
藏经阁2.0全新上线!下载本地、线上阅读让你轻松获取技术知识。为了让更多人学习到藏经阁中的优秀技术作品,培养好的阅读习惯,“藏经阁一起读”活动来啦,你阅读,我奖励!
阅读地址:https://developer.aliyun.com/ebook/7677
书籍简介:Databricks 主导着开源大数据社区 Apache Spark、Delta Lake 以及 ML Flow 等众多热门技术,而 Delta Lake 作为数据湖核心存储引擎方案给企业带来诸多的优势。本书从技术基础介绍到场景应用实践,帮助读者入门数据湖Lakehouse以及部分spark相关应用。
活动规则:阅读书籍,将你对于本书的想法、收获等在评论区留言,评论不少于200字,将选取评论质量最高的前2名送出小米鼠标Lite一个;点赞最多的第1名送出ET勋章一枚。


活动时间:2022年7月19日~7月25日14:00
参与用户务必扫码加入钉群,第一时间了解活动进展、获取得奖信息。

版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
你先搞清楚啥是Databricks数据洞察?原来是基于Spark的大数据分析平台 那你想凭什么来做分析我可以选其他厂家啊?是吧 1. 研发的是商业版全托管形式的Spark大数据分析&AI平台,来优化与节省成本 2. 与阿里云其他产品打通,提供数据安全,动态扩容等企业级的特性 3. 实现统一的数据湖和数仓存储,批流一体处理 4. 统一的数据工程和科学流程,能支持BI报表,ML与数据探索;
也看下整体结构啥样 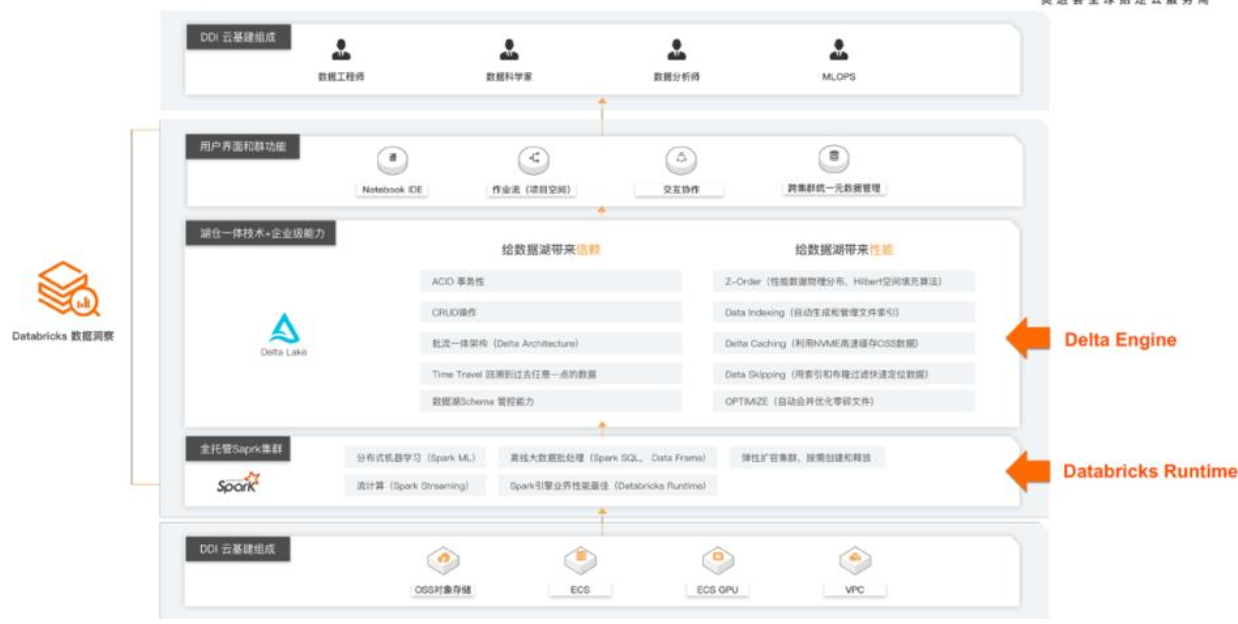
首先内核在Runtime基础上升级的,所以数据读写整体效率进一步提高,并且100%兼容Spark,OSS存储进一步降本,用JindoFS来加速OSS访问,最后是交互分析Notebook去更加聚集数据;好处太多不用多说,交互的BI或者ML,也解决好了批流处理,数据校验难的问题。
其次深挖场景数据;比如头部空调公司,从最开始的采集存储,ETL,再到数据科学,最后到BI分析或交互式分析整体解决方案,更好梳理并处理场景要解决的需求;然后Deltalake的历史,特点与数据湖存储深度解析,读完你肯定会对上层理解更加深入;但是也分析了Deltalake的不足简单了解下;最后是对Deltalake要了解它你必须了解基础知识并对事务日志,ACID进行操作下;
最后咱们Lakehouse在SQL性能得到哪些优化,高速缓存,建辅助数据结构与布局,克隆等非常详细讲解;然后用DeltaLake咋构建批流一体仓库?分析存在的问题,目标做成啥样有无参考?现在它能做成啥水平讲的很详细;最后用DDI+Confluent进行实时数据采集入湖分析案例拆解; 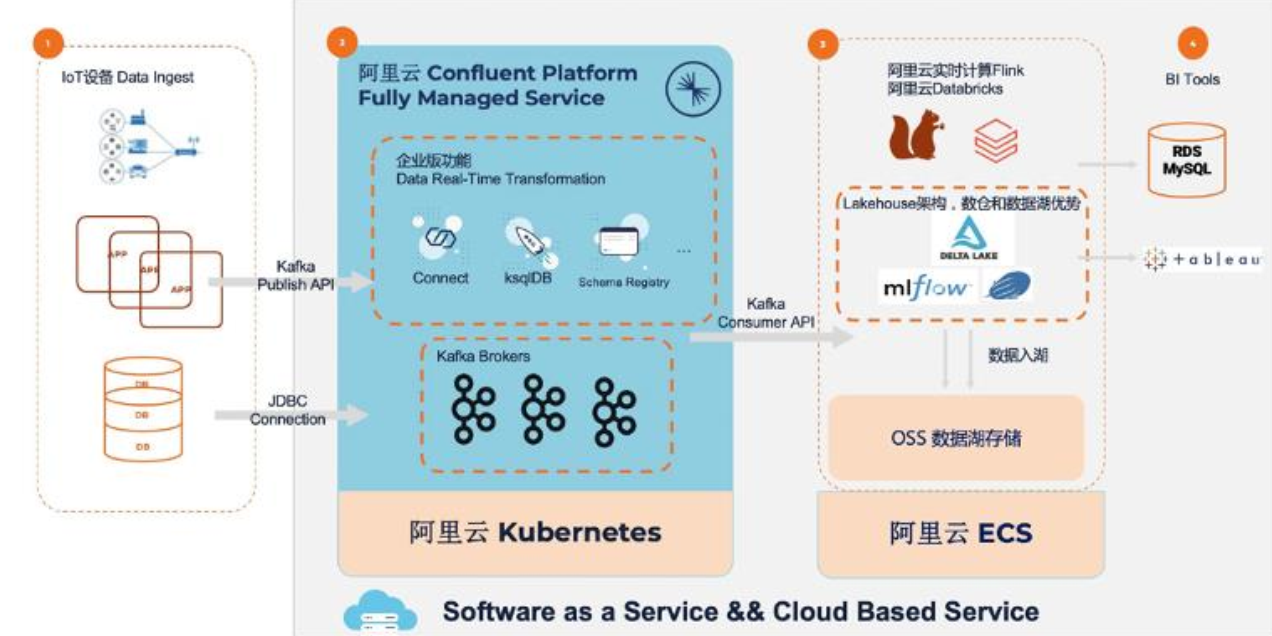 最后用Databrivks对零售进行合理预测,针对10家商店的50中商品之间进行组合与模型建立得出准确售出结果,最后联合MLflow进行机器学习的训练与部署实战,非常的赞!
最后用Databrivks对零售进行合理预测,针对10家商店的50中商品之间进行组合与模型建立得出准确售出结果,最后联合MLflow进行机器学习的训练与部署实战,非常的赞!
《Databricks数据洞察:从入门到实践》这本电子书从技术基础到场景应用实践,帮助读者入门数据湖Lakehouse以及部分spark相关应用,全书由浅入深,实用性非常高。 - 首先是介绍了Databricks数据洞察的核心优势,例如Saas全托管Spark、完整的Spark技术栈集成、集群总体使用成本低、以及有高品质的服务支持和SLA保障。 - 接着是深度了解数据湖Lakehouse的架构组成,从而可以帮助我们在后续产品使用过程中更好地利用其特性。Databricks将Delta Lake称为数据库湖,一种同时提供存储和分析功能的数据架构,这与以原生格式存储数据的数据湖和存储结构化数据的数据仓库的概念形成对比。 - 最后是基于四个热门场景给出详细的实操内容。分别是:数据采集入湖分析、需求预测、归因分析、交互式机器学习训练。从实践中可以看到Databricks数据洞察的经济效益是十分巨大的,尤其是其商业版,具体有以下几点: 1. 节省了DB从库的成本,同时节省了人力成本,若采用商业版Databricks数据洞察Delta Lake流批一体架构之后,整体成本将有效降低。 2. 商业版Databricks数据洞察Delta Lake的高效执行引擎,能够使执行效率获得最高10倍的性能提升。 3. 其实现了计算和存储分离,同时得益于其基于DLF元数据湖管理,可扩展性得到明显提高。 4. 最后一点是商业版Databricks数据洞察提供了一整套批流处理的Spark API,这将使企业的研发工作更加高效便捷。
什么是阿里云Databricks数据洞察?Databricks数据洞察(简称DDI)是基于Apache Spark的全托管大数据分析平台。产品内核引擎使用Databricks Runtime,并针对阿里云平台进行了优化。DDI为您提供了高效稳定的阿里云Spark服务,您无需关心集群服务,只需专注在Spark作业的开发上。Databricks数据洞察包含Spark SQL和DataFrames,Spark Streaming,MLlib,GraphX,Spark Core API这些组件 其优势包括:支持 ACID 交易和架构执行,提供了传统数据湖所缺乏的可靠性;Delta Sharing是业界首个安全数据共享的开放式协议,无论数据位于何处,与其他组织共享数据都变得简单,与Unity Catalog 的本地集成允许企业集中管理和审核跨组织的共享数据;在Apache Spark下,提供更大规模和速度;所有数据都以开放式 Apache Parquet 格式存储,允许任何兼容的API读取数据;Delta Live Tables,一个简单的方法来建立和管理数据;通过启用数据治理的细粒度访问控制来降低风险等,更多功能知识点可以阅读阿里云提供的《Databricks数据洞察:从入门到实践》这本书籍,可以帮助我们了解更多知识
Databricks数据洞察(简称DDI)是基于Apache Spark的全托管大数据分析平台,内核引擎使用Databricks Runtime,并针对阿里云平台进行了优化。DDI同时提供了高效稳定的阿里云Spark服务,无需关心集群服务,只需专注在Spark作业的开发上。DDI提供的DataInsight Notebook,可以使数据工程师、数据分析师和数据科学家共享集群计算资源、协同工作。 Databricks数据洞察包含以下组件:Spark SQL是用来处理结构化数据的Spark模块。DataFrames是被列化了的分布式数据集合,概念上与关系型数据库的表近似,也可以看做是R或Python中的data frame。Spark Streaming 实时数据处理和分析,可以用写批处理作业的方式写流式作业。支持Java、Scala和Python语言。MLlib 可扩展的机器学习库,包含了许多常用的算法和工具包。GraphX Spark用于图和图并行计算的API。Spark Core API支持R、SQL、Python、Scala、Java等多种语言。 产品内核使用Databricks商业版的Runtime和Delta Lake,在功能和性能上都有明显的优势。Databricks Delta Lake可以使用一套API接口同时处理批作业和流作业,达到事半功倍的效果。数据洞察Notebook为大数据分析提供了可视化、交互式的平台。用户可以在Notebook中编辑、执行、查看Spark作业。不同角色的用户可以共享集群资源和Notebook内容,协同合作。Databricks数据洞察采用数据湖分析的架构设计,使用阿里云对象存储服务(OSS)为核心存储,直接读取分析OSS的数据,无需对数据做二次迁移,实现数据在多引擎之间的共享。Databricks数据洞察提供了两种执行Spark作业的方式,包括通过Notebook或者在项目空间里新建Spark作业 同时使用阿里云对象存储OSS作为云上存储,DDI集群提供灵活的计算资源,OSS上的数据可以被多个DDI集群共享,减少数据冗余。同时,DataInsight Notebook支持多用户同时协同工作,您可以在Notebook中完成作业编辑、提交和结果查看。利用Databricks Delta Lake的ACID事务特性,可以构建云上大数据的实时数仓。Databricks Runtime完全兼容开源版本Spark,并且相对开源Spark引擎TPC-DS平均性能有3~5倍提升,性能对比最快的query有80倍提升!
1、首先了解到了Databricks数据洞察是什么,它是阿里云与Databricks联合开发研发的,100%兼容开源的spark,可以提供商业化的SLA保障及Databricks专家支持。最主要的就是可以与阿里云产品集成互通,提供安全、动态扩容,监控告警等企业级特性。可以接受收实时产生的流式数据和外部云存储上的批量数据,然后持续高效地处理增量数据,同时支持Ad hoc查询,Notebook可视化分析,无缝对接多种BI工具,也支持机器学习,Milb等Spark生态AI场景。相对于开始的Spark和Delta,在性能有非常大的提升。 2、其次知道了Lakehouse是什么?它的架构是数据湖和数据仓库的结合,是在数据湖之上抽象出了事务管理层,能够提供传统数仓的一些数据管理特性,还可以针对云对象存储中的数据做一些数据的性能优化。从而能够针对大数据时代各种复杂的分析场景提供支持,且对于流批两种场景能够提供统一的处理方式。 3、主要使用的四大场景有:数仓迁移或数据湖演进、构建LakeHouse方案、交互式BI、交互式ML训练。通过最佳实践可以看出Databricks数据洞察的效益:节省人力成本;执行效率性能呈线性提升;实现了计算和存储拆散,同时基于DLF元数据湖治理,可扩展性明显提高;一整套批流解决的SparkAPI使研发工作高效便捷了很多。

