
以下文章来源于阿里语音AI ,作者达摩院语音实验室
你也来玩一玩个性化声音合成传送带👇:
https://t.tb.cn/_6UQ7fq1W8ijbXO1I4GmdQZ
提起个性化定制声音,或许大家并不陌生,许多平台会选择一些大家耳熟能详的明星,进行声音定制,并普遍应用在语音导航,文字播报,小说阅读等场景中。
这项技术来自文本到语音的服务,一般来说,使用AI合成效果上乘的人声需要专业播音员在录音棚里录制,且录制的数据量以1000句话起步,这种标准定制的流程,无论是对播音员、录制条件、录制数量和成本都提出了较高的要求。
Personal TTS,即个性化语音合成,是通过身边的一些常见录音设备(手机、电脑、录音笔等),录取目标说话人的少量声音片段后,构建出录音者的语音合成系统。相比于标准定制,个性化定制的技术难点在于,数据量有限(20句话)、数据质量差和标注等流程全自动化。PTTS的意义在于进一步降低语音合成的定制门槛,能够将语音合成定制推广到大众C端用户。
近年来,学术界有很多关于声音克隆的工作,论文陈述效果很好。考虑到落地应用场景的效果,达摩院以自研语音合成系统 KAN-TTS 的迁移学习能力为基础,设计了一套较为完善的个性化语音合成方案——用户只需要录制20句话,经过3分钟的训练,就能够获得一款效果尚佳的个性化声音。
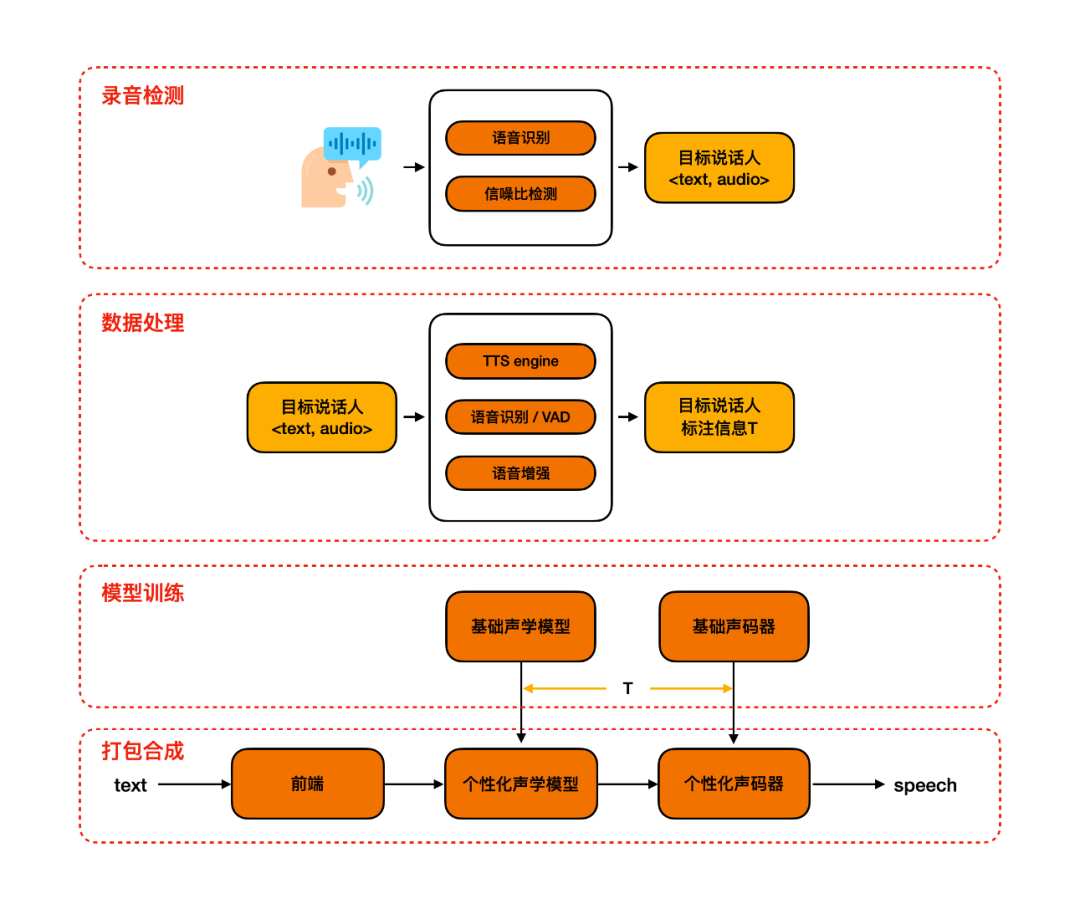
该系统的三大亮点:
NO.1 数据自动化处理和标注 在用户录制完音频之后,我们只有 <文本,音频>,而语音合成需要一些额外的标注信息:韵律标注、音素时长标注。为了获得较好的标注信息,我们采用了一种融合了多种原子能力的全自动化处理和标注流程,包括,韵律预测、ASR、VAD 和语音增强等。通过测试集测试,该自动化流程产生的标注信息,在准确度的基础上满足个性化的需求。
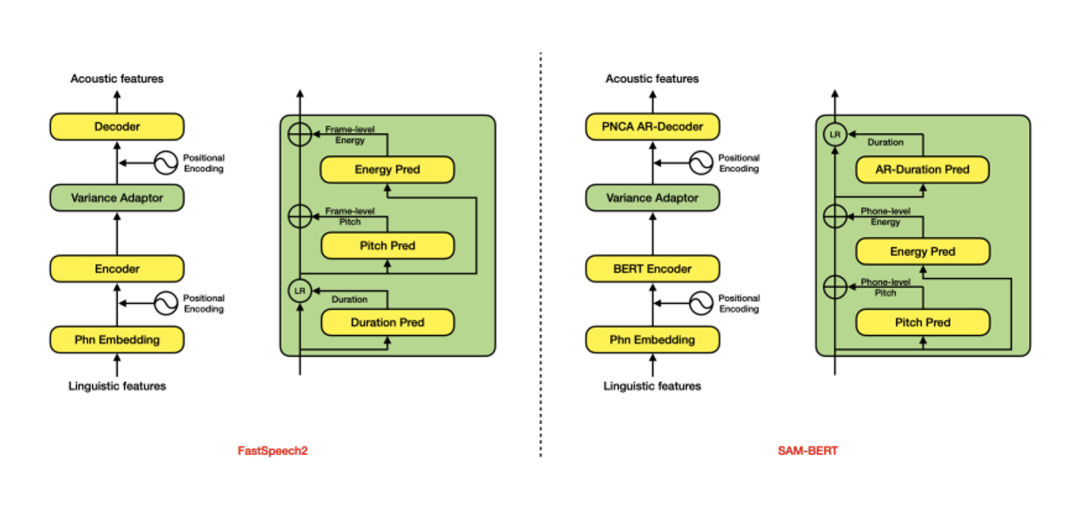
NO.2 韵律建模SAMBERT声学模型 在整个链路中,和效果最相关的模块就是声学模型。在语音合成领域,类似FastSpeech的Parallel模型是目前的主流,它针对基频(pitch)、能量(energy)和时长(duration)三种韵律表征分别建模。但是,该类模型普遍存在一些效果和性能上的问题,例如,独立建模时长、基频、能量,忽视了其内在联系;完全非自回归的网络结构,无法满足工业级实时合成需求;帧级别基频和能量预测不稳定等。
因此达摩院语音实验室设计了SAMBERT(一种基于Parallel结构的改良版TTS模型),它具有以下优点:
NO.3 基于说话人信息的个性化语音合成 如果需要进行迁移学习,那么需要先构建多说话人的声学模型,不同说话人是通过可训练的说话人编码(speaker embedding)进行区分的。给定新的一个说话人,一般通过随机初始化一个 speaker embedding,然后再基于这个说话人的数据进行更新(见下图说话人空间1)。对于个性化语音合成来说,发音人的数据量比较少,学习难度很大,最终合成声音的相似度就无法保证。 为了解决这个问题,我们采用说话人信息来表示每个说话人,以少量说话人数据初始化的 speaker embding 距离目标说话人更近(见下图说话人空间2),学习难度小,此时合成声音的相似度就比较高。采用基于说话人信息的个性化语音合成,使得在20句条件下,依旧能够有较好的相似度。 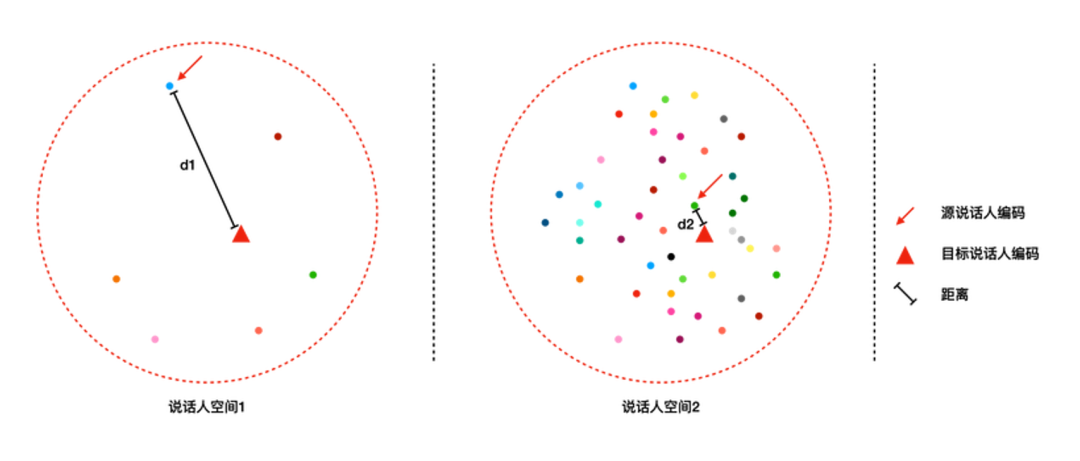
▎Future work 结合了数据自动化处理和标注、韵律建模 SAMBERT 声学模型和基于说话人信息的 Personal TTS 已上线ModelScope创空间。https://modelscope.cn/studios/damo/personal_tts/summary
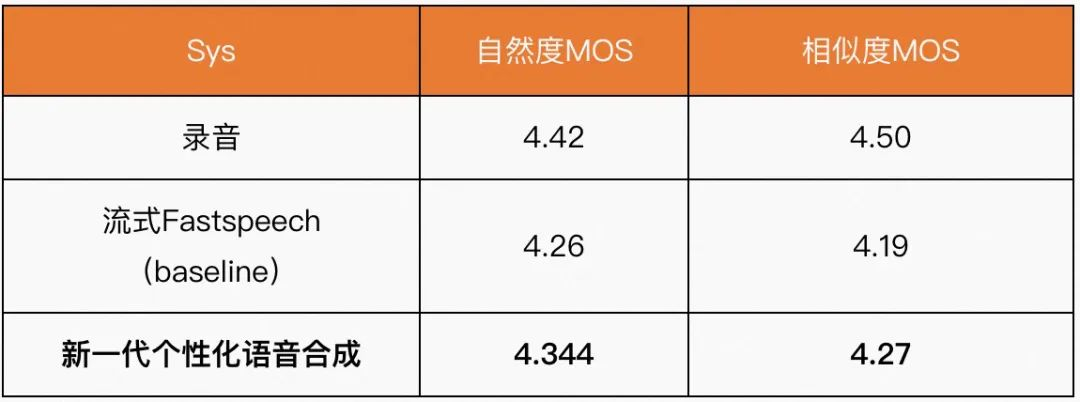
Personal TTS 作为一种 low resource TTS,在数据资源受限的情况下以期达到接近高质量录音的合成效果,后续达摩院将会结合大模型训练技术与真人化 TTS,打造更低资源占用,合成表现力更优的个性化语音合成系统。
References:
[1] Devlin J , Chang M W , Lee K , et al. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding[J]. 2018.
[2] Kong J , Kim J , Bae J . HiFi-GAN: Generative Adversarial Networks for Efficient and High Fidelity Speech Synthesis[J]. 2020.
[3] Li N , Liu Y , Wu Y , et al. RobuTrans: A Robust Transformer-Based Text-to-Speech Model[C]// National Conference on Artificial Intelligence. Association for the Advancement of Artificial Intelligence (AAAI), 2020.

