
流式实时计算数据库是什么?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
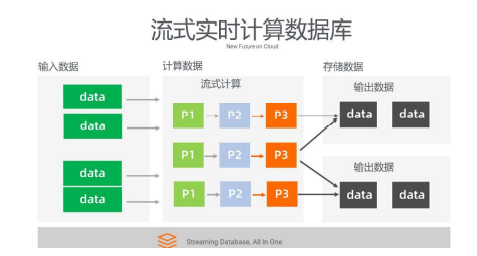
虽然 ES 也具备一些实时的处理能力,但它有很明显的局限性。比如它不支持非常精确 毫秒级的处理。抛开这个限制,我希望有一种数据产品既可以充当 Kafka 的角色,也能支 持流式数据进来。我可以编写简单的 SQL 处理函数在上面做一些计算,经过 Pipeline 可 以支持很多函数,同时这些数据又可以再回到数据库里去消化掉,这个数据库同时又可以对外提供查询或者其他的能力。其实我想探讨的就是这个思维,all in one,我们需要一个叫 做 Streaming Database 的概念,希望有一个流式数据库,把数据的 in 和 process,还 有数据的 output 全部融在一起,让整个编程模型变得简单高效。
资料来源于《开源与云Elasticsearch应用剖析》下载地址:https://developer.aliyun.com/topic/download?id=1169
