
mongodb时间戳类型如何增量同步?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
"设置任务依赖实现参数传递:设置节点依赖关系,调度配置都设置10分钟调度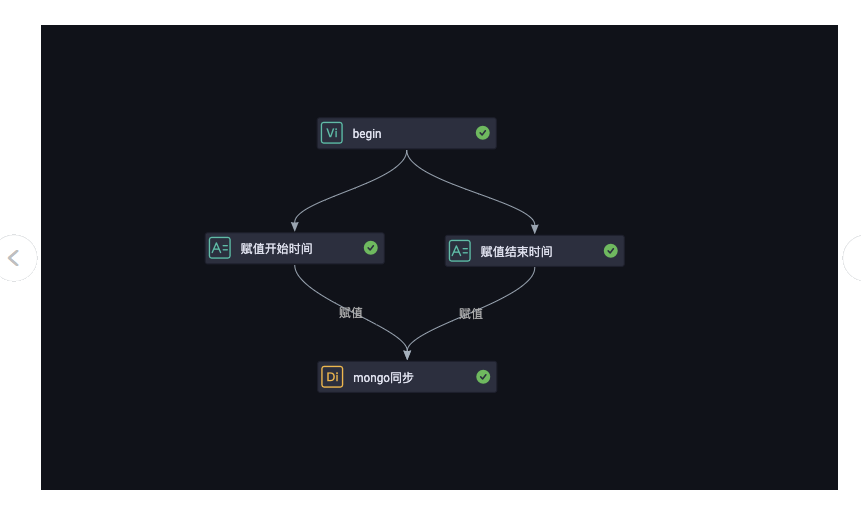 1、使用两个赋值节点定义时间戳格式的时间开始时间: 参数:day=$[yyyy-mm-dd] start_time=$[hh24:mi:ss- 1/24/60*10] 赋值语言选ODPS SQL:select UNIX_TIMESTAMP(""unknown unknown""); 结束时间: 参数:day=$[yyyy-mm-dd] end_time=$[hh24:mi:ss] 赋值语言选ODPS SQL:select UNIX_TIMESTAMP(""unknown unknown"");
1、使用两个赋值节点定义时间戳格式的时间开始时间: 参数:day=$[yyyy-mm-dd] start_time=$[hh24:mi:ss- 1/24/60*10] 赋值语言选ODPS SQL:select UNIX_TIMESTAMP(""unknown unknown""); 结束时间: 参数:day=$[yyyy-mm-dd] end_time=$[hh24:mi:ss] 赋值语言选ODPS SQL:select UNIX_TIMESTAMP(""unknown unknown"");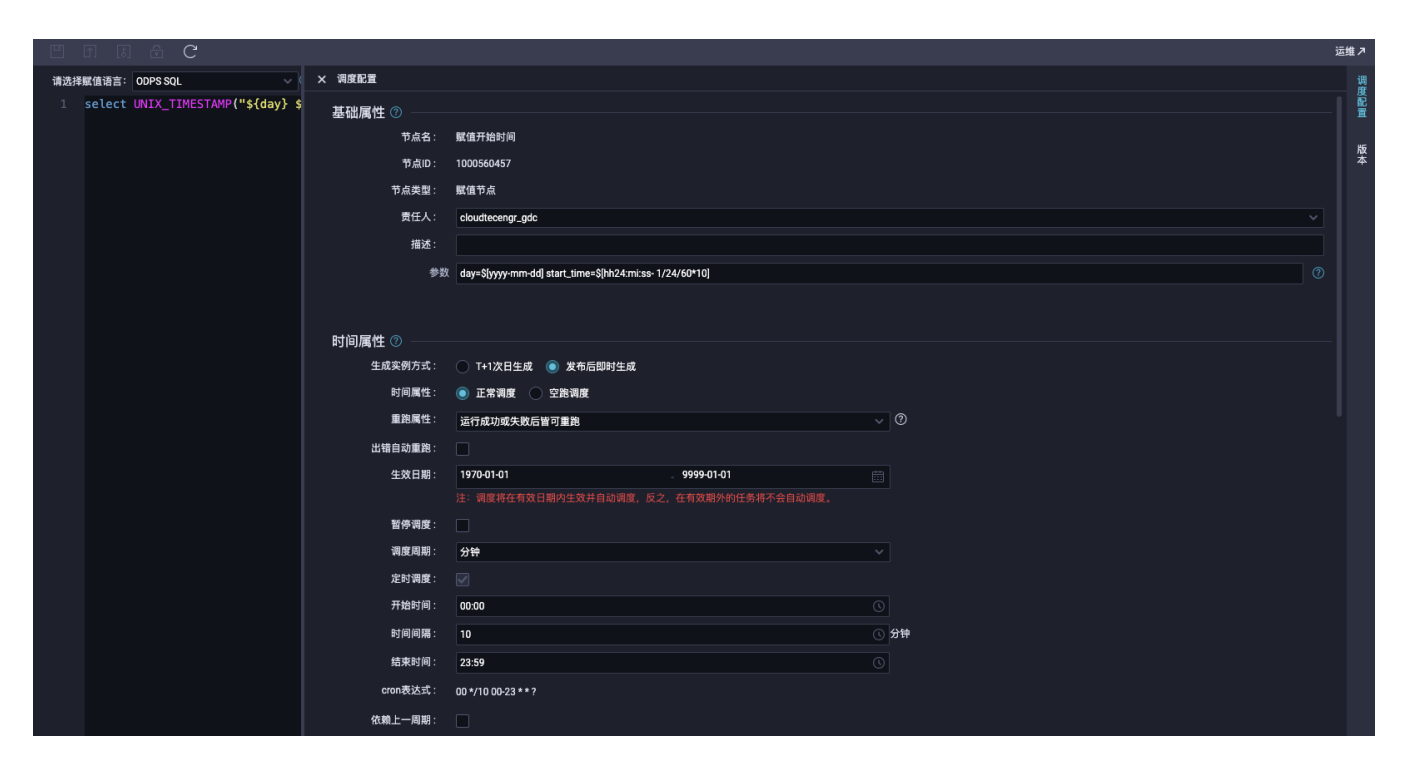 2、配置MongoDB同步节点添加本节点输入参数 start_time和end_time,取值自上游的两个赋值节点
2、配置MongoDB同步节点添加本节点输入参数 start_time和end_time,取值自上游的两个赋值节点 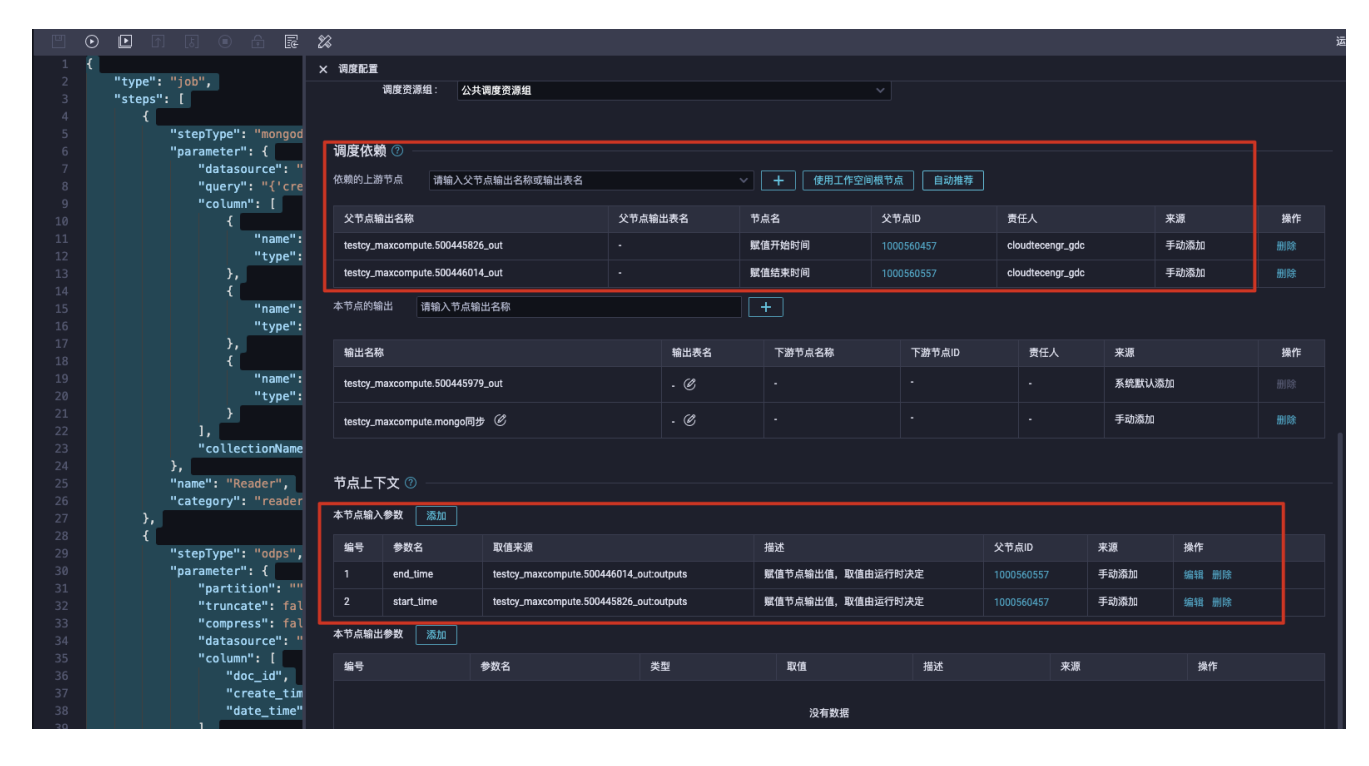 MongoDB原始数据:脚本模式配置示例代码,源端create_time是double类型,存的时间戳。
MongoDB原始数据:脚本模式配置示例代码,源端create_time是double类型,存的时间戳。 ""query"": ""{'create_time':{'$gte':unknown,'$lt':unknown}}"", 脚本配置示例 { ""type"": ""job"", ""steps"": [ { ""stepType"": ""mongodb"", ""parameter"": { ""datasource"": ""ds1"", ""query"": ""{'create_time':{'$gte':unknown,'$lt':unknown}}"", ""column"": [ { ""name"": ""doc_id"", ""type"": ""STRING"" }, { ""name"": ""create_time"", ""type"": ""DOUBLE"" }, { ""name"": ""date_time"", ""type"": ""DATE"" } ], ""collectionName"": ""test1"" }, ""name"": ""Reader"", ""category"": ""reader"" }, { ""stepType"": ""odps"", ""parameter"": { ""partition"": """", ""truncate"": false, ""compress"": false, ""datasource"": ""odps_first"", ""column"": [ ""doc_id"", ""create_time"", ""date_time"" ], ""emptyAsNull"": false, ""table"": ""tablename"" }, ""name"": ""Writer"", ""category"": ""writer"" } ], ""version"": ""2.0"", ""order"": { ""hops"": [ { ""from"": ""Reader"", ""to"": ""Writer"" } ] }, ""setting"": { ""errorLimit"": { ""record"": """" }, ""speed"": { ""throttle"": false, ""concurrent"": 2 } }} 此答案整理自钉群“DataWorks交流群(答疑@机器人)”"
""query"": ""{'create_time':{'$gte':unknown,'$lt':unknown}}"", 脚本配置示例 { ""type"": ""job"", ""steps"": [ { ""stepType"": ""mongodb"", ""parameter"": { ""datasource"": ""ds1"", ""query"": ""{'create_time':{'$gte':unknown,'$lt':unknown}}"", ""column"": [ { ""name"": ""doc_id"", ""type"": ""STRING"" }, { ""name"": ""create_time"", ""type"": ""DOUBLE"" }, { ""name"": ""date_time"", ""type"": ""DATE"" } ], ""collectionName"": ""test1"" }, ""name"": ""Reader"", ""category"": ""reader"" }, { ""stepType"": ""odps"", ""parameter"": { ""partition"": """", ""truncate"": false, ""compress"": false, ""datasource"": ""odps_first"", ""column"": [ ""doc_id"", ""create_time"", ""date_time"" ], ""emptyAsNull"": false, ""table"": ""tablename"" }, ""name"": ""Writer"", ""category"": ""writer"" } ], ""version"": ""2.0"", ""order"": { ""hops"": [ { ""from"": ""Reader"", ""to"": ""Writer"" } ] }, ""setting"": { ""errorLimit"": { ""record"": """" }, ""speed"": { ""throttle"": false, ""concurrent"": 2 } }} 此答案整理自钉群“DataWorks交流群(答疑@机器人)”"
MongoDB的时间戳类型是一个内部使用的数据类型,不能直接操作和修改。如果需要进行增量同步,可以考虑在文档中添加一个记录时间戳的字段,例如:
{ "_id": ObjectId("...") "name": "John", "age":30, "update_time": ISODate("2021-01-01T00:00:00.000Z") } 在进行增量同步时,可以记录上次同步的时间戳,查询出更新时间大于上次同步时间戳的文档,将这些文档同步到目标数据库中。同时更新记录的同步时间戳为当前时间。这样可以实现增量同步的功能。
你好,当MongoDB存储的增量字段为时间戳,可以通过赋值节点将时间类型字段通过引擎函数转换为时间戳,再传给离线同步任务使用。
DataWorks基于MaxCompute/Hologres/EMR/CDP等大数据引擎,为数据仓库/数据湖/湖仓一体等解决方案提供统一的全链路大数据开发治理平台。



