
ES Rollup Pipeline是什么?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
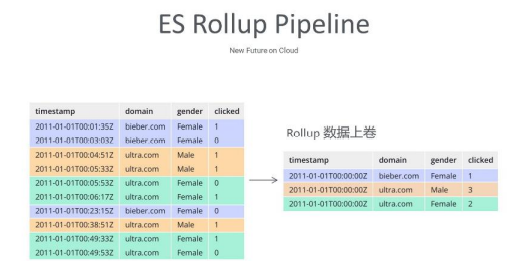
Rollup,即数据上卷,图中左边大家看到数据有三种颜色,这些数据表示的是一个点 击事件,记录某一些用户点击的事件,性别。在原始的数据里,我们可以想象,假设做一个 网站或系统,pv、uv 的统计,每天可能有上 10 亿的数据量,但是我们分析需求的时候实 际上只需要分析今天什么时候哪个域名点击了多少次,这个我们可以通过 Rollup 这个概念 把数据做一次转换,压缩。到右边,我们的数据就已经精确到天或者按小时。对于 ES 来说, 它其实也是遵循三个关键步骤:第一,原始数据输入到 Elasticsearch 里存起来,中间开 启一个 Rollup 实时计算的能力,然后把数据经过一定的折叠之后,输出到另外一个索引, 这样就完全满足了 Pipeline 的思维,也完全满足了实时计算。所以在这个领域, ES 算做 了一个伟大的创新,只需要一套去处理,就可以把管道模型深切地融入到自己的数据里。如 果基于 Flink 做数据统计,上游会先用 Kafka 输入数据,然后中间用 Flink 计算,比如每 1000 条,每 1 万条数据就 Rollup 一下,然后输出到另外一个下游又会放到 ES 里来存储, 这就会带来技术的成本,实施的代价。
资料来源于《开源与云Elasticsearch应用剖析》下载地址:https://developer.aliyun.com/topic/download?id=1169
