
PolarDB-X导入必须先落文件然后再导入吗?能通过管道符之类的流式处理吗?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在PolarDB-X中,如果您需要导入数据,可以使用PolarDB-X提供的导入工具,例如polarx import。导入工具支持将数据从本地文件系统或者其他数据库导入到PolarDB-X中。
您需要将数据从本地文件系统导入到PolarDB-X中,可以先将数据落地到本地文件系统中,然后再使用导入工具将数据导入到PolarDB-X中。这是因为PolarDB-X的导入工具需要将数据读取到内存中进行处理,如果数据量过大,可能会导致内存溢出或者导入时间过长。
如果您需要通过管道符之类的流式处理将数据导入到PolarDB-X中,可以考虑使用PolarDB-X提供的数据同步工具,例如polarx sync。数据同步工具支持将数据从其他数据库或者文件系统同步到PolarDB-X中,可以通过管道符等流式处理方式进行数据传输。
不同的数据导入和同步方式可能会有不同的限制和要求,例如数据格式、数据大小、数据结构等。在使用导入和同步工具时,需要根据具体情况选择合适的方式,并且注意数据安全和数据完整性。

对于PolarDB-X,导入数据可以通过两种方式进行:文件导入和流式处理。
文件导入:首先,需要将数据落盘为文件,然后使用PolarDB-X提供的导入工具或命令将文件导入到数据库中。这种方式适用于数据量较大或需要离线处理的情况。
流式处理:PolarDB-X也支持通过管道符等流式处理方式进行数据导入。你可以使用类似于MySQL的LOAD DATA INFILE语句或者其他支持流式导入的工具,将数据直接通过管道符传输到数据库中。这种方式适用于实时或较小数据量的导入场景。
需要注意的是,具体的导入方式可能会受到PolarDB-X版本和配置的限制,建议查阅PolarDB-X的官方文档或咨询技术支持,以获取更准确的信息和操作指导。
PolarDB-X支持将数据通过管道符或者文件导入到数据库中,但是需要先将数据写入到一个文件中Batch Tool 工具就是我们开发的一套导入导出工具。
楼主你好,阿里云PolarDB-X支持通过管道符等流式处理方式导入数据,无需先落文件。您可以使用PolarDB-X支持的COPY命令来实现流式导入,具体操作步骤如下:
在PolarDB-X实例中创建一个目标表。
执行COPY命令,将数据流式导入到该表中。例如,以下命令将从test.csv文件中读取数据并插入到mytable表中: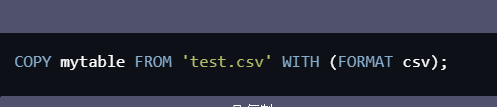
COPY mytable FROM 'test.csv' WITH (FORMAT csv);
为了实现流式处理,您可以使用STDIN作为数据源,例如: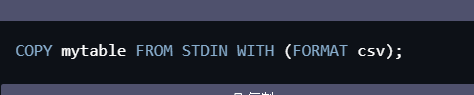
COPY mytable FROM STDIN WITH (FORMAT csv);
然后,可以将导入数据发送到标准输入流中,例如:
echo "1,John,Smith" | psql -c "COPY mytable FROM STDIN WITH (FORMAT csv)";
注意,需要在导入数据之前,确保表和数据类型等的定义与要导入的数据是一致的。
是的,PolarDB-X 支持通过流式处理的方式进行数据导入,您可以通过管道符(|)或其他流式处理工具将数据直接输入到 PolarDB-X 中。这种方式可以避免将数据先写入文件,然后再导入数据库,从而简化数据导入的过程,提高效率。
具体操作方法如下:
cat data.txt | polarximport -h 主机名 -P 端口号 -u 用户名 -p 密码 -D 数据库名 -t 表名
CopyCopy
PolarDB-X支持将数据通过管道符或者文件导入到数据库中,但是需要先将数据写入到一个文件中,然后再通过管道符或者文件导入到PolarDB-X中。
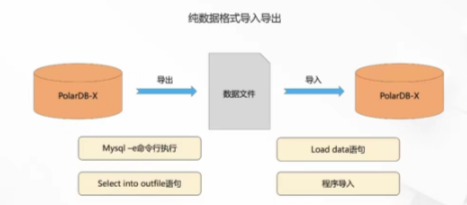
PolarDB-X常见的数据导出方法有:
Select into outfile 语句导出数据默认是关闭的,因为在向公有云,它由于是 CN 式不可访问的,用户连接不上,执行时直接存储到 CN 计算节点上而不是 MySQL cline 连接端上。Batch Tool 工具就是我们开发的一套导入导出工具。
PolarDB-X常见的数据导入方法有:
Source 语句也是 Mysql 的一个语法,Mysql 命令也能够导入数据。程序导入数据就比较好理解,像 jawl 通过 GDVC来连接上数据库,再拼凑成 insert 语句来执行,这也算一种导入数据的方式。Load data 语句也是 Mysql 语法中的一种。
PolarDB-X支持将数据通过管道符或者文件导入到数据库中。您可以使用--data-file参数指定数据文件的路径,或者使用--data参数指定数据的格式和位置,例如--data=stdin表示从标准输入中读取数据。
在导入数据时,PolarDB-X会将数据先写入到一个临时文件中,然后再将临时文件写入到数据库中。因此,您需要先将数据写入到一个文件中,然后再通过管道符或者文件导入到PolarDB-X中。
同时,PolarDB-X还支持使用--data-file参数指定多个数据文件的路径,以便一次性导入多个数据文件。您也可以使用--data参数指定数据的格式和位置,以便从标准输入中读取数据,并将数据写入到数据库中。
总之,PolarDB-X支持将数据通过管道符或者文件导入到数据库中,但是需要先将数据写入到一个文件中,然后再通过管道符或者文件导入到PolarDB-X中。
是的,PolarDB-X导入数据通常需要将数据先存储到文件中,然后再通过LOAD DATA语句或其他工具进行导入。这是因为PolarDB-X的导入操作需要对数据进行处理和验证,而直接从管道符或流中读取数据可能会导致处理和验证过程出现问题。
但是,如果您希望实现流式处理的方式来导入数据,可以考虑使用PolarDB-X提供的MySQL协议和API,结合编程语言中的MySQL客户端库来实现流式导入。您可以将数据以流的形式发送给MySQL客户端,并按照MySQL协议进行数据包封装和发送。
以下是一个示例代码(使用Python)来展示如何通过MySQL协议和流式处理来导入数据:
import mysql.connector
连接到PolarDB-X数据库
cnx = mysql.connector.connect(user='your_username', password='your_password',
host='your_host', database='your_database')
创建MySQL游标
cursor = cnx.cursor()
准备INSERT语句
insert_stmt = "INSERT INTO your_table (col1, col2, col3) VALUES (%s, %s, %s)"
准备数据流
data_stream = [
('value1', 'value2', 'value3'),
('value4', 'value5', 'value6'),
# ...
]
使用流式处理导入数据
cursor.executemany(insert_stmt, data_stream)
提交事务
cnx.commit()
关闭游标和连接
cursor.close()
cnx.close()
上述示例代码展示了如何使用Python中的mysql.connector库来实现流式导入数据到PolarDB-X数据库。您可以根据自己的实际情况和编程语言选择相应的MySQL端库。
PolarDB 分布式版 (PolarDB for Xscale,简称“PolarDB-X”) 采用 Shared-nothing 与存储计算分离架构,支持水平扩展、分布式事务、混合负载等能力,100%兼容MySQL。 2021年开源,开源历程及更多信息访问:OpenPolarDB.com/about


