
vGPU 的热迁移技术是什么?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在 GPU 虚拟化的场景下,Host 上有物理 GPU 的驱动模块,可以操作和管理 vGPU 的物理资源,这里可以类比 KVM 对硬件资源的管理。此时 QEMU 可以通过驱 动模块获取 vGPU 的所有数据来实现热迁移的功能。 vGPU 支持热迁移硬件和软件上的关键点如下。
• 寄存器支持保存和还原。
• GPU 的显存(Framebuffer)硬件支持脏页跟踪 Dirty Track 功能。
• Framebuffer 的保存和还原要足够快。
vGPU 显存(Framebuffer)在热迁移流程中的处理方式和 System Mem 是一样的, 首先需要打开 GPU 的脏页跟踪功能,再在迭代拷贝阶段记录脏页。 在 vGPU 运行时,寄存器保留一些中间状态和上下文,在目的主机恢复 vGPU 调 度之前,如果要保证 vGPU 可以正常工作,能接着执行源端暂停的任务,那么需要在 目的主机把 GPU 的相关寄存器和上下文恢复。
GPU SR-IOV 和 GRID vGPU 两种 GPU 分片模式都是支持热迁移的,阿里云和 AMD 联合设计了基于 SR-IOV 分片 GPU 的热迁移架构,并在 2018 年 KVM Forum 上 做了分享和演示。图 3-33 是 vGPU 热迁移 QEMU 对 GPU SR-IOV 处理的时序图。
QEMU 在源主机通过 GIM API 修改 vGPU 状态、拷贝寄存器和 Framebuffer 的数 据,在目的主机恢复初始化 VF(vGPU)并恢复寄存器和 Framebuffer 的数据。
如图 3-34 所示,VM1 在 Host1 上使用 VF0,迁移到 Host2 上使用 VF1。当前 SR-IOV GPU 的驱动 GIM 把物理 GPU 的 Framebuffer 平均划分给 VF,这种方案简化 了迁移过程中 GPU pagetable 的映射。 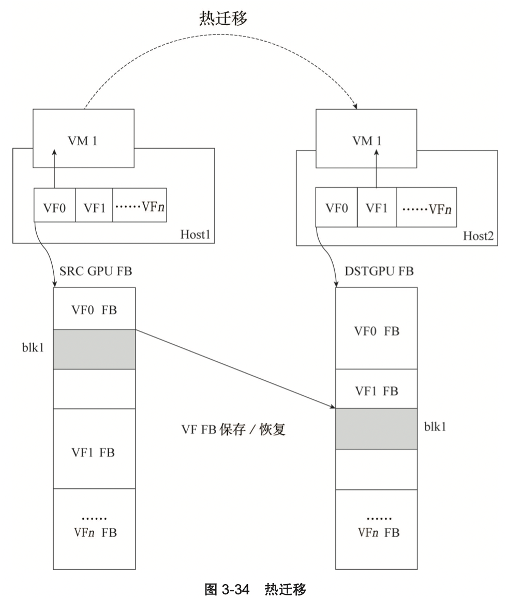
从 Host1 的 VF0 迁移到 Host2 的 VF1。blk1 的物理 GPU 的 Framebuffer 中的地址发生了变化,相对于 VF0 和 VF1 的基地址的偏移并没有发生变化。 目的主机GIM对VF1建立GPUpagetable的表项,GuestOS内的GPUDriver 对Framebuffer 的访问会被映射到 VF1 的指定的地址空间内。 在 VM 内部,迁移前后 Guest OS 看到的设备并没有发生变化。Guest OS 记录的 GPU 的设备上下文信息被保存 / 恢复之后,Guest OS 内的 GPU Driver 看到硬件设备 的状态没有发生改变,任务得以继续执行。
对于不支持脏页跟踪的 GPU 设备,我们设计了一套软件支持 GPU FrameBuffer Dirty 的方案,在迁移此类 GPU 设备时,可以将 Service Downtime 优化到原来的二十 分之一。对于中断丢失问题,热迁移采用的解决方案和热升级类似,重新给虚拟机注 入中断。
《弹性计算:无处不在的算力》电子书可以通过以下链接下载:https://developer.aliyun.com/topic/download?id=7996"

