
论文题目:Real-time Scene Text Detection with Differentiable Binarization
论文地址:https://arxiv.org/abs/1911.08947
代码地址:https://github.com/MhLiao/DB(官方)
https://github.com/WenmuZhou/DBNet.pytorch
一个不错的视频讲解链接:https://www.bilibili.com/video/BV1xf4y1p7Gf?t=2230
文章贡献:
提出了用于文字检测的可微二值化网络DBNet,可检测水平文本、多方向文本、弯曲文本,比之前的先进方法拥有更快的速度,同时拥有可观的性能。
DBNet使用轻量级骨干时也能拥有不错的效果,且在推理时不需要额外的时间和内存成本。
网络框架 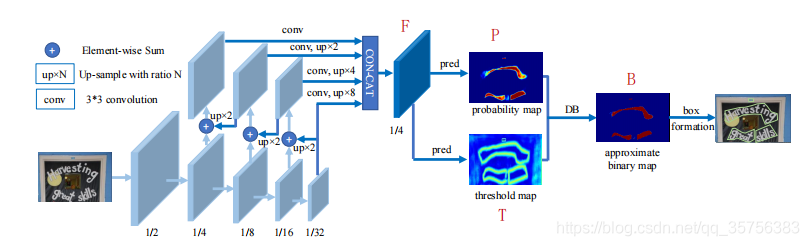
训练阶段:
前半使用FPN进行多尺度特征提取与融合,得到原图1/4大小的特征图F。F经过卷积生成概率图P和阈值图T,由P和T经过DB处理得到近似二值图B,由B进行扩张得到最终的检测结果。
其中,图P、T、B均使用监督信息,且P和B的监督标签相同。
推理阶段: 
直接由P经过标准二值化(t=0.2)处理得到B',再扩张可得到最终检测结果,而无需求得T和B。扩张系数D'可由式10计算:
A'是B'的面积,L'是B'的周长,设定r'=1.5。
后处理过程: 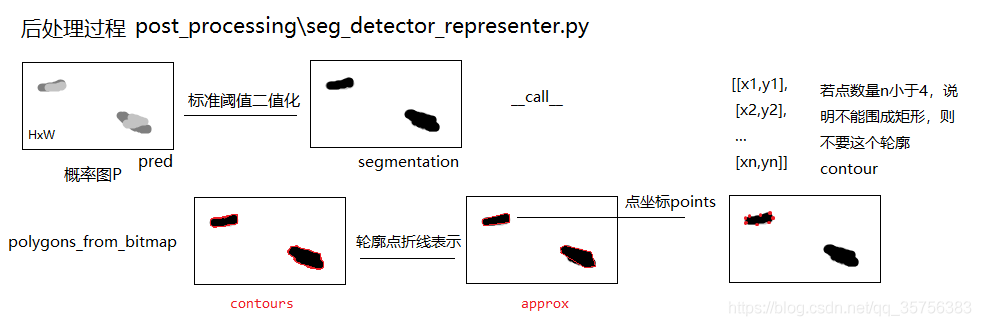
可变形卷积[1]
变形卷积可以为模型提供一个灵活的接受域,这对极端宽高比的文本实例尤其有利。 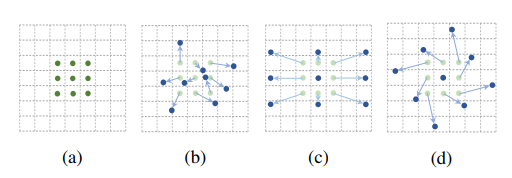
如上图a为一个标准3x3卷积,而bcd就是可变形卷积,卷积的9个点可能基于标准卷积原始的位置有不同程度的偏移。 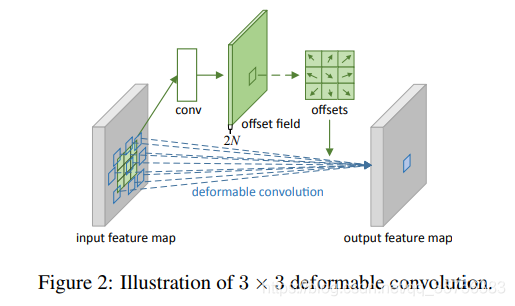
具体卷积过程如上图所示,输入特征(CxHxW)首先经过一个标准卷积,得到offset field(2NxHxW),对于3x3可变卷积来说,N=9,因为卷积为9个点。之后将原本的输入特征与求得的其对应的偏移量offets一起进行一个可变卷积,可得到最后的输出特征。
论文在骨干网络resnet的stage2/3/4中的所有3x3卷积中均采用可变形卷积:


为什么要用阈值图T而不是固定阈值来二值化 1. 获得更好的二值化效果。
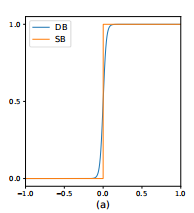
上图为标准阈值二值化SB和可微分二值化DB的曲线,横坐标表示P(i,j)-T(i,j) 的值,纵坐标表示点(i,j)二值化后的坐标值。可以看到,二者比较相近,而DB可微,可跟随网络一起优化。
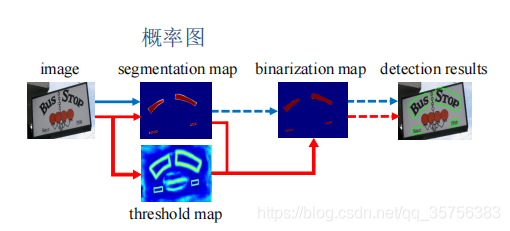
传统文字检测流程图如上图蓝线所示,虚线表示推理过程。根据输入图片求得其文字区域概率图,经过二值化后再进行后处理可得检测结果。
而论文的流程为红线所示,在训练阶段多了一个求得阈值图的过程,而推理阶段则不需要花费额外的时间来求得二值化图,仅需后处理的时间。
如何求B(DB操作过程) 标准阈值二值化SB,对于一张图片P,设定阈值t,若像素值P(i,j)>t,则二值化为1,否则为0:
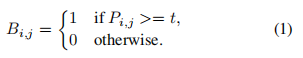
由于SB不可微,不能和神经网络一起优化,因此论文提出DB:
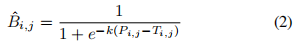
不同于SB对所有像素点均是相同的阈值,DB 对每个像素点均有不同的阈值,该阈值图即为T,T可从网络中学习得到。其中k为放大系数,设k=50。
相当于是对于一张图片P,设定像素点(i,j)的阈值为T(i,j),若像素值P(i,j)>阈值T(i,j),则二值化为一个接近1的数,不然二值化为一个接近0的数。
DB能提高性能的可解释性
对于二元交叉熵BCE损失: 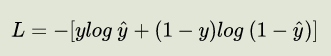
令 y=,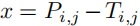 ,有:
,有:
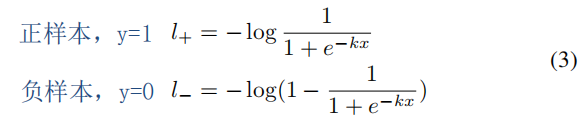
考虑反向传播过程,对其求导: 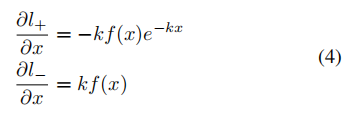
函数曲线如下:
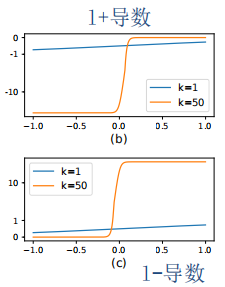
上图中横坐标为x,纵坐标为对应导数。
图b表示的是正样本,在x>0时有P(i,j)>T(i,j)即预测正确;x<0时有P(i,j)<T(i,j)即预测错误。而对比k=50和k=1,可以发现k=50时对预测错误的梯度的增加是显著的。图c同理,因此k的取值可以促进优化从而产生更好的预测结果。
标签生成 由于P、T、B均需要监督信息,P和B的标签一致,因此每张图片需要生成其对应的2个label。 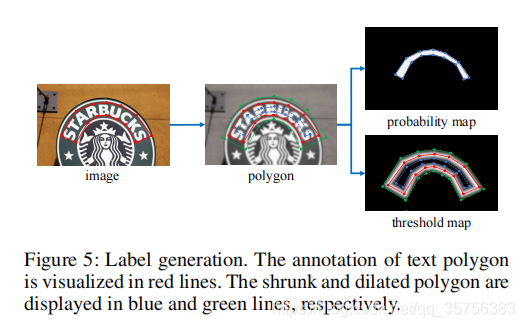
图5中,image的红色框G表示原始的文本位置标注信息,polygon的蓝色框Gs围成的范围表示需生成的P和B的标签probability map,绿色框Gd与蓝色框Gs之间围成的范围表示需生成的T的标签threshold map。
probability map的获取采取了和PSENet相同的方式,使用Vatti clipping算法,收缩的偏移量D为:
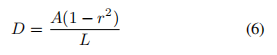
其中A为原始标签的面积,L为其周长,r=0.4。如果原始文本框太小,或收缩后得到的轮廓面积太小,该文本区域视为没有。
threshold map为对G以相同偏移量D的扩张,并取Gd与Gs之间的范围。与probability map取值全1不同的是,threshold map各像素点的取值由该点到原始标签边框的最短距离计算得到。
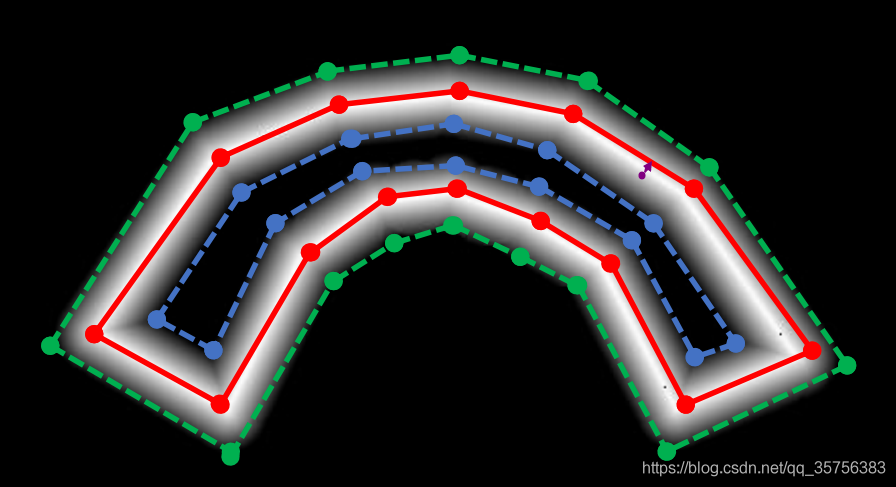
具体来说,对于上图中的紫色点,它到红色边框的最短距离如紫色箭头所示,设该距离为d,则该像素点取值为 1-(d/D),并将其由0-1的取值rescale到0.3-0.7。其中D为threshold map中所有像素点离红框距离能取到的最大值,即之前求的收缩/扩张系数D。
如果有两句相邻的文本,其扩张后阈值图有重叠,那么重叠部分的像素点的取值取其在每个文本中距离最小的那个来计算。
这样计算后可以发现,在红色框周围的像素点取值更加接近0.7, 而远离红色框周围的点取值趋向于0.3。
损失函数 总损失可以表示为概率图损失Ls,二值图损失Lb和阈值图损失Lt的加权和:
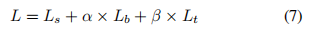
设定α=1,β=10。
对Ls和Lb都使用BCE损失,使用hard negative mining[2]方法来解决正负例(文字区域和非文字区域)不均衡的问题,有:
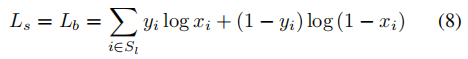
Sl是正负比=1:3的采样集合。
Lt使用L1距离,有: 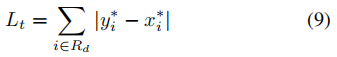
Rd是预测得到的Gd内部的像素索引集合(绿框内部所有区域),y*是对应位置的label。
参考文档 [1] 可变形卷积从概念到实现过程
[2] rcnn中的Hard negative mining方法是如何实现的? ————————————————
原文链接:https://blog.csdn.net/qq_35756383/article/details/118679258

