
cdc 我修改了CustomerDeserialization implements DebeziumDeserializationSchema 修改会生成 2条数据,你们也是吗? 有人是一条数据吗?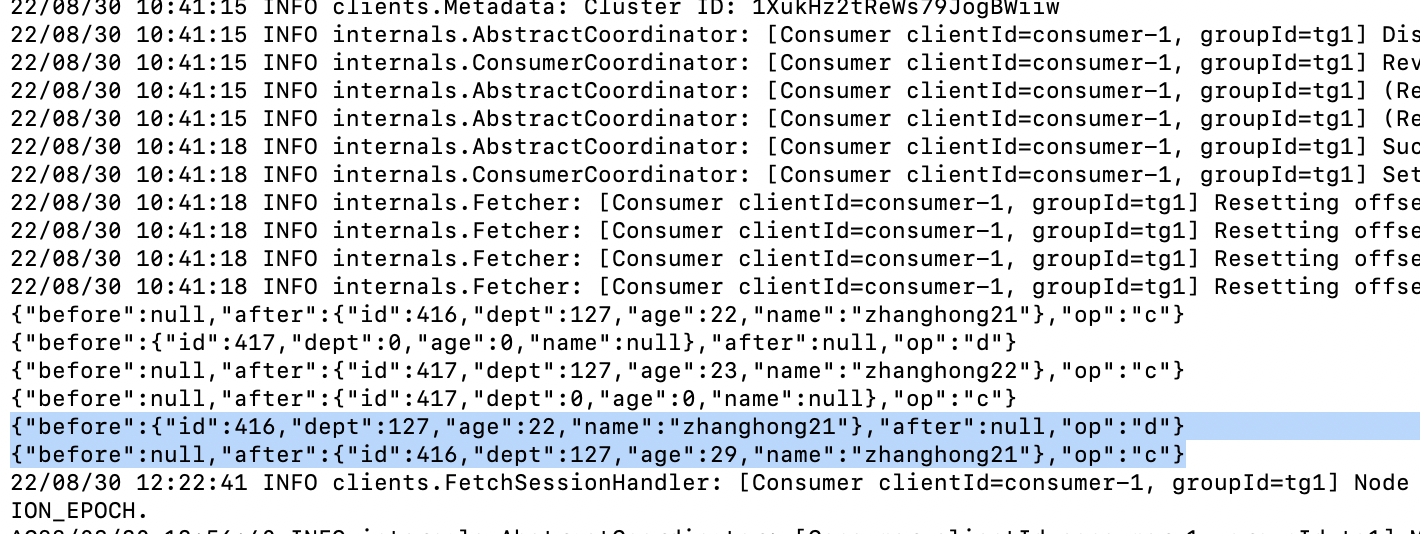
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在处理MySQL CDC数据时,如果您自定义了反序列化器(如您提到的CustomerDeserialization implements DebeziumDeserializationSchema),其行为将直接取决于您的实现逻辑。根据您的描述,如果修改后生成了2条数据,这可能是因为您的自定义逻辑在处理UPDATE类型的消息时,将其解析为了一次DELETE操作和一次INSERT操作,而不是直接处理成一条UPDATE消息。
Debezium默认处理UPDATE消息的方式是提供before和after的映射,即更新前后的记录状态。Flink SQL当前不直接支持将UPDATE消息表现为单个更新记录,而是会将其转换为DELETE和INSERT两个操作来模拟这一变更过程。因此,如果您没有特别处理以合并这两个变更事件,就可能导致看到两次数据插入的现象。
至于是否有人实现为生成一条数据,这理论上是可能的,但需要在自定义的反序列化逻辑中对UPDATE消息做特殊处理,手动合并before和after的状态到一个更新记录中,但这并不符合Flink SQL当前对Debezium UPDATE消息的标准处理方式。
总结: - 您遇到的情况(生成2条数据)与自定义反序列化器的实现逻辑有关,特别是对于UPDATE消息的处理。 - 虽然不是标准行为,但通过定制化实现,理论上可以调整为仅生成一条代表更新的数据记录。 - 默认及常见做法是遵循Flink SQL对Debezium UPDATE消息的处理规则,即转换为DELETE和INSERT两条记录。
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。


