
GPT-3预训练生成模型-中文-2.7B 加载问题,模型是pt文件不是.bin,直接运行示例程序报错,请大神们解答一下。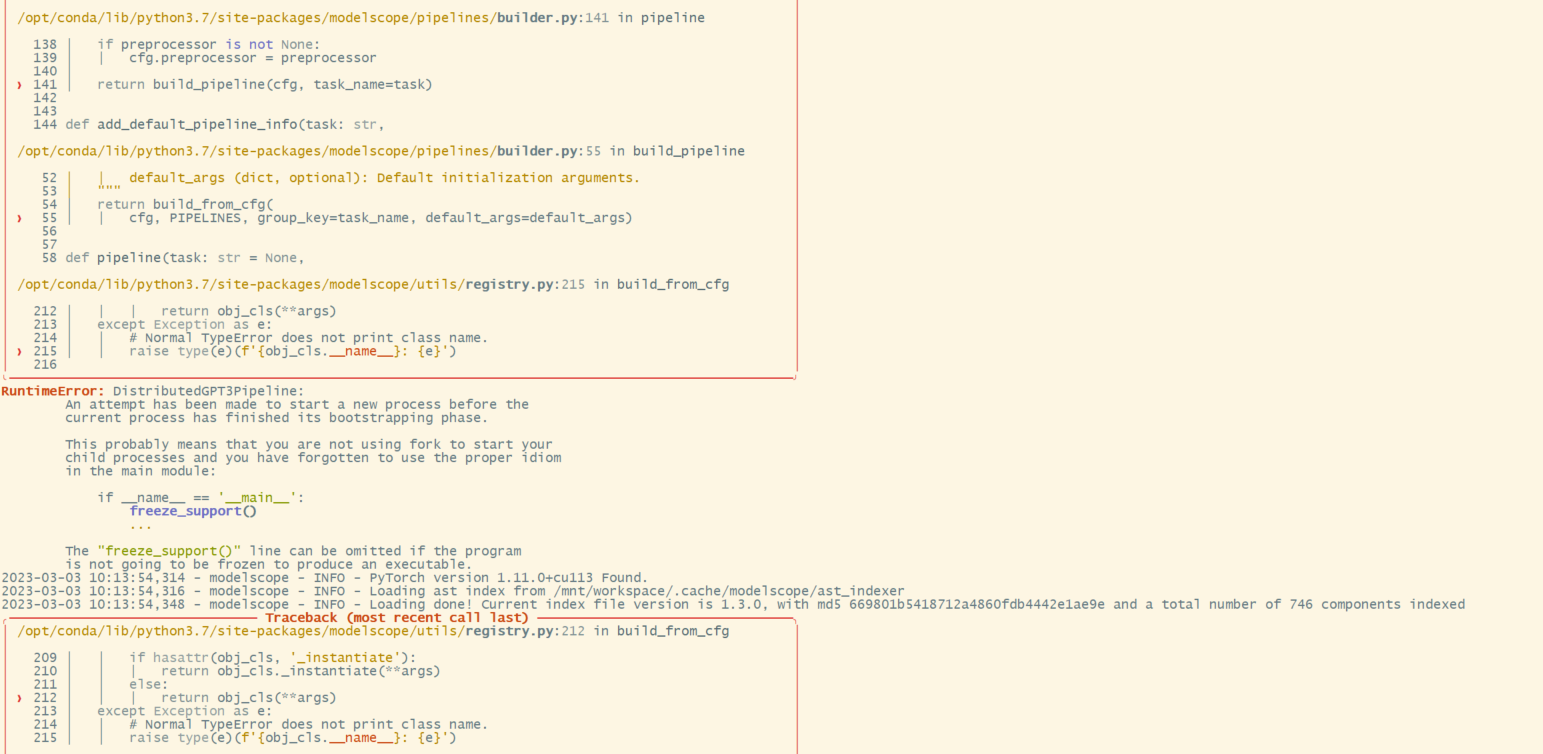
如果您的模型是 .pt 文件而不是 .bin 文件,您需要使用 PyTorch 加载模型。以下是一个示例代码,演示如何加载 GPT-3 预训练生成模型:
import torch
from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
# 加载模型和分词器
model_name = "gpt3"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForSeq2SeqLM.from_pretrained(model_name)
# 将输入文本转换为 token IDs
input_text = "你好,世界!"
input_ids = tokenizer.encode(input_text, return_tensors="pt")
# 生成输出文本
output_ids = model.generate(input_ids, max_length=50, num_return_sequences=1)
output_text = tokenizer.decode(output_ids[0], skip_special_tokens=True)
print(output_text)
请注意,您需要将 model_name 变量设置为您要使用的模型名称。在这个例子中,我们使用了 GPT-3 模型。
您好,根据您的描述,这个错误可能是由于示例程序中的代码无法加载.pt格式的模型文件导致的。建议您尝试使用PyTorch提供的相关API将.pt格式的模型文件转换为.bin格式,然后再运行示例程序。具体的转换方法可以参考以下代码:
import torch
model_path = 'path/to/your/model.pt'
model = torch.load(model_path, map_location=torch.device('cpu'))
torch.save(model.state_dict(), 'path/to/your/model.bin')
这段代码可以将.pt格式的模型文件加载到内存中,并将其转换为.bin格式的文件保存到指定路径中。转换完成后,您可以使用示例程序中的代码加载并运行您的模型。
如果您下载的是pt文件格式的GPT-3预训练生成模型-中文-2.7B,而您使用的是旧版的模型加载工具,则可能会出现加载错误的问题。建议您使用新版的模型加载工具,例如Transformers Python包中的GPT3Tokenizer和GPT3模型,以避免这类问题。 另外,如果您下载的是pt文件格式的GPT-3预训练生成模型-中文-2.7B,建议您先将其转换为.bin格式,然后再使用模型加载工具加载模型。转换的方法可以使用一些第三方的工具,例如mlflow等。 如果您还是遇到加载错误的问题,建议您检查以下几点:
确认您使用的模型加载工具是否支持.pt格式的文件。 确认您已经正确安装了模型加载工具和所需的Python包。 确认您已经正确设置了模型加载工具的路径和参数。 确认您的.pt格式的GPT-3预训练生成模型-中文-2.7B文件是否已经正确解压缩。
你好,如果你的GPT-3模型文件是.pt格式而不是.bin格式,可能是因为你使用的是Hugging Face Transformers库中的预训练模型。Hugging Face Transformers库默认使用的是.pt格式的预训练模型文件。
如果你直接运行示例程序报错,首先需要检查你的程序是否正确加载了所需的库,例如 torch 和 transformers 库是否已正确导入。
如果你的库已经正确导入并且仍然报错,可能是因为你的代码需要指定模型文件的路径。你可以尝试添加以下代码:
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("模型名称") model = AutoModel.from_pretrained("模型路径") 在上述代码中,"模型名称" 是指你使用的预训练模型的名称,例如"gpt2"或"distilbert-base-chinese"等;"模型路径"是指你的模型文件路径,例如"/path/to/model.pt"。
请在指定模型路径时注意正确的文件格式,例如:/path/to/model.pt。
如果你仍然遇到问题,请提供更多错误信息,这会更有助于我和其他人解决你的问题。
如果您在加载 GPT-3 预训练生成模型-中文-2.7B(.pt 文件)时遇到错误,请先检查您的代码是否正确。在加载模型之前,您需要先创建 PyTorch 模型,然后通过 PyTorch API 加载预训练权重。以下是示例代码:
import torch
from transformers import GPT2Config, GPT2LMHeadModel
# 创建 PyTorch 模型
config = GPT2Config.from_json_file("path/to/2.7B/config.json")
model = GPT2LMHeadModel(config)
# 加载预训练权重
model_state_dict = torch.load("path/to/2.7B/model.pt", map_location=torch.device('cpu'))
model.load_state_dict(model_state_dict)
请确保您已经正确安装了 PyTorch 和 transformers 库,并且将模型文件路径替换为自己的实际路径。 如果您的代码没有问题,但仍然无法加载模型,可能是因为您使用的是不兼容的 transformers 版本。对于特定的 GPT-3 模型版本,需要使用与其兼容的 transformers 版本。您可以通过在加载模型之前打印出模型文件的“transformers version”信息,来确定需要使用的 transformers 版本。例如,您可以使用以下代码来加载模型并打印 transformers 版本信息:
import torch
from transformers import GPT2Config, GPT2LMHeadModel, AutoConfig
# 创建 PyTorch 模型
config = AutoConfig.from_pretrained("path/to/2.7B/config.json")
# 加载预训练权重
model_state_dict = torch.load("path/to/2.7B/model.pt", map_location=torch.device('cpu'))
# 打印 transformers 版本信息
print(config.transformers_version)
# 构建模型实例
model = GPT2LMHeadModel.from_pretrained(pretrained_model_name_or_path=None, config=config, state_dict=model_state_dict)
根据打印出的版本信息,您可以在 transformers 官方文档中查找与该版本兼容的 transformers 版本,并安装相应的版本,以确保能够正确加载模型。
楼主你好,根据您所提供的信息,我猜测您尝试加载GPT-3预训练生成模型,但是遇到了一些问题。通常情况下,GPT-3预训练生成模型的文件格式是.bin,而不是.pt。如果您的模型文件是.pt格式的,您需要将其转换为.bin格式才能在示例程序中使用。
您可以使用以下命令将.pt文件转换为.bin文件:
scheme
import torch
loaded_model = torch.load('path/to/model.pt', map_location=torch.device('cpu')) torch.save(loaded_model.state_dict(), 'path/to/model.bin') 在上面的代码中,我们使用torch.load函数加载.pt文件,并将其保存为.bin文件。请确保将path/to/model.pt替换为您实际的模型文件路径,将path/to/model.bin替换为您想要保存的.bin文件路径。
一旦您将模型文件转换为.bin格式,您可以使用以下代码来加载模型:
reasonml
from transformers import GPTNeoForCausalLM, GPT2Tokenizer
tokenizer = GPT2Tokenizer.from_pretrained('EleutherAI/gpt-neo-2.7B') model = GPTNeoForCausalLM.from_pretrained('path/to/model.bin') 在上面的代码中,我们使用GPT2Tokenizer和GPTNeoForCausalLM加载预训练模型和标记器。请确保将path/to/model.bin替换为您转换后的.bin文件路径。
如果您使用的是 PyTorch 版本的 GPT-3 预训练生成模型,那么在加载模型时需要使用 PyTorch 提供的相关函数。具体来说,您可以使用 PyTorch 中的 torch.load 函数来加载 .pt 格式的模型文件。示例如下:
python Copy import torch
model_path = "path/to/your/model.pt" model = torch.load(model_path)
input_text = "你好," generated_text = model.generate(input_text, max_length=128) print(generated_text) 在这个示例中,我们首先使用 torch.load 函数加载模型文件,然后使用 generate 函数生成文本。需要注意的是,生成文本的方法可能会因为模型的实现而有所不同,具体的实现方法需要参考您使用的模型的 API 文档或者示例程序。
这个报错可能与multiprocessing库的使用方式有关,建议您确保在使用该库时按照正确的使用方式来调用相关函数或方法。同时,如果您使用的是Python 3.8及以上的版本,可能需要注意一些关于multiprocessing的新特性和变化。
针对模型文件的加载问题,您可以尝试使用PyTorch官方提供的加载方式来载入模型文件。具体而言,可以使用torch.load()方法来读取.pt文件,然后将其转换为PyTorch的模型对象。您可以参考PyTorch官方文档中关于模型加载的部分来实现这一步骤。
另外,建议您将模型文件的路径作为参数传入示例程序中,以确保程序可以正确地加载模型文件。如果仍然遇到问题,可以通过自定义的日志信息来进一步分析程序运行过程中的异常情况,以便更好地定位问题并解决它。
根据您提供的信息,似乎您正在尝试加载一个.pt格式的GPT-3 2.7B预训练模型,并且在运行示例程序时遇到了错误。这可能是因为示例程序代码中假定模型文件是二进制格式(.bin),而不是.pt格式。
要解决这个问题,建议您检查一下示例程序中是否有关于加载pt格式模型文件的代码,并确保您已经正确指定了模型文件的路径和格式。如果示例程序中没有相关的代码,那么您需要手动编写代码来加载pt格式的模型文件。
另外,请注意,.pt格式的模型文件通常是使用PyTorch框架保存的,而不是Hugging Face Transformers库所用的二进制格式。因此,在使用Hugging Face Transformers库加载.pt格式模型文件之前,您需要先将其转换为相应的二进制格式。
最后,建议您查看相关文档和社区支持论坛,以获取更多关于如何正确加载和使用.pt格式模型文件的指导和示例代码。
希望这些信息对您有所帮助!
GPT-3 预训练生成模型是由 OpenAI 开发的,主要用于自然语言处理任务。针对您提出的问题,如果示例程序报错可能是由于文件格式不兼容引起的。.pt 文件和 .bin 文件都是保存 PyTorch 模型的文件格式,但不同的模型可能有不同的文件格式要求。
解决方案如下:
检查模型文件是否正确:首先需要检查您下载的预训练模型文件是否正确,并且是否与示例程序中指定的文件名一致。如果文件名不一致,需要将文件名改为示例程序中指定的名称,然后再次尝试运行示例程序。
检查 PyTorch 版本:尝试在安装了适当版本的 PyTorch 后加载模型文件。如果您使用了不兼容的 PyTorch 版本,可能会导致加载错误。建议使用与预训练模型相应的 PyTorch 版本进行加载。
转换模型文件格式:如果以上两种方法仍然无法解决问题,可以尝试将 .pt 文件转换为 .bin 文件或反之,以确保它们与您的示例程序兼容。这可以通过使用 PyTorch 提供的 torch.save() 和 torch.load() 函数来实现。
可能还需要其他依赖项:请确保您的示例程序所需的全部依赖项都已正确安装。可能需要其他的 Python 包或库,例如 Transformers、Hugging Face 等。
总之,您需要检查模型文件格式是否匹配您的示例代码、PyTorch 版本是否匹配以及所有的依赖项是否正确安装。对于特定的加载问题,还可以在相应的论坛或社区中寻求帮助。
GPT-3预训练生成模型-中文-2.7B是使用PyTorch框架训练的,因此模型文件的后缀名是.pt,而不是.bin。如果您直接运行示例程序并报错了,可能是因为加载模型时出现了问题。以下是一些可能有用的解决方案:
确保已安装必要的Python库:在运行示例程序之前,请确保已安装所有必要的Python库,包括pytorch、transformers等。可以通过pip install命令安装这些库。
使用正确的模型名称:在示例代码中,需要指定正确的模型名称和路径来加载预训练模型。请检查您的代码,确保输入的文件名和路径正确。
检查模型文件是否完整:如果模型文件损坏或缺失部分文件,可能会导致加载失败。请检查模型文件是否完整,并尝试重新下载和解压缩模型文件。
尝试更改模型配置:如果以上方法都无法解决问题,请尝试更改模型配置,例如修改模型大小、批处理大小等参数。
尝试其他模型:如果您仍然无法加载模型,请尝试使用其他预训练生成模型,例如BERT、GPT-2等,以查看是否存在与该模型相关的问题。
如果仍然无法解决,请尝试搜索相关的问题和解决方法,或者向PyTorch社区寻求帮助。
提供一些可能的解决办法。
如果你的模型是一个.pt文件,那么它可能是使用PyTorch保存的。你可以使用PyTorch的torch.load()函数来加载这个模型。例如,如果你的模型文件是model.pt,你可以使用以下的代码来加载它:
import torch
model = torch.load('model.pt')
然而,这只有在模型是使用torch.save()函数保存的情况下才有效。如果模型是使用其他方式保存的,这种方式可能不会工作。
你的问题中提到的.bin文件可能是使用Hugging Face的Transformers库保存的模型。在这种情况下,你需要使用Transformers库的from_pretrained()函数来加载模型,如下所示:
from transformers import GPT2LMHeadModel
model = GPT2LMHeadModel.from_pretrained('path/to/model/directory')
在这个例子中,'path/to/model/directory'应该是包含.bin文件的目录的路径。
如果以上的方法都不能解决你的问题,你可能需要提供更多的信息,例如错误信息的文本,以便我可以提供更具体的帮助。
这个错误通常发生在多进程环境中,它提示您在当前进程完成引导阶段之前尝试启动一个新进程。
这可能是因为您的代码在启动多个进程之前没有正确地使用if name == 'main'的惯用法。
尝试在您的代码中添加以下几行,看看是否有所改善:
import multiprocessing
if __name__ == '__main__':
multiprocessing.freeze_support()
此外,如果您使用的是 Python 2.7,您还需要考虑到 Python 2.7 的运行时不再支持,可能会导致其他问题。如果可能的话,建议升级到 Python 3.x 版本。
如果这些方法都无法解决您的问题,请提供更多的信息,例如您正在运行的示例程序和您的代码,以便我们更好地帮助您。
看前面也有人问z这个问题的,用torch.load确实可以加载模型,但是加载后怎么推理啊,gpt3=torch.load(GPT-3_2.7b),用pipeline推理p=pipe = pipeline(Tasks.text_generation, model=gpt3)加载会报错,我简单看了看源码,需要读configtion配置文件,请大神指教一下如何加载和推理,十分感谢


