
现有流计算的问题是什么?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
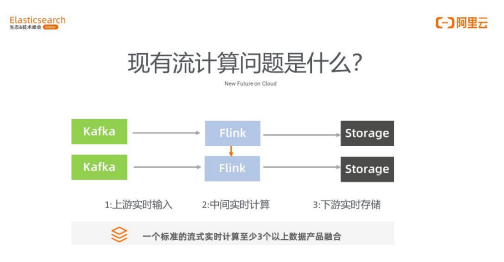 第一,现在基本上大部分企业都会选择 Kafka ,中间选择 Flink,下游根据应用程序 逻辑有可能还需要下一步的处理,会放到 Kafka,也可能最终不需要处理,需要给 Elasticsearch 做最终查询。目前来说 Elasticsearch 在数据查询方面是领先的,在这个 领域里是最好用的。我们在做一个标准的实时流计算的时候,基于 Pipeline 会需要输入- 处理-输出,也就是去搭建一个哪怕是轻量级的实时数据处理计算都需要融入至少三个产 品,会带来什么问题?大家可以想象,在 IT 里做系统架构等等,每增加一个处理的环节, 增加一个节点,或者每增加一个大型的数据系统融入进来,这个系统的复杂性就会增加好几 倍,并且数据架构的可靠性也会降低。同时,这三个产品对于研发人员和对架构师的考验非 常大,不能保证很快就可以完成。
第一,现在基本上大部分企业都会选择 Kafka ,中间选择 Flink,下游根据应用程序 逻辑有可能还需要下一步的处理,会放到 Kafka,也可能最终不需要处理,需要给 Elasticsearch 做最终查询。目前来说 Elasticsearch 在数据查询方面是领先的,在这个 领域里是最好用的。我们在做一个标准的实时流计算的时候,基于 Pipeline 会需要输入- 处理-输出,也就是去搭建一个哪怕是轻量级的实时数据处理计算都需要融入至少三个产 品,会带来什么问题?大家可以想象,在 IT 里做系统架构等等,每增加一个处理的环节, 增加一个节点,或者每增加一个大型的数据系统融入进来,这个系统的复杂性就会增加好几 倍,并且数据架构的可靠性也会降低。同时,这三个产品对于研发人员和对架构师的考验非 常大,不能保证很快就可以完成。
资料来源于《开源与云Elasticsearch应用剖析》下载地址:https://developer.aliyun.com/topic/download?id=1169
