
源端脏数据(日期为1899年),debezium 解析完为负数(EFF_DATE:-2211696000000),这种数据,怎么设置kafka source,才能让flink 继续消费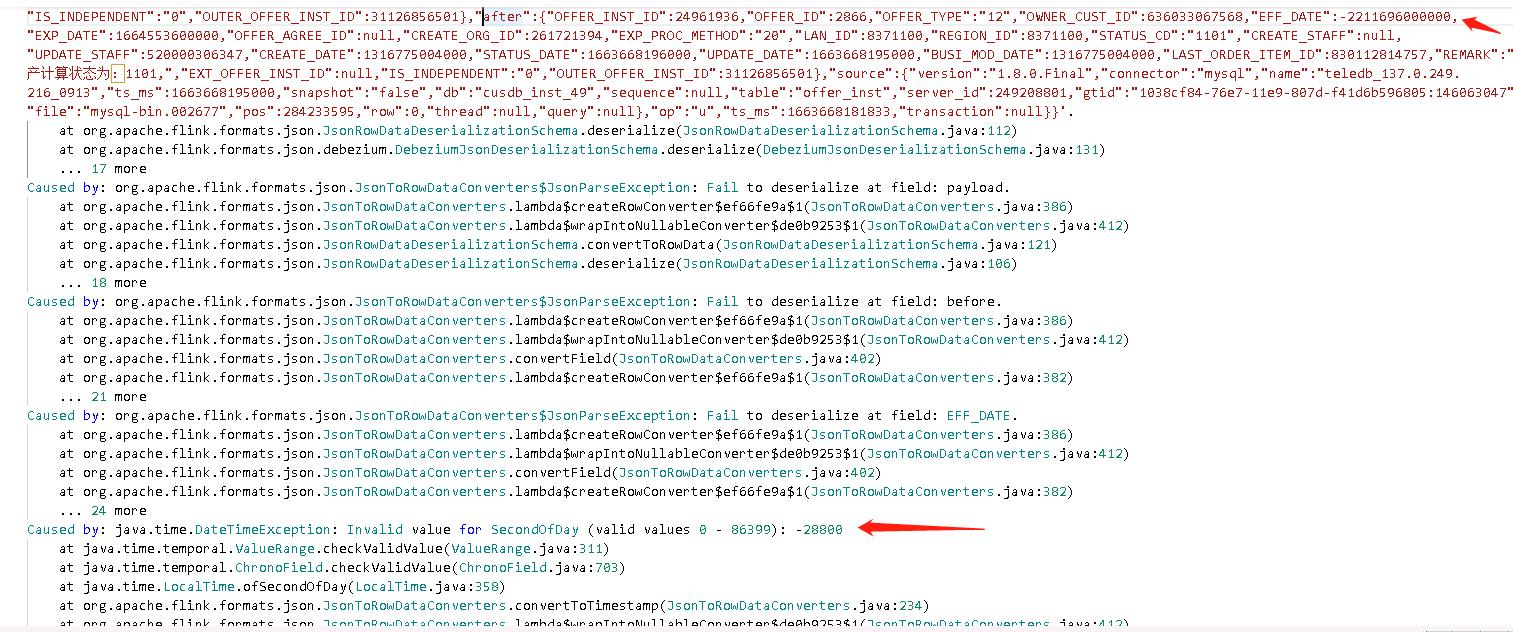
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
针对您遇到的源端脏数据问题,其中日期为1899年,经过Debezium解析后转换为负数(EFF_DATE:-2211696000000),要确保Flink作业能够继续消费这类数据而不中断,可以通过以下方式配置Kafka Source:
自定义反序列化器: 在构建KafkaSource时,使用自定义的反序列化器替换默认的反序列化逻辑。这样可以对消息体中的异常日期值进行特殊处理,避免因无法解析导致的消费中断。例如,在Java中,您可以实现DeserializationSchema接口来自定义处理逻辑。
public class CustomDateDeserializer implements DeserializationSchema<String> {
@Override
public String deserialize(byte[] message) throws IOException {
// 假设消息是JSON格式,这里简单示例处理逻辑
String msgStr = new String(message, StandardCharsets.UTF_8);
// 对msgStr中的日期字段进行检查和修正,如将异常日期转换为预定义值或进行告警记录
// 示例逻辑省略,请根据实际需求实现
return msgStr; // 或者返回处理后的字符串
}
@Override
public boolean isEndOfStream(String nextElement) {
return false;
}
@Override
public TypeInformation<String> getProducedType() {
return TypeInformation.of(new TypeHint<String>() {});
}
}
KafkaSource<String> source = KafkaSource.<String>builder()
.setBootstrapServers(brokers)
.setTopics("input-topic")
.setGroupId("my-group")
.setStartingOffsets(OffsetsInitializer.earliest())
.setValueOnlyDeserializer(new CustomDateDeserializer()) // 使用自定义反序列化器
.build();
错误处理策略: 在Flink作业中,还可以通过设置TableConfig或者在DataStream API中使用try-catch来捕获并处理由脏数据引起的异常,确保作业能优雅地处理这些情况而不停止消费。
// DataStream API 示例
env.addSource(source)
.map(new MapFunction<String, YourDataType>() {
@Override
public YourDataType map(String value) throws Exception {
try {
// 解析并处理数据逻辑
// ...
} catch (Exception e) {
// 处理解析异常,比如记录日志、发送告警或转换为默认值等
// ...
return null; // 或者返回一个默认值
}
}
})
// 其他算子操作
.filter(Objects::nonNull) // 确保过滤掉处理异常后返回的null值
.addSink(...);
通过上述方法,您可以有效应对源端脏数据问题,保证Flink作业从Kafka持续稳定地消费数据,同时对异常数据进行适当处理,避免直接中断流程。
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。


