这证实了密集像素级别的标注对于提升检测性能也有用。然而,WIDER FACE中具有挑战的人脸无法获取密集的人脸标注。既然监督信号不易获取,那么问题就变成了我们是否可以利用无监督的方法进一步提升人脸检测呢。
FAN提出一个anchor级别的注意力图来提升遮挡人脸检测。然而,提出的注意力图比较粗糙且不包含语义信息。最近,自监督3D形变模型获得了不错的自然条件下的3D人脸。特别的,Mesh Decoder利用在形状和纹理上的_图卷积_获得了超实时的速度。然而,将mesh decoder应用到单级检测器上的最大挑战是:(1)相机参数很难准确估计(2)联合潜在形状和纹理估计是从一个简单的特征向量预测的(特征金字塔上的1×1卷积)而不是通过RoI池化特征,这样就存在特征漂移的风险。本文通过对于一个像素级3D人脸形状的自监督学习与存在的监督分支并行,利用网络编码(mesh decoder)分支。
总之,主要贡献:
基于单级设计,提出一个新的像素级人脸定位方法RetinaFace,利用多任务学习策略同时预测人脸评分,人脸框,5个关键点以及对应于每个人脸像素的3D位置。
在WIDER FACE难子集上,RetinaFace的AP=91.4%,比最好的两级级联方法ISRN提升1.1%
在IJB-C测试集上,RetinaFace将ArcFace在人脸认证(face verification)上进一步提升(TAR=89.59%FAR=1e-6)。这表示更好的人脸定位可以显著提升人脸识别
通过利用轻量级的骨架网络,RetinaFace可以在单一CPU上对一张VGA分辨率的图像实时运行
标注和源码
4.论文提出的算法:
多任务损失
对于每一个训练anchor i,我们最小化多任务损失:
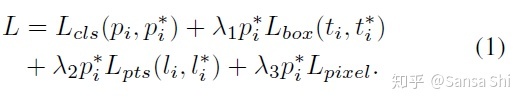
(1)人脸分类损失Lcls(pi,pi∗) ,pi表示预测anchor i为人脸的概率,pi*表示真值,正样本anchor为1,负样本anchor为0.分类损失Lcls是softmax损失,对于二分类(是人脸/不是人脸);(2)人脸框回归损失 Lbox(ti,ti∗) ,其中ti=(tx,ty,tw,th)i,ti∗=(tx∗,ty∗,tw∗,th∗)i 表示与正样本anchor对应的预测框的位置和真实标注框的位置。归一化box回归目标并使用 Lbox(ti,ti∗)=R(tI,ti∗) 其中R表示_smooth_L1鲁棒性回归函数(参见fast Rcnn)__。(3)人脸关键点回归函数 ()()Lpts(li,li∗),li=(lx1,ly1,……,lx5,ly5),li∗=(lx1∗,ly1∗,……,lx5∗,ly5∗)_
分别表示正样本人脸anchor5关键点的预测和真值。与box回归一致,人脸5关键点会与同样使用目标归一化。(4)密集回归损失 Lpixel 参见公式3。 λ1−λ3 的值分别设置为0。25,0.1,0.01,意味着提升了来自监督信号的更好人脸框和五点位置的重要性。
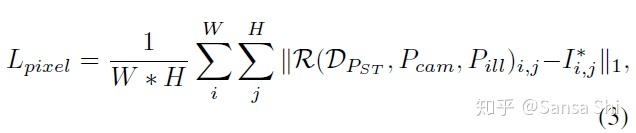
密集回归分支
网格编码(Mesh Decoder)直接利用网格编码器(网格卷积和网格上采样),也就是基于快速局部谱滤波器(fast localised spectral filtering)的图卷积方法。为了获得更快的速度,我们联合形状和上下文解码。
下面 将简单解释图卷积的概念并且说明他们可以被用于快速解码的原因。如图3(a)所示,一个2D卷积操作是一个欧几里得网格感受野中的“核加权近邻求和”(kernel-wighted neighbour sum)。类似的,图卷积利用了图3(b)中的类似感念。然而,图近邻距离的计算方法是通过连接两个顶点的边的最小数量。定义一个人脸网格 ()其中G=(V,ξ)其中V∈Rn×6 V是人脸顶点集合,包含形状和纹理信息。 ξ∈(0,1)(n×n) 是一个稀疏临接矩阵用于编码两个顶点之间的连接状态。图拉普拉斯定义为 其中是一个对角阵L=D−ξ∈Rn×n,其中D∈Rn×n是一个对角阵Dii=Σjξij
核 gθ 的图卷积可以用切比雪夫K阶多项式展开来表示:
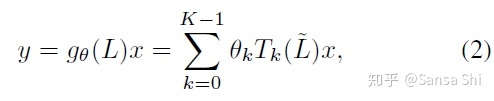
是切比雪夫系数,是尺度化的拉普拉斯的阶拉普拉斯多项式。θ∈Rk是切比雪夫系数,Tk(L^)∈Rn×n是尺度化的拉普拉斯L^的k阶拉普拉斯多项式。 我们可以迭代计算在和x^=Tk(L^)x∈Rn,我们可以迭代计算x¯k=2L^x¯k−1−x¯k−2在x¯0=x和barx1=Lx¯ 处的值。整体的计算过程非常高效,因为包含了K个离散矩阵向量相乘和一个密集矩阵乘法 y=gθ(L)x=[x¯0,…..,x¯K−1]θ
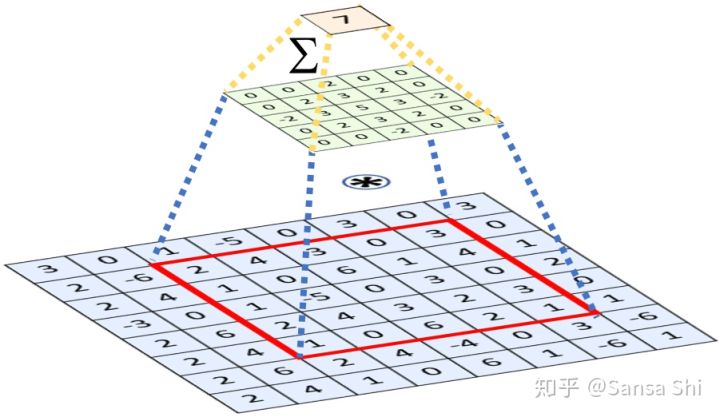 图3a 2D卷积
图3a 2D卷积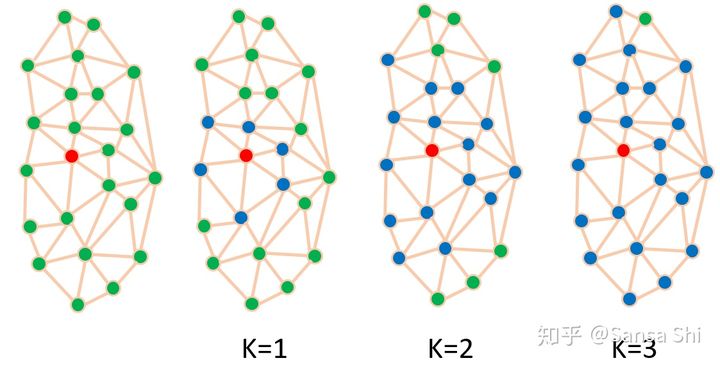 图3b 图卷积
图3b 图卷积
可微渲染器(Differentable Renderer)在预测了形状和纹理参数 PST∈R128 后,利用一个高效可微3D网格渲染器来投影彩色网格 DPST 到一个2D图像平面上,利用相机参数 Pcam=[xc,yc,zc,xc′,yc′,zc′,fc] 也就是相机位置,相机形状和焦距以及光照参数 Pill=[xl,yl,zl,rl,gl,bl,ra,ga,ba] (光源位置,颜色值,环境光颜色)
密集回归损失一旦得到了渲染2D人脸 ()R(DPST,Pcam,Pill) 我们比较渲染得到人脸与原始2D人脸的像素差异:W H表示anchor区域I i j *的宽和高
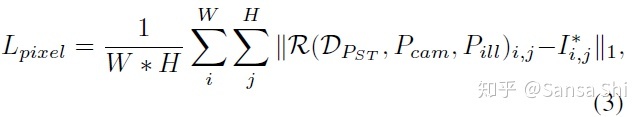
5.论文的实验:
数据集
WIDER FACE数据集包含32,203个图像和393,703个人脸框,尺度, 姿态,表情,遮挡和光照变化都很大。WIDER FACE数据集被分为训练40% 验证10% 和测试50%三个子集,通过在61个场景分类中随机采样。基于EdgeBox的检测率,通过递增合并难样本,困难程度分为3级:容易,中性和困难。
额外标注
如图4和表1,我们定义的5个人脸质量级别,依据人脸关键点标注困难程度并且标注5个关键点(眼睛中心,鼻尖,嘴角)。我们总共标注了84.6k个训练集人脸和18.5k个验证集人脸。
 图4
图4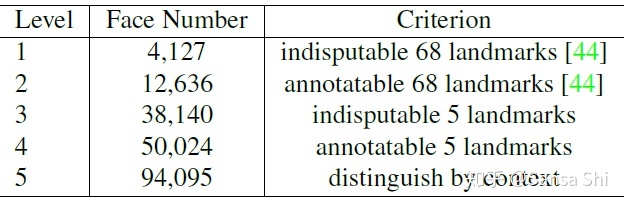 表1
表1
应用详情
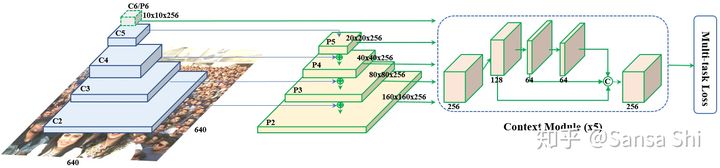
特征金字塔 RetinaFace应用特征金字塔从P2到P6,其中P2到P5是从Resnet残差级(C2到C5)计算而来。P6将C5通过一个3×3,s=2的卷积得到。C1到C5来自于在ImageNet-11k数据集上预训练的ResNet-152分类框架而P6通过Xavier随机初始化。
上下文模块 受启发于SSH和PyramidBox,我们也把独立上下文模块应用于5个特征金字塔上用于提高感受野和加强严格上下文建模能力。从WIDER Face Challenge2018中总结经验,我们将所有侧连的3×3卷积层和上下文模块都替换为了DCN,可以进一步加强非严格上下文建模能力
损失头(Loss Head) 对于所有的负样本anchors,仅仅使用了分类损失。对于正样本anchors,则计算多任务损失。我们在不同的特征图之间 Hn×Wn×256,n∈(2,…,6) 利用一个共享损失头(1×1卷积).对于网格编码,我们利用一个预训练模型【70】,计算开销很小。
_Anchor设置 如表2所示,在从P2到P6的特征金字塔上使用特定尺度anchor。P2用于抓取小脸,通过使用更小的anchor,当然,计算代价会变大同事误报会增多。设置尺度步长为 21/3 ,宽高比1:1。输入图像640×640,anchor从16×16到406×406在特征金字塔上。总共有102,300个anchors,75%来自P2层。给大家解释一下这个102300怎么来的:(160*160+80*__80+40*_40+20*20+10)*3 = 102300。
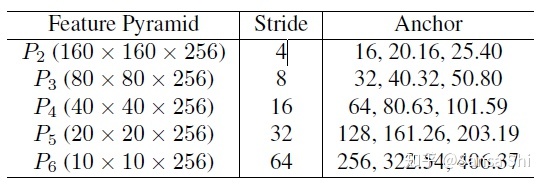 表2
表2
在训练阶段,ground-truth的IOU大于0.5的anchor被任务是正样本,小于0.3的anchor认为是背景。anchors中有大于99%的都是负样本,使用标准OHEM避免正负样本的不均衡。通过loss值选择负样本,正负样本比例1:3
数据增强 WIDER FACE有20%的小脸,从原始图像随机crop 方形patch并缩放至640*640来生成更大的人脸。方形patch的截取大小是随机选择[0.3,1]被的原始图像短边长度。在crop边界上的人脸,保留中心在crop patch内的人脸框。除了随机crop,我们通过水平旋转一半的图像以及对另一半颜色扰动。
训练细节 使用SGD优化器训练RetinaFace(momentum=0.9,weight decay = 0.0005,batchsize=8×4),Nvidia Tesla P40(24G) GPUs.起始学习率0.001,5个epoch后变为0.01,然后在第55和第68个epoch时除以10.
测试细节 在WIDER FACE上测试,利用了flip和多尺度(500,800,1100,1400,1700)策略。使用IoU 阈值0.4,预测人脸框的集合使用投票策略。
消融实验
为了获得更好的理解,做了扩展实验i检验标注五点和密集回归分支对人脸检测性能的影响。除了在简单,中性和容易的数据集上使用标准的AP测量策略(IoU-0.5),我们也利用 难验证子集,测试更严格的AP在IoU=0.5:0.05:0.95.
如表格3所示,评价了几个WIDER FACE验证集上的配置并关注难验证集 子集的AP 和mAP。通过使用FPN、上下文信息、形变卷积等策略,得到了一个很好的baseline。通过增加5点分支,在难样本上显著提升,说明5点对 人脸检测的提升很明显。对比而言,密集回归分支提升了简单和中性人脸的检测,但是对困难人脸的提升不大。把5点分支和密集分支一起使用,性能依然有提升。
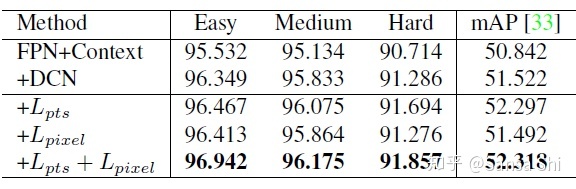 表3
表3
人脸框准确率
分别在WIDER FACE验证集和测试集上评价了算法模型。将Retina与当前最好的24个人脸检测算法比较(i.e. Multiscale Cascade CNN [60], Two-stage CNN [60], ACFWIDER[58], Faceness-WIDER [59], Multitask Cascade CNN [66], CMS-RCNN [72], LDCF+ [37],HR [23], Face R-CNN [54], ScaleFace [61], SSH [36], SFD [68], Face RFCN[57], MSCNN [4], FAN [56], Zhu et al. [71], Pyramid-Box [49], FDNet [63], SRN [8], FANet [65], DSFD [27],DFS [50], VIM-FD [69], ISRN [67])..RetinaFace在AP上比以上算法都好。在验证集上,96.9%easy96.1%medium以及91.8%Hard,在测试集上,96.3%容易95.6中性91.4%困难。
如图6所示,展示了密集人脸情况下的检出质量,在0.5以上的人脸检出900个,总共是1151人脸。除了人脸框准确之外,5点定位在不同的姿态遮挡分辨率下也都很鲁棒。尽管在严重遮挡的情况下密集人脸定位依然有失败的案例,但在一些清晰的大人脸上效果很好,甚至都可以看到一个表情变化。
 图6
图6
五点定位准确率
为了评价五点定位准确率,我们在AFLW数据集上(24386人脸)和WIDER FACE验证集(18.5k人脸)比较了MTCNN和RetinaFace。使用人脸框大小归一化距离。如图7a所示,给出在AFLW上每个点的平均误差。RetinaFace将归一化平均误差 NME从MTCNN的2.72%下降为2.21%。在图7b中,展示了在WIDER FACE 验证集上的累积误差分布CED。与MTCNN相比,在NME阈值为10%时的漏报率由26.31%降到9.37%。
密集人脸关键点准确性
除了人脸框和5点,Retinaface还输入密集人脸关键点,并且是自监督训练。在AFLW2000-3D数据集上评价密集人脸关键点定位(1)2D投影下的68人脸关键点(2)所有关键点的3D坐标。平均误差通过人脸框大小归一化。图8a和图8b是当前最好方法的CED曲线。尽管自监督和有监督方法的性能差异还比较大,但是RetinaFace相比较而言是最好的方法。特别的,可以看出:(1)五点回归可以避免密集回归分支的训练困难并且可以显著提升密集回归的效果。(2)使用单级特征来预测密集人脸比使用RoI特征(如网格编码)要困难的多。如图8c所示,RetinaFace可以很容易的处理人脸姿态变化但是在复杂场景下就比较困难。这表示没有对齐以及过于压缩的特征表示(1x1x256)会妨碍单级框架获取高精度的密集回归输出。尽管如此,回归分支中投影出来的回归区域依然有助于人类检测结果的提升。
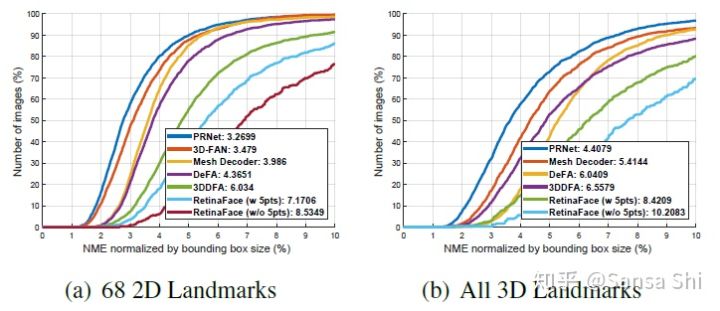
 图8(c) Result Analysis (Upper: Mesh Decoder; Lower: RetinaFace)
图8(c) Result Analysis (Upper: Mesh Decoder; Lower: RetinaFace)
人脸识别准确率
本文展示了我们的人脸检测方法是如何提升Arcface人脸识别方法准确率的。本文分别比较了使用MTCNN和Retinaface来检测和对齐所有的训练数据(MS1M)以及测试数据(LFW,CFP-FP,AGEDB-30,IJBC),保留原Arcface中使用的Resnet100基础网络以及损失函数。比较解过如表4所示,基于CFP-FP,证明Retinaface可以提升Arcface的验证正确率从98.37%到99.49%。这个结果展示了正脸-侧脸的人脸认证已经达到了正脸-正脸的人脸认证水平。(99.86%在LFW上)
 表4
表4
如图9所示展示了在FAR=1e-6时IJB-C数据中的ROC曲线。我们使用了两个tricks(镜像测试以及人脸检测评分去加权模板中的样本)来提升人脸认证准确率。使用retinaface代替mtcnn,TAR从88.29%提升到了89.59%。这表示(1)人脸检测和对齐对人脸识别影响很大(2)Retinaface相比MTCNN更加强壮。
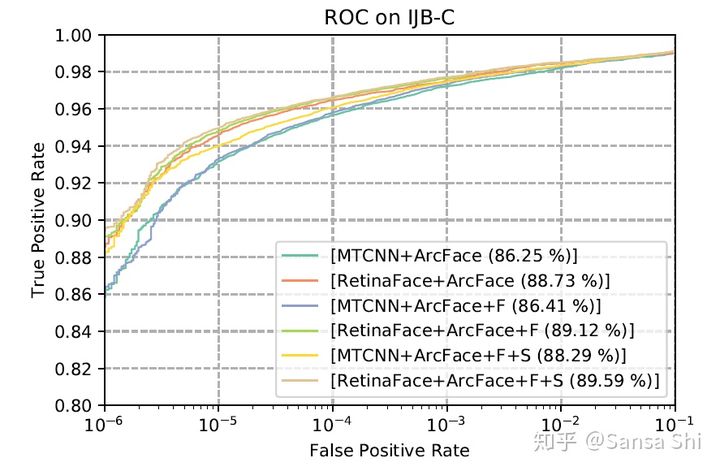 图9
图9
inference效率
在测试时,retianface灵活而高效的进行人脸定位。除了权值较多的模型(ResNet-152,262M,AP=91.8%在WIDER FACE难样本集合上),我们也开发了一个轻量级的模型(MobileNet-0.25,1M,AP=78.2%在WIDER FACE难样本集合上)来加速预测。
对于轻量级网络,我们可以通过一个步长为4,7×7的卷积,快速地减少数据大小,像文献【36】那样在P3,P4,P5后面添加密集anchors,并删除了形变层。此外,前两个卷积层使用imagenet预训练初始化后再训练时固定下来以获得更高的准确率。
表格5展示了不同输入尺寸下两个模型的耗时。其中,密集回归分支的时间没有统计进去。使用TVM来加速模型预测,在NVIDIA Tesla P40 GPU,Intel i7-6700k cpu和ARM-RK3399.
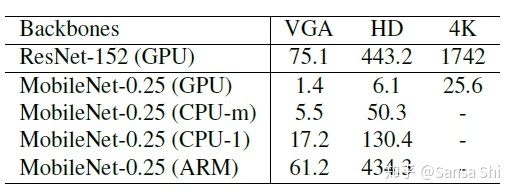
6.论文的结论:
研究了在任意尺度图像下同时进行密集回归和对齐的问题,提出了第一个单级解决方案(RetinaFace)。我们的方法称为当前最好的检测方法,结合最好的人脸识别方法识别准确率也进一步提升。

