
云原生大数据计算服务 MaxCompute数据上云方面,数据集成同步解决方案是怎样的?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
有DataWorks等数据平台开发经验的大数据从业者对业务流程、DAG、调度编排等词汇耳熟能详,这些词汇都描述或提示了大数据开发的一般流程。通常数据开发的总体流程包括数据产生、数据收集与存储、数据分析与处理、数据提取和数据展现与分享。
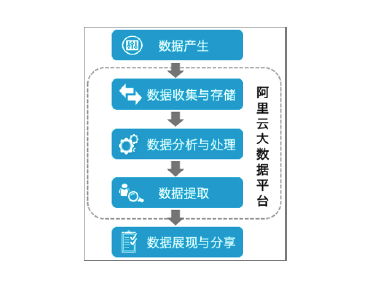
这里以DataWorks来举例说明,一般是需要在DataStudio数据开发页面中,创建某个分析需求的业务流程,然后在业务流程中配合使用各类节点(逻辑类、数据同步类、各类计算引擎节点等),最终将这些不同类型的节点,根据业务逻辑关系,编排成有向无环图(DAG)。
如果是简单的A表B表的周期离线同步,那只要在业务流程中添加一个离线同步节点,完整源端、目标端数据源配置及网络打通,基于脚本或向导配置好管道,即可完成。但实际业务场景下,数据同步通常不能通过一个或多个简单离线同步或者实时同步任务完成,而是由多个离线同步、实时同步和数据处理等任务组合完成,这就会导致数据同步场景下的配置复杂度非常高。
为了解决上述问题,DataWorks提出了面向业务场景的同步任务配置化方案(我们称之为同步解决方案),支持不同数据源的一键同步功能,例如,“一键实时同步至MaxCompute”、“一键实时同步至Hologres”功能等,通过此类功能,只需要进行简单的配置,就可以完成一个复杂业务场景。而通过传统的手工拖拽节点进行编排的方式,可能需要操作5+甚至10+个节点,配置项达到上百个(涉及周期、参数、依赖关系等各类配置)。
例如:一键实时同步至MaxCompute(独立merge天周期),可能包含了5个数据开发节点和2个资源文件。7个文件可以在一个解决方案向导中轻松配置完成。
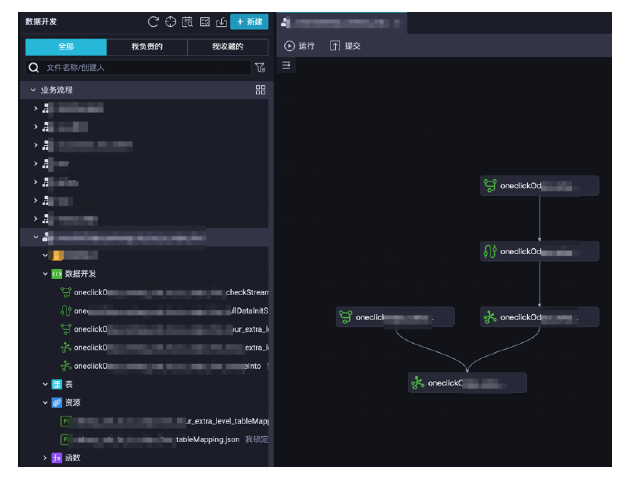
以上内容摘自《企业级云原生白皮书项目实战》电子书,点击https://developer.aliyun.com/ebook/download/7774可下载完整版
MaxCompute(原ODPS)是一项面向分析的大数据计算服务,它以Serverless架构提供快速、全托管的在线数据仓库服务,消除传统数据平台在资源扩展性和弹性方面的限制,最小化用户运维投入,使您经济并高效的分析处理海量数据。



