
各位老师,flink 1.13.6 cdc2.2.0 mysql to hive 2.1.1 不支持删除和更新吗? 不支持的话 flinksql 要怎么写只让新增呢? 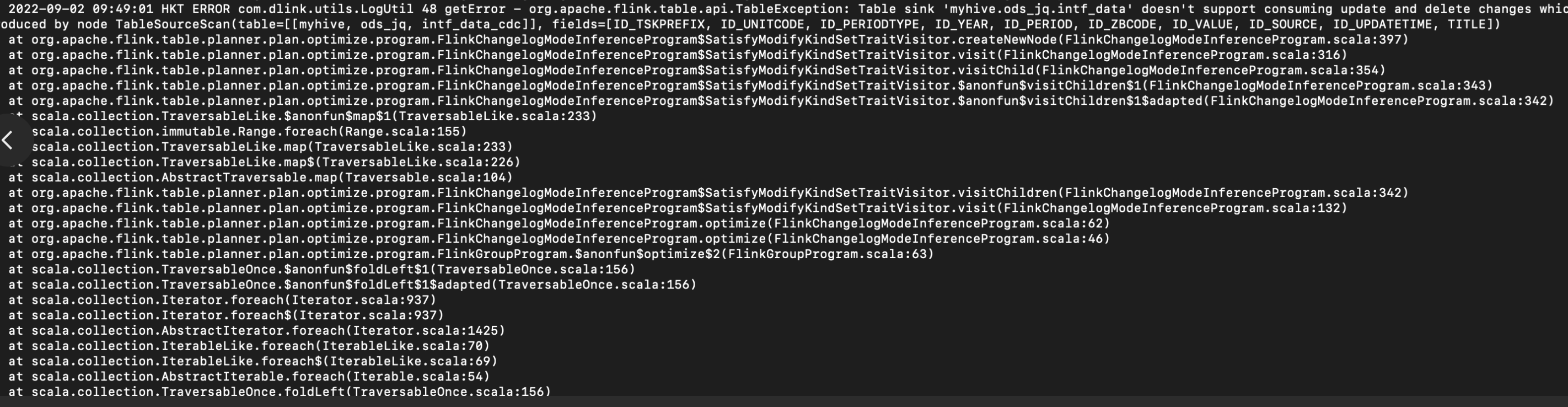
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
问题描述: 您提到在使用Flink 1.13.6版本的CDC 2.2.0从MySQL同步数据到Hive 2.1.1时,遇到了不支持删除和更新操作的情况,并希望了解如何配置Flink SQL以仅捕获MySQL中的新增数据。
背景信息:
解决方案: 要让Flink SQL作业仅捕获MySQL中的新增数据,您可以调整Flink CDC Source配置来忽略UPDATE和DELETE事件,仅关注INSERT事件。
步骤1:配置Flink CDC MySQL Source时,虽然直接过滤UPDATE和DELETE事件的功能不是标准配置项,但您可以通过自定义DeserializationSchema来实现这一需求。创建一个自定义的DeserializationSchema,该类继承自DebeziumDeserializationSchema,并重写deserialize方法,仅处理Insert类型的事件。
示例代码:
public class InsertOnlyDeserializationSchema extends DebeziumDeserializationSchema<YourDataType> {
@Override
public YourDataType deserialize(SourceRecord record) throws Exception {
if (record.topic().endsWith(".insert")) { // 或根据实际的逻辑判断是否为INSERT事件
return yourDataTransformationMethod(record);
}
return null; // 忽略非INSERT事件
}
// 其他需要实现的方法...
}
步骤2:在启动Flink任务时,使用上述自定义的DeserializationSchema配置MySQL Source。
注意事项:
总结: 通过实现自定义的DeserializationSchema来过滤掉非INSERT事件,您可以使Flink SQL作业专注于捕获MySQL中的新增数据。然而,请留意这种做法对数据一致性和系统设计的影响,并根据实际情况调整策略。
请注意,以上方案基于通用的Flink CDC与Hive集成逻辑提供,具体实施时需结合您的实际环境和版本进行适当调整。
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。


