
1
条回答
 写回答
写回答
-
 推荐回答
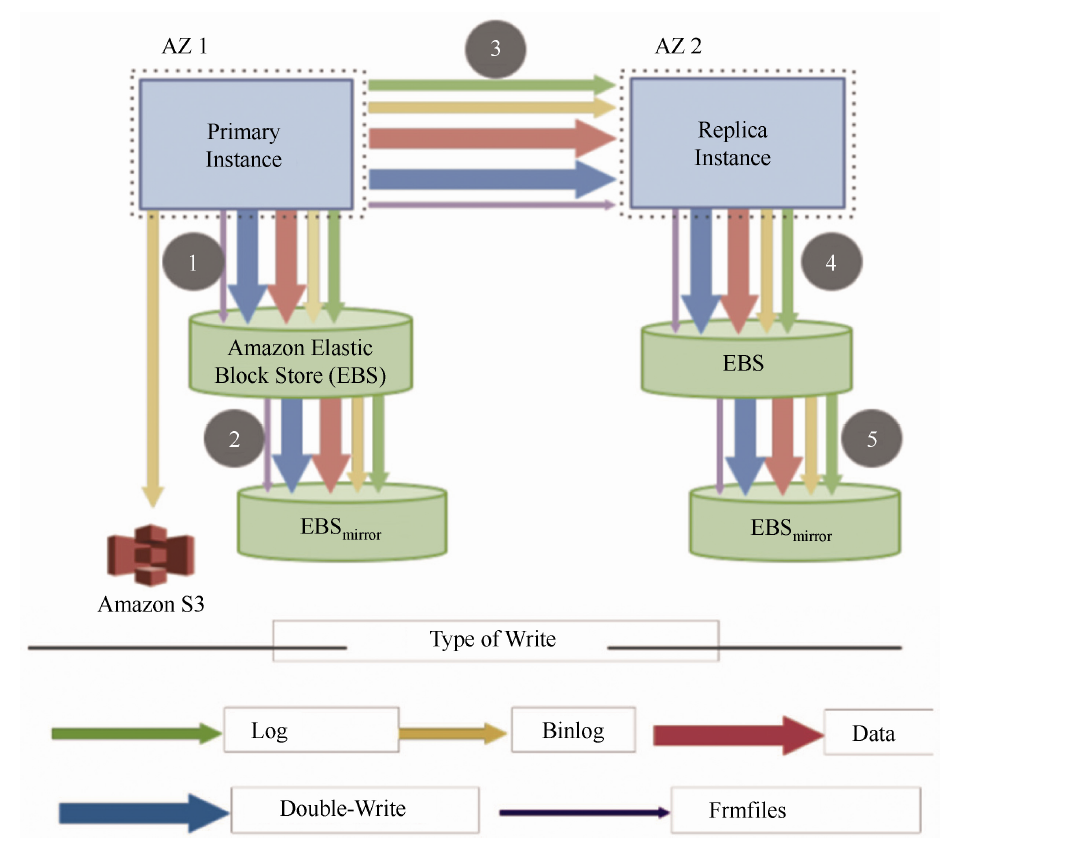
推荐回答传统数据库存在严重的写放大问题,以单机MySQL 为例,执行写操作会导致日志落盘,同时后台线程也会异步地将脏数据刷盘。另外,为了避免页断裂,进行刷脏页的过程还需要将数据页写入Double-Write 区域。如果考虑生产环境中的主备复制,如图下图 所示,AZ(Availablity Zone)1 和AZ 2 分别部署一个MySQL 实例做同步镜像复制,底层存储采用EBS(Amazon Elastic Block Store),并且每个EBS 还有自己的一份镜像,另外部署S3(Amazon Simple Storage Service)进行Redo 日志和Binlog 日志归档,以支持基于时间点的恢复。从流程上来看,每个步骤都需要传递5种类型的元数据,包括Redo、Binlog、Data-Page、Double-Write 和Frm。由于是基于镜像的同步复制,因此图中的步骤是①、③、⑤顺序执行的。这种模型的响应时间非常糟糕,因为要进行4 次网络I/O,且其中3 次是同步串行的。从存储角度来看,数据在EBS 上存了4 份,因此需要4 份都写成功才能返回。所以在这种架构下,无论是I/O 量还是串行化模型都会导致性能非常糟糕。
以上内容摘自《云原生数据库原理与实践》,这本书可以在电子工业出版社天猫店购买。
2022-09-12 11:44:12赞同 展开评论 打赏

版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
相关问答
热门讨论
热门文章
Google当年发表的“三驾马车”具体是指什么?
5757
你印象最深的一道SQL题目是什么?
4874
redis查看某个前缀键值数量
3843
RDS,DRDS,REDIS,ADS,ODPS之间的联系和区别是什么?
8467
PolarDB分区表中,多少条记录适合创建一个分区?
468
阿里云数据库PolarDB和MySQL有什么区别?
910
什么是多租户?
1478
数据合并指的是什么?
133
有了RDS,为什么要有DRDS,DRDS的功能是什么?
446
请问是否有sql语句之间相互转换的应用,比如mysql到oracle,或者oracle到hive。
636
展开全部
德哥的PostgreSQL私房菜 - 史上最屌PG资料合集
57116
redis4.0、codis、阿里云redis 3种redis集群对比分析
41569
NoSQL最新现状和趋势:云NoSQL数据库将成重要增长引擎
38460
什么场景应该用 MongoDB ?
56814
PostgreSQL 如何实现批量更新、删除、插入
54775
MongoDB Sharded cluster架构原理
41484
Redis Stream——作为消息队列的典型应用场景
34992
MongoDB 生态 - 可视化管理工具
36063
PostgreSQL upsert功能(insert on conflict do)的用法
47461
Linux 性能诊断 perf使用指南
48148
展开全部




