
请问个问题: 1. flinkcdc监控tidb, 按照官网示例,打印时出现"\200\000\0
请问个问题: 1. flinkcdc监控tidb, 按照官网示例,打印时出现"\200\000\001\000\000\000\002\003\000\345\234\250", 如果用record.getValue().toStringUtf8() 或者 new String(record.toByteArray()) 就出现乱码了,2.相同代码重复运行多次后,就出现了异常, 切换监控表名后正常不报错, 但是切回原表后,数据可以监控出来,但还是在报相同的错误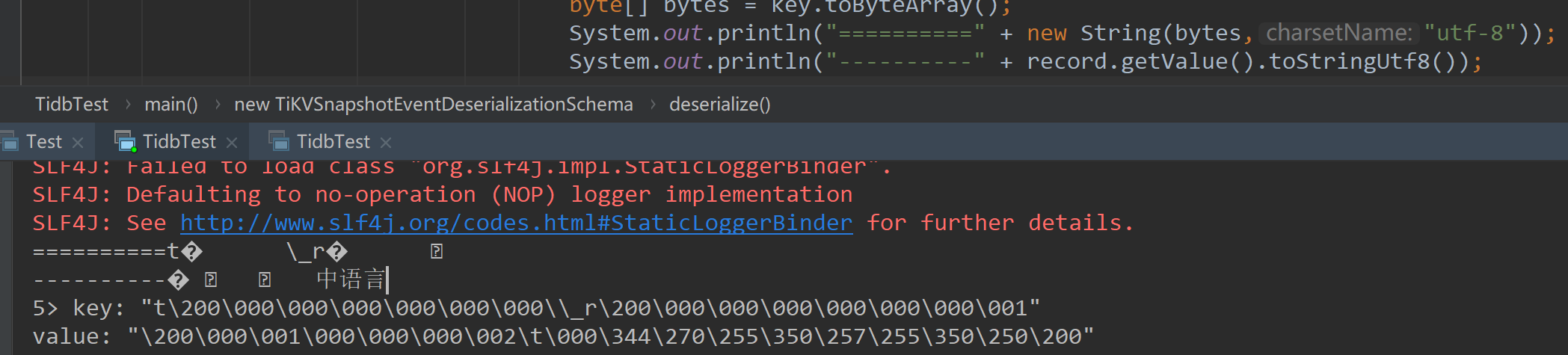

版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
针对您的问题,我将逐一进行解答:
1. Flink CDC监控TiDB时输出乱码问题
当您监控TiDB并尝试打印数据时遇到特殊字符(如\200\000\001...)以及使用record.getValue().toStringUtf8()或new String(record.toByteArray())方法出现乱码,这通常意味着数据的编码格式与您解析时所采用的编码不匹配。Flink CDC在处理数据时,默认可能使用的是UTF-8编码。为了解决乱码问题,您需要确保正确地解码数据。
解决方案建议: - 确认TiDB的数据存储编码,一般情况下应为UTF-8。 - 在处理字节流转换为字符串时,显式指定正确的字符集,例如:
new String(record.toByteArray(), StandardCharsets.UTF_8);
或者如果已经确认是其他编码,相应替换为正确的字符集。
2. 相同代码重复运行导致异常及切换表后行为变化
您提到相同代码多次执行后出现异常,但切换监控表后恢复正常,再切回原表虽然能监控到数据但仍报错,这可能涉及几个方面的问题:
-
资源泄露或状态未清理:多次运行可能导致某些资源未被正确释放,或者作业的状态管理出现问题。检查是否有连接、线程或其他资源未被妥善关闭。
-
表结构变更:尽管直接切换表名后能够正常工作,但在切回原表时仍报错,可能是因为原表在您初次监控和之后再次监控之间经历了结构变更(如列增删改),而Flink CDC作业未能正确适应这种变更。
-
Checkpoint或元数据不一致:多次运行过程中,可能存在Checkpoint不一致或元数据信息没有正确更新的情况,尤其是在作业失败重试机制下,可能会导致作业状态混乱。
解决策略: - 清理状态:在重新部署或调整监控表之前,彻底清理作业状态,包括删除相关的Checkpoint信息,以避免旧状态干扰新作业。
-
动态表结构适应:确保Flink CDC配置支持表结构变更的自动适应,比如通过设置Debezium的配置项来处理不一致的模式变更。
-
日志分析:详细查看Flink作业的日志,特别是错误日志,寻找具体的异常信息和堆栈跟踪,以便更精确地定位问题所在。
-
资源管理审查:检查应用的资源分配和管理逻辑,确保没有资源泄露,并优化作业的重启策略和资源回收机制。
请根据上述建议排查并尝试解决问题,如有进一步的具体错误信息,可提供更详细的描述以便获得更精准的帮助。您可以复制页面截图提供更多信息,我可以进一步帮您分析问题原因。

实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。
