
为了解决这个问题,我们引入了 source 合并的优化,我们会尝试合并同一作业中的 source,如
为了解决这个问题,我们引入了 source 合并的优化,我们会尝试合并同一作业中的 source,如果都是读的同一数据源,则会被合并成一个 source 节点,这时数据库只需要建立一个连接,binlog 也只需读取一次,实现了整库的读取,降低了对数据库的压力。 --请问这个合并一个source节点的功能,是在哪个版本支持,需要做什么样的配置?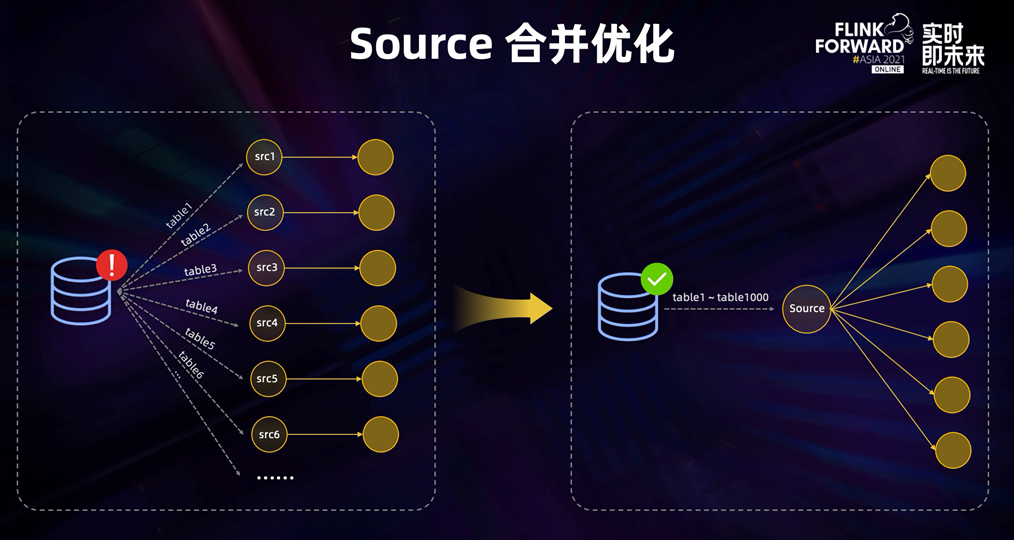
展开
收起
问答分类:
问答地址:
开发者社区
>
大数据与机器学习
>
实时计算 Flink
>
问答
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
相关问答

实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。
热门讨论
热门文章
有个关于scan.startup.mode的配置问题想问下
1026
Flink如何配置Task Manager?
893
请问如何用flink sql客户端用yarn application模式提交任务呢?
1727
FlinkCDC MySQL 中 scan.startup.mode 用的是什么模式啊?
3828
Flink CDC里我这边flink启动之后,爆了一个时区不匹配的错误,这个该如何解决?
376
Flink 集群重启后,所有的Jobs任务全都没有了。如果快速恢复所有的任务
1442
flinkcdc启动,怎么修改默认端口号,默认是8081。
1587
Flink sql将数组炸开,实现hive的explode函数的效果,还有什么其他好的方式?
1744
Flink这个未授权访问漏洞有什么解决方案吗?
1529
使用flink on yarn的模式,怎么进行内存资源调优呢,如何配置flink内存
844
展开全部
Flume+Kafka+Flink+Redis构建大数据实时处理系统:实时统计网站PV、UV展示
23554
Apache Flink 零基础入门教程(六):状态管理及容错机制
6108
Apache Flink 进阶(八):详解 Metrics 原理与实战
6293
实时计算在「阿里影业实时报表业务」技术解读
4851
基于实时计算(flink)打造舆情分析平台——新华智云
5229
如何在 Apache Flink 中使用 Python API?
5942
Lyft 基于 Flink 的大规模准实时数据分析平台(附FFA大会视频)
2817
最新消息!Cloudera 全球发行版正式集成 Apache Flink
2998
日均万亿条数据如何处理?爱奇艺实时计算平台这样做
2996
Flink Weekly | 每周社区更新-12/24
1621
展开全部



