
Hologres 收集统计信息效果如何?
已解决Hologres 收集统计信息效果如何?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
-
推荐回答
统计信息的收集存在一定局限,主要是针对非实时、手动触发或者周期性触发,不一定反映最准确的数据特征。需要先检查 explain 的信息,查看 explain 中包含的统计信息是否正确。统计信息中每个算子的 rows 和 width 表示该算子的行数和宽度。
未及时同步统计信息导致生成较差的执行计划,示例如下:
- tmp1 表的数据量为 1000 万行,tmp 表的数据量为 1000 行。 Hologres 默认统计信息中的行数为 1000 行,通过执行 explain SQL 语句,如下展示结果所示,tmp1 表的行数与实际的行数不符,表明该展示结果未及时更新统计信息。

- tmp1和tmp表Join时,正确的explain信息展示为数据量大的表tmp1在数据量小的表 tmp 上方,Hash Join 应该采用数据量小的 tmp 表。因为 tmp1 表未及时更新统计信息,导致 Hologres 选择 tmp1 表创建 Hash 表进行 Hash Join,效率较低,并且可能造成 OOM (Out Of Memory,内存溢出)。因此,需要参与 Join 的两张表均执行 analyze 收集统计信息,语句如下。
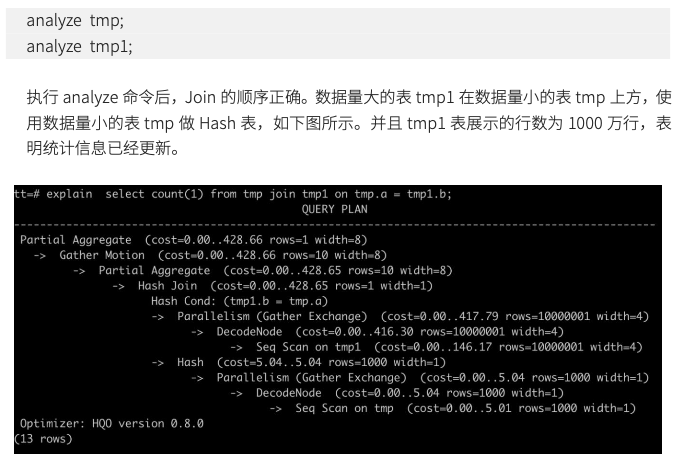
当发现 explain 返回结果中 rows=1000,说明缺少统计信息。一般性能不好时,其原因通常是优化器缺少统计信息,需要通过及时更新统计信息,执行 analyze tablename,可以简单快捷 优化查询性能。
推荐您在如下情况下运行 analyze tablename:
-
在导入数据之后。
-
在执行大量的INSERT、UPDATE以及DELETE操作之后。
-
内部表、外部表均需要ANALYZE。
-
分区表针对父表做ANALYZE。
-
如果遇到以下问题,您需要先执行 analyze table,再运行导入任务,可以系统地提升效率:
○ 多表 JOIN 超出内存 OOM。 通常会产生Query executor exceeded total memory limitation xxxxx: yyyy bytes used 报错。
○ 导入效率较低。 在 Hologres 查询或导入数据时,效率较低,运行的任务长时间不结束
优化器 Join Order 算法
- 当 SQL Join 关系比较复杂时,Join 的表多时,优化器消耗在连接关系最优选择上的时间会更多,调整 Join Order 策略,在一定场景下会降低 Query Optimization 的时间,设置优化器 Join Order 算法语法如下。

您也可以通过如下方式判断统计信息是否更新:
-
查询系统表hologres.hg_table_properties中的analyze_tuple列,确认数据的行数是否 正确。您也可以直接查看 Scan 节点中 rows 的值。
-
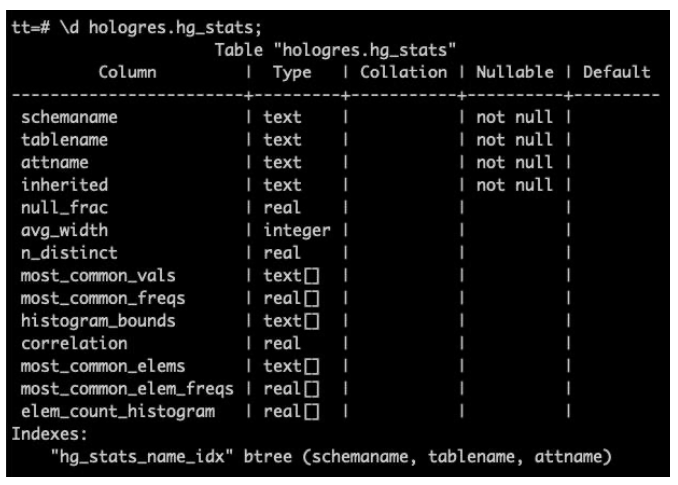
查询系统表hologres.hg_stats,显示每一列的直方图、平均宽度及不同值的数量等信息。 如下图所示。
说明:Hologres 从 0.10 版本开始,会在系统表 pg_stats 中记录相关统计信息。
《阿里云实时数仓Hologres》(下)电子书可以通过以下链接下载:https://developer.aliyun.com/ebook/download/7558
 2022-04-16 23:50:32赞同 展开评论
2022-04-16 23:50:32赞同 展开评论
