
有没有大佬知道这个设置该怎么用
展开
收起
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
1
条回答
写回答
-
十分耕耘,一定会有一分收获!
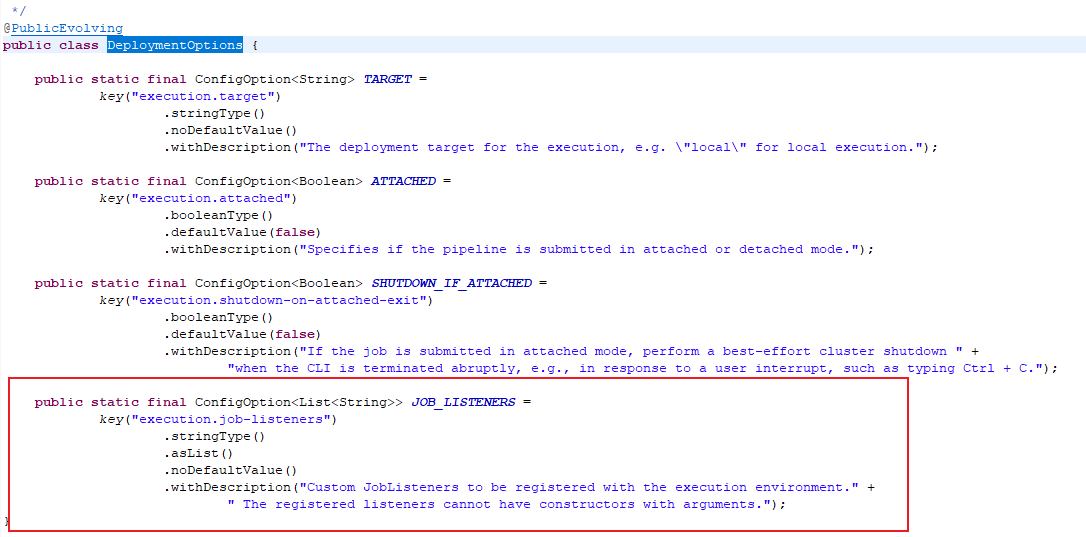
楼主你好,这段代码是阿里云的Flink程序中的一个设置。它的作用是在Flink作业执行环境中注册自定义的JobListeners,该JobListeners不能具有带有参数的构造函数。
具体的用法是:
- 在Flink作业中定义一个JobListener的实现类,该实现类必须没有带有参数的构造函数。
- 在阿里云的Flink作业配置中设置该ConfigOption,将JobListener的类名添加到list中。
- 启动Flink作业时,该JobListener就会被注册到作业执行环境中,从而可以监听Flink作业的运行状态。
例如,假设我们有一个自定义的JobListener实现类MyJobListener,它的类名为com.example.MyJobListener。那么,在阿里云的Flink作业中,我们可以这样设置:
public static final ConfigOption<List<String>> JOB_LISTENERS = ConfigOptions.key("job.listeners") .stringType() .asList() .noDefaultValue() .withDescription("Custom JobListeners to be registered with the execution environment, " + "The registered listeners cannot have constructors with arguments."); List<String> jobListeners = new ArrayList<>(); jobListeners.add("com.example.MyJobListener"); StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.getConfig().set(JOB_LISTENERS, jobListeners);这样,启动Flink作业时,MyJobListener就会被注册到作业执行环境中,从而可以监听Flink作业的运行状态。
2023-08-22 16:55:32赞同 展开评论

问答分类:
问答地址:
开发者社区
>
大数据与机器学习
>
实时计算 Flink
>
问答
相关问答

实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。
收录在圈子:

+ 订阅
实时计算 Flink 版(Alibaba Cloud Realtime Compute for Apache Flink,Powered by Ververica)是阿里云基于 Apache Flink 构建的企业级、高性能实时大数据处理系统,由 Apache Flink 创始团队官方出品,拥有全球统一商业化品牌,完全兼容开源 Flink API,提供丰富的企业级增值功能。
相关文章
热门讨论
热门文章
展开全部
展开全部
还有其他疑问?
咨询AI助理