
CheckPoint失败排查方案是怎样的?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
当 checkpoint coordinator(job manager 的一部分)指示 task manager 开始checkpoint 时,它会让所有 sources 记录它们的偏移量,并将编号的 checkpointbarriers 插入到它们的流中。这些 barriers 流经 job graph,标注每个checkpoint 前后的流部分。Checkpoint n将包含每个 operator 的 state,这些 state 是对应的operator 消费了在 checkpoint barrier n之前的所有事件,当 job graph 中的每个operator 接收到 barriers 时,它就会记录下其状态。拥有两个输入流的 Operators(例如 CoProcessFunction)会执行 barrier 对齐(barrier alignment) 以便当前快照能够包含消费两个输入流 barrier 之前(但不超过)的所有 events 而产生的状态。
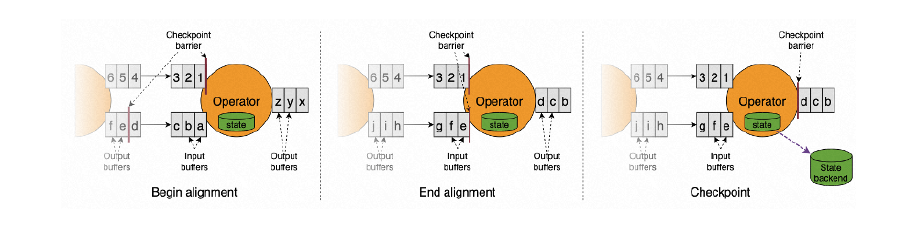
Flink 的 state backends 利用写时复制(copy-on-write)机制允许当异步生成旧版本的状态快照时,能够不受影响地继续流处理。只有当快照被持久保存后,这些旧版本的状态才会被当做垃圾回收。整体流程:
•JM trigger checkpoint
•Source 收到 trigger checkpoint 的 PRC,开始做 snapshot,并往下游发送barrier
•下游接收 barrier(需要 barrier 都到齐才会开始做checkpoint)
•Task 开始同步阶段 snapshot
•Task 开始异步阶段 snapshot
•Task snapshot 完成,汇报给 JM
以上内容摘自《企业级云原生白皮书项目实战》电子书,点击https://developer.aliyun.com/ebook/download/7774可下载完整版


