版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
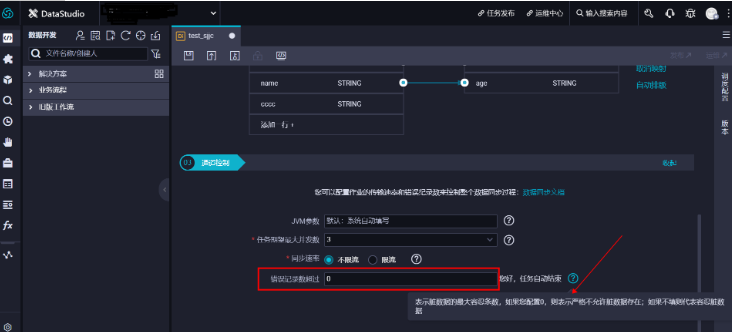
原因: 就是同步任务在任务运行过程中遇到插件的所有异常都会作为脏数据进行统计。 * 数据类型转换(源端表和目的表字段类型不匹配,大概率) * 源端表数据过长 * 数据源异常 * Reader/Writer插件异常 * 数据中有表情符
解决方法: 增大脏数据限制条数,扩大阈值,容忍脏数据(源端脏数据仍存在,不同步到目的端,日志会显示脏数据记录,任务不会报错)。
数据同步任务出现脏数据怎么办详见下面链接:
https://developer.aliyun.com/article/751514?spm=a2c6h.12873639.article-detail.12.2e142edcqDtYxn&share_token=b07f0d76-1ea7-4c15-a37e-f03ccfc4d8e8&tt_from=copy_link&utm_source=copy_link&utm_medium=toutiao_android&utm_campaign=client_share - 【全新系列】DataWorks百问百答-阿里云开发者社区 - 今日头条
这里对于你的问题不难理解,但是你的截图实在是太小,完全看不清内容,不好判断具体是什么问题导致的,那么基于此首先建议你可以参考官方文档【离线同步任务配置】,文档中涉及到多种离线同步任务配置方案来实现数据同步的源端到目标端数据库的需求,比如通过向导模式配置离线同步任务,参考文档:https://help.aliyun.com/document_detail/137718.html,或者通过脚本模式配置离线同步任务,参考文档:https://help.aliyun.com/document_detail/137717.html,以及通过OpenAPI创建离线同步任务多种方式选择,参考文档:https://help.aliyun.com/document_detail/321443.html,希望可以帮到你,如果你觉得没有用的话可以提供更清晰的图片方便问题的分析。
DataWorks基于MaxCompute/Hologres/EMR/CDP等大数据引擎,为数据仓库/数据湖/湖仓一体等解决方案提供统一的全链路大数据开发治理平台。