
如何实现K8S Operator?
已解决如何实现K8S Operator?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
-
推荐回答
不管是原生YAML/Helm 还是Kustomize,都是通过配置来搞定各类事情。然而CRD+Operator 就不一样了,它们让你直接接入apiserver,作为K8S 的一部分监听所有你关心的对象,并通过代码进行状态维持及管理。因为CRD 的开发是非常复杂的,除了业务逻辑之外,还需要做很多基础的工作,非常不便,所以有了Operator的开发框架(常见的有KubeBuilder 和Operator-SDK),让开发人员专注于CRD的业务代码开发。
我们可以来看一下operator 的架构实现,这个有助于我们理解operator 的工作原理:
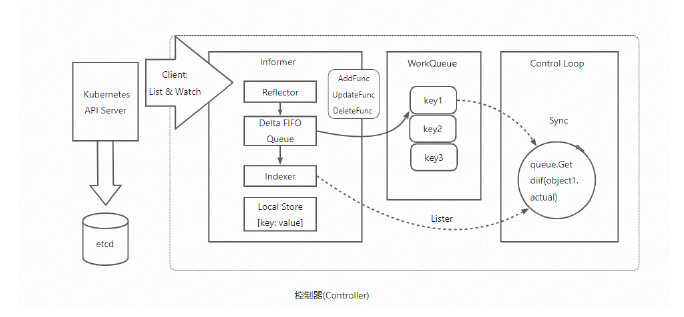
如图可知,Operator 内部有个控制器来监听CR 的变化,同时由于每个变化对应的函数执行需要一定的耗时,所以引入一个队列来依次执行这些函数。由于整个逻辑的执行链路不同于普通的web服务,所以也需要一个框架来承载请求的流转。
市面上的KubeBuilder 或Operator-SDK 开发框架可以降低Operator 的难度,但Operator 的开发在当前所有的几类组件托管方案当中仍然是最为复杂的。前前后后需要CRD 设计及安装,编译Operator 及部署到集群,最后再下发CR,外围为了配套这些内容可能还需要上面Helm 或Kustomize 的协助,配合对应的CICD 流程及工具。
• Spark Operator
Spark Operator 是大数据分布式系统在k8s 场景一次经典的实践。原本Spark 的作业提交是需要通过spark-submit 命令,但有了Spark Operator 之后,我们可以直接向k8s 提交作业YAML,然后Spark Operator 监听CR,将这一作业提交给控制器。实现了我们前文提到的,将作业资源放在k8s 集群进行管理这一目标。
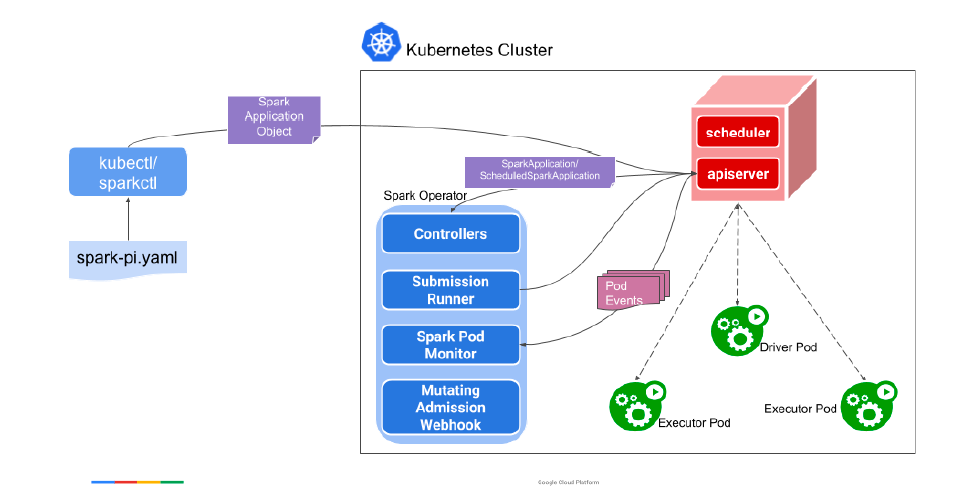
以上内容摘自《SREWorks 云原生数智运维工程实践》电子书,点击https://developer.aliyun.com/ebook/download/7784可下载完整版。
2022-10-19 17:52:46赞同 展开评论

