
请教下各位,不知道flink cdc同步mysql数据库的数据跟datahub、dataworks或者是hologres的关系。我现在想利用flinkcdc和hologres做实时数仓。flink cdc到holo 的方法不是很清楚。若果可以的话能否提供些demo或者资料,感谢,打扰了。
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
楼主,你可以直接通过DataWorks数据集成将数据库数据实时写入Hologress,由FLink实时订阅Hologress做进一步实时清洗,最后把结果更新到数据库,就可直接服务业务了。
https://developer.aliyun.com/learning/course/839/detail/14005 这个flink cdc实时大数据的应用demo的视频,可以参考一下
如果有dataworks的资源,可以跳过flinkcdc,采用dataworks的实时同步,原理没有深入过,不过应该也是通过读取mysql的binlog,对于数据新增,字段添加都可以直接同步,不过删除字段之前看的时候只有预警,然后在datawork的数据清洗之后,可以作为外部表进holo。 当然也可以跳过dataworks,holo的官方文档中有针对开源flink的实时写入demo,在项目中引入对应版本的connector,然后按照demo创建sink表,connctor写hologres,其他地方写对应信息,就可以通过sql+java实现写入操作。 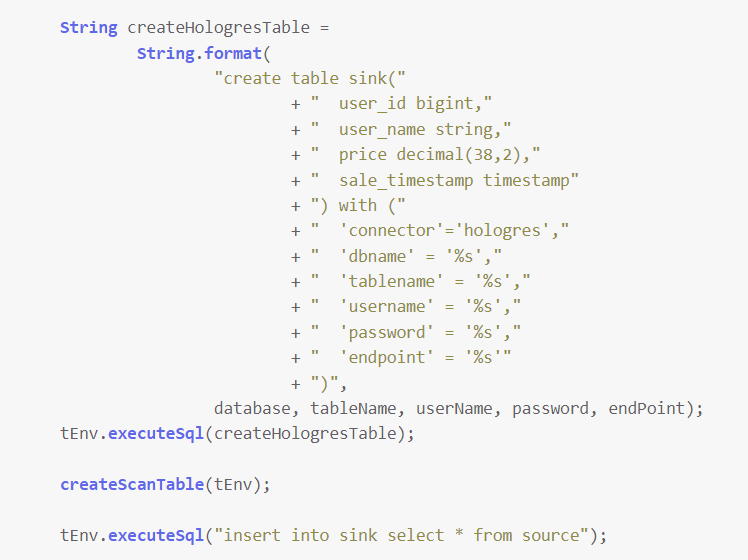
以往的架构:MySQL+Canal+MQ+PHP+Dataworks+Hologres;自研的消息中间件,成本高,过程复杂,对于有序的清洗要求极高; 新的架构:基于Hologres+Dataworks+Flink,直接通过DataWorks数据集成将数据库数据实时写入Hologres,通过FLink实时订阅Hologres做进一步实时清洗,把结果更新到数据库,即可直接服务业务; 总的来说,Flink和Hologres的实时数仓给我们带来了一条可能性的道路,统一的存储及统一的服务,有点小数据湖的概念,通过离线、小批、实时的数据处理,最终实现不同场景不同时效性的数据要求,方向是OK的。
同时,Dataworks的实时采集,基于本身的数据集能力,快速、易用,可以满足数据源不是太多的情况,大大节省了开发成本和运维成本,提升了团队的质量和效率。
基于Hologress+Dataworks+Flink,直接通过DataWorks数据集成将数据库数据实时写入Hologress,通过FLink实时订阅Hologress做进一步实时清洗,把结果更新到数据库,即可直接服务业务;整体架构清晰简单、数据精准、端到端纯实时、存储分析一体化、托管式运维、全自动工具作业,以往要3~4个月完成的项目,现在仅需几天即部署完成。具体教程找一下B站资料,看你不熟悉哪一块的内容,如果是小白要从最基础的框架学起,手动搭建,挺容易的 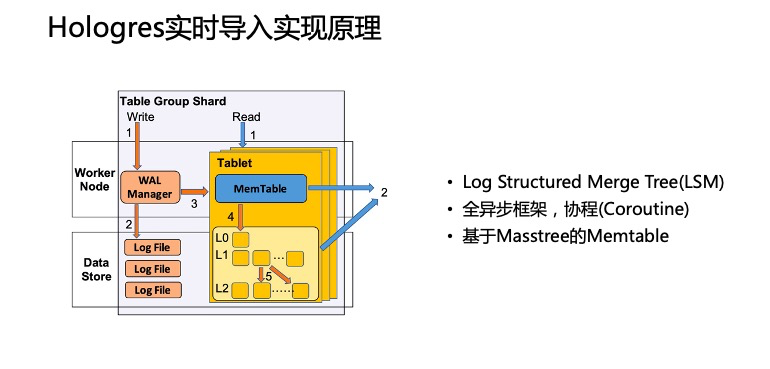
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。



