
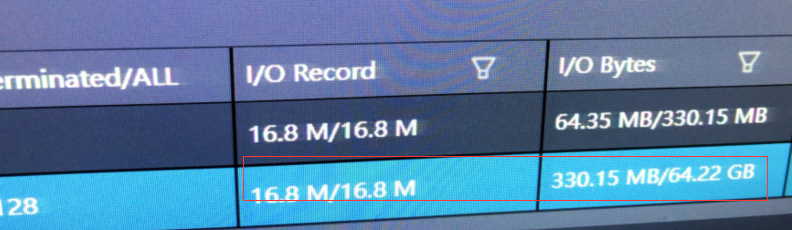
表格存储中用SQL写入,1600W数据,330M大小,耗时也得12分钟。读入是330M,但是输出是64.22G,就是select insert into from,不知道为什么读写数量大小有差异,而且差那么大呀?
MAP跟REDUCE两个阶段,我们各set了64的并行度,加到128也没写入速度提升。
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在您的问题中,您提到了使用表格存储执行SQL写入操作时遇到的两个主要问题:一是数据读写大小存在巨大差异,二是即使增加了并行度,写入速度也没有得到提升。针对这两个问题,我们可以从以下几个方面进行分析和解答:
可能原因分析:
数据膨胀:在执行SELECT INSERT INTO FROM这类操作时,如果涉及到的数据处理逻辑(如转换、计算或连接其他表)导致了数据体积的增加,这可能是输出数据远大于输入数据的原因之一。例如,数据重复插入、字段计算生成新数据等。
编码或格式变化:数据在写入过程中可能会因为编码格式的不同(如压缩与非压缩状态)而导致占用空间的变化。虽然原始数据为330M,但在数据库内部处理或存储时,因格式转换、字符编码等因素,实际占用空间可能增大。
可能原因分析:
数据分布不均:尽管您设置了较高的并行度,但如果数据本身分布不均匀,部分分区数据密集而其他分区空闲,那么增加并行度可能无法有效利用所有资源。确保数据在写入前充分打散,以利于并行处理。
系统瓶颈:除了并行度,还需考虑是否存在其他系统瓶颈,比如网络延迟、磁盘I/O限制或CPU利用率不足等,这些都可能限制了整体写入速度的提升。
SQL优化:复杂的SQL查询可能导致大量的数据扫描和处理,即使并行执行,也可能受限于查询本身的效率。检查SQL语句,避免全表扫描,合理利用索引可以减少处理时间。
审查SQL逻辑:详细检查您的SQL语句,确认是否有导致数据膨胀的操作,如不必要的JOIN、数据复制等,并尝试优化逻辑以减少输出数据量。
数据预处理:在导入大量数据前,先进行必要的数据清洗和预处理,确保数据格式和结构最优化,减少不必要的数据冗余。
优化并行策略:根据数据的实际分布情况,调整数据切分策略,确保并行任务能够均衡地分配到各个分区上,充分利用每个分区的预留吞吐量。
监控与调优:利用表格存储提供的监控工具,监控写入过程中的各项性能指标,如读写吞吐量、CPU使用率等,根据监控结果进一步微调参数。
考虑数据压缩:如果数据在传输或存储过程中有显著的膨胀,探索是否可以在不影响业务逻辑的前提下对数据进行压缩处理,减少存储和处理开销。
综上所述,解决您遇到的问题需要综合考虑数据处理逻辑、系统配置以及并行处理策略等多个方面,通过细致的排查和优化来提升数据处理效率。

