文本检测模型的目的是排除图片中背景等杂物的干扰,尽可能准确地定位出文字所在区域。但是,一些已在计算机视觉领域取得优异成绩的物体检测方法,如 基 于 VGG16 进 行 改 进 的 SSD, 将 two-stage 的 方 法 简 化 为 one-stage 的YOLO, 以及加入了 RPN(Region Proposal Network)的 Faster-RCNN等,并不适合直接用于文字检测任务效果,主要原因如下:
(1)与常规物体不同,自然场景中的文本的长宽比变化范围广、变化频率高。
(2)文本行的外观变化可以很大,比如艺术字,不同人的手写体等,它们甚至可以是弯曲的形状。
(3)自然场景中存在一些与文本行外观相似的物体(比如栅栏、窗户等),容易导致误报的产生。
(4)多角度倾斜的文本行在自然场景中非常多见,常规物体边界框的描述方式对它们不再适用。
这些特性使得文本的检测难于其他常规物体,传统的基于手工特征设计的方法难以获得突破。2006 年,深度学习的概念被 Hinton 等人首次提出,它们从多种可行的角度出发,比如半监督学习、特征提取、损失函数、区域建议、非极大值抑制等对原有模型进行优化,实现了自然场景文字检测准确率的有效提升。一些非常具有代表性的改造方案如下:
(1)RRPN,即旋转候选区域网络,它的创新点在于可以生成带有倾斜角的文本候选区域。整个检测网络分为三个部分,第一部分利用 VGG16 进行特征提取,第二部分为 RRPN,最后是多任务损失部分。整体结构类似于 Faster-RCNN。
(2)SegLink将一个单词切割成若干个小文字块,这样的小目标更易检测,相邻文字块的链接部分被预测到后,再将小文字块连接成完整单词即可。
(3)DMPNet提出使用大量多方向的更灵活的四边形滑动窗口,减少背景噪声,提高文本召回率,有效消除误报,从而达到更高的检测精度。
(4)FTSN提出一种面向多方向场景文本检测的融合文本分割网络,是针对弯曲文本检测的方案。作者的基本思想是基于实例分割的,并提出不再使用NMS 滤除冗余候选框,而是将其替换为 Mask-NMS。
(5)TextBoxes 的主要创新点是将特征层卷积核调整为若干种具有不同长宽比的长条形,从而对于细长型文本行的检测更具有鲁棒性。
(6)CTPN 提出用 BLSTM模块提取字符周围的上下文特征,有效地提高了文本检测的准确度。
2. CTPN 模型
Detecting Text in Natural Image with Connectionist Text Proposal Network 网址: https://arxiv.org/pdf/1609.03605.pdf
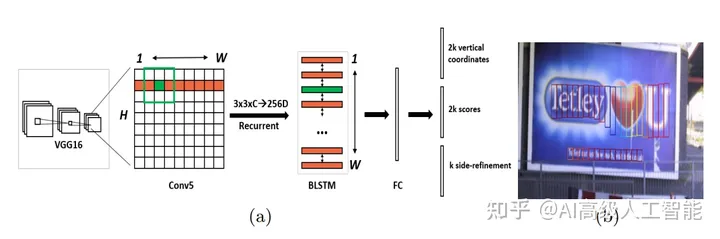
CTPN 提出了一种新的连接文本提案(proposal)网络,受到数学中微分思想的启发,该网络通过直接在卷积特征映射中检测一系列尺度精密的、宽度统一的文本提案,再通过后处理过程将它们连接起来,即可实现准确地定位自然图像中的文本行,但是文本行的方向只能是水平或微斜的。CTPN 的创新点主要在于:①.开发了一种垂直锚定(Anchor)机制,可以预测每个固定宽度提案的位置和文本/非文本得分,大大提高了定位精度;②.CTPN 将一系列的精细比例的文本提案视为有序序列,即互为上下文关系。首先用 VGG16 提取字符的基础特征,再用双向 LSTM(即 BLSTM)层获取字符间的上下文特征,最后用全连接层预测每个小文字块的坐标和类别。上述工作使得 CTPN 能够探索图像中的丰富上下文信息,因此即使是非常模糊的文本也能进行检测。③.在后处理过程中,提出用文本线构造算法将小文字块连接成完整的文本框。文本线构造算法大致过程是为检测到的每个小文字块正向和反向地寻找水平距离小于 50 像素的配对文字块,寻找完全部的文字块后即可自然形成它们的连接图,从而找到文本检测框。

3. East 模型EAST: An Efficient and Accurate Scene Text Detector论文地址:https://arxiv.org/pdf/1704.03155.pdf
Github:
https://github.com/argman/EAST
https://github.com/kurapan/EAST
在 East 模型发布之前,场景文本检测方法已经在不同领域取得了鲁棒的性能指标。然而,它们往往在处理具有挑战性的场景时表现不够好,即使使用了足够深层的神经网络模型,这是因为模型的整体性能是由流水线中多个阶段和部件间的相互作用决定的。为此,East 提出了一种简单而性能强大的流水线,可在自然场景中快速而准确的实现文本检测。该流水线利用简单的神经网络直接预测全图像中任意方向的四边形单词或文本行,消除了不必要的中间步骤。因为省略了其他模型中常见的区域建议、单词分割、子块合并等步骤,因此该模型的执行速度很快。检测效果方面,根据开源工程中预训练模型的测试,该模型检测英文单词效果较好,但检测中文长文本行效果欠佳。论文的总体思想非常简洁,结合了DenseBox和 U-shape 网络中的特性,具体流程如下:
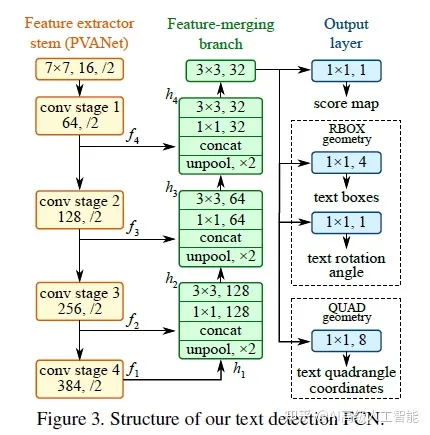
首先采用 Pvanet作为基础网络,用于特征提取,在上述主干特征提取网络中,提取不同层级的特征图(它们的尺寸分别是输入图像的 1/32,1/16,1/8,1/4),目的是解决各种文本行尺度变换剧烈的问题,浅层特征图可用于预测小的文本行,深层特征图可用于预测大的文本行。第二阶段是特征合并部分,将提取出的深、浅层特征图进行合并,合并的规则采用了 U-shape 的方法,即从特征提取网络的顶部特征按照相应的规则向下进行合并,具体可参见下图所示的网络结构图。第三阶段网络输出部分,包含文本得分和文本形状,根据不同文本形状(可分为RBOX 和 QUAD),输出也各不相同。