
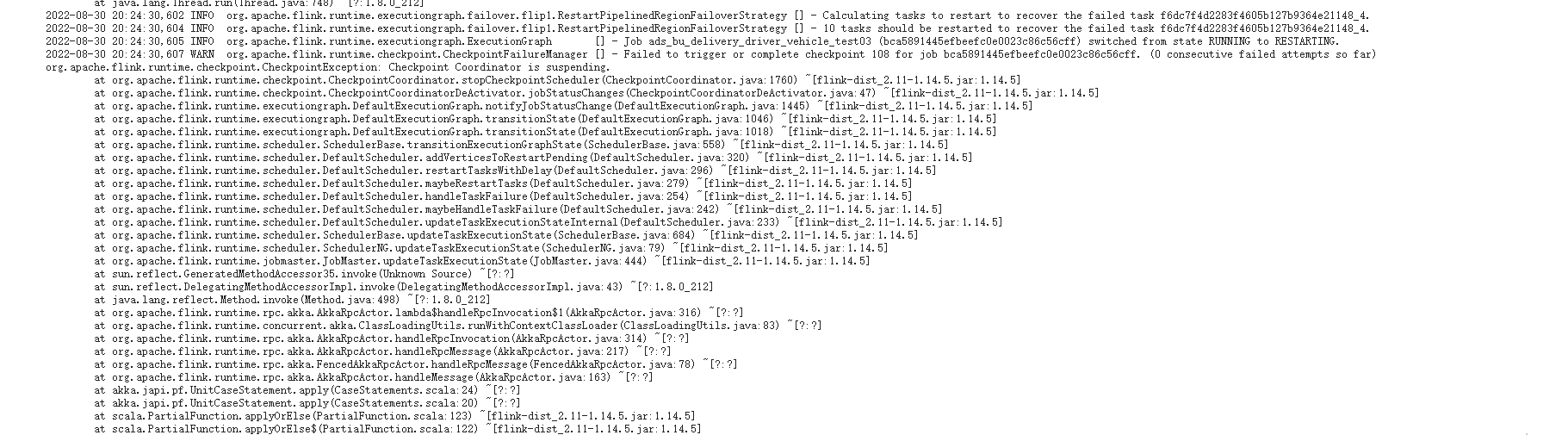
flink 任务提交后,task manager memory 一直打满,修改并行度和增大task managered 的内存,再次提交,仍然是打满的,运行一段时间后(1~2小时),然后报一下错误: 
 业务场景是,flink mysql cdc 监控任务左表的数据,通过jdbc对维表做lookup join,开启了rocksDB
业务场景是,flink mysql cdc 监控任务左表的数据,通过jdbc对维表做lookup join,开启了rocksDB
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
问题描述: Flink任务在提交后,Task Manager的内存持续打满。尽管您已尝试通过调整并行度和增加Task Manager内存大小后重新提交任务,但问题依旧存在。运行约1至2小时后,系统报错。业务场景涉及使用Flink MySQL CDC监控左表数据,并通过JDBC对维表执行lookup join操作,同时启用了RocksDB作为状态后端。
背景信息: - Flink CDC:用于捕获MySQL数据库的变化数据(如插入、更新、删除),常用于实时数据管道中。 - JDBC Lookup Join:在流处理中,用于关联流数据与静态数据源(如维表)的一种方式,通常涉及从数据库查询数据以丰富流记录。 - RocksDB State Backend:一种高性能的状态存储后端,适用于状态量较大的场景,能够将状态数据持久化到磁盘,提高系统的稳定性和容错能力。
解决方案: 1. 检查并优化连接数:确认您的Flink CDC作业是否处于全量数据拉取阶段,这可能导致大量连接被占用。考虑降低作业并发度、减小连接池Size或利用CDAS(如果适用)来复用连接资源。
优化SQL逻辑:审查lookup join的SQL逻辑,确保其高效且不会产生不必要的数据膨胀,导致内存消耗加剧。
RocksDB配置调优:检查RocksDB的状态后端配置,确保合理的内存分配给RocksDB使用,避免与其他组件争抢资源。可能需要调整state.backend.rocksdb.memory.managed等参数,让Flink自动管理RocksDB内存使用。
监控与资源分配:鉴于问题在一段时间后出现,需关注作业运行时的资源使用趋势,特别是GC行为和内存泄漏迹象。使用Flink提供的监控工具分析Task Manager的内存使用情况,适时调整内存分配策略。
维表缓存优化:根据业务需求,适当调整维表缓存参数,如lookup.cache.max-rows和lookup.cache.ttl,减少频繁的数据库查询,从而减轻内存压力。
检查数据倾斜:数据倾斜可能导致特定Task Manager负载过高。分析数据分布,必要时采用键值对重分区等手段均衡数据处理负担。
YARN资源限制:考虑到YARN模式下TaskManager至少占用2G内存的限制,确保您的资源配置未达到YARN的硬性限制,避免因资源请求不足而导致的异常。
注意事项: - 确保所有配置更改基于充分的测试,避免盲目增大资源分配而忽视根本原因。 - 监控GC活动,频繁的Full GC可能是内存分配不当或数据结构设计不合理的表现。 - 在进行任何配置调整前,备份当前设置,以便于回滚。
请依据上述建议逐步排查并优化,针对性地解决内存打满及后续错误的问题。
