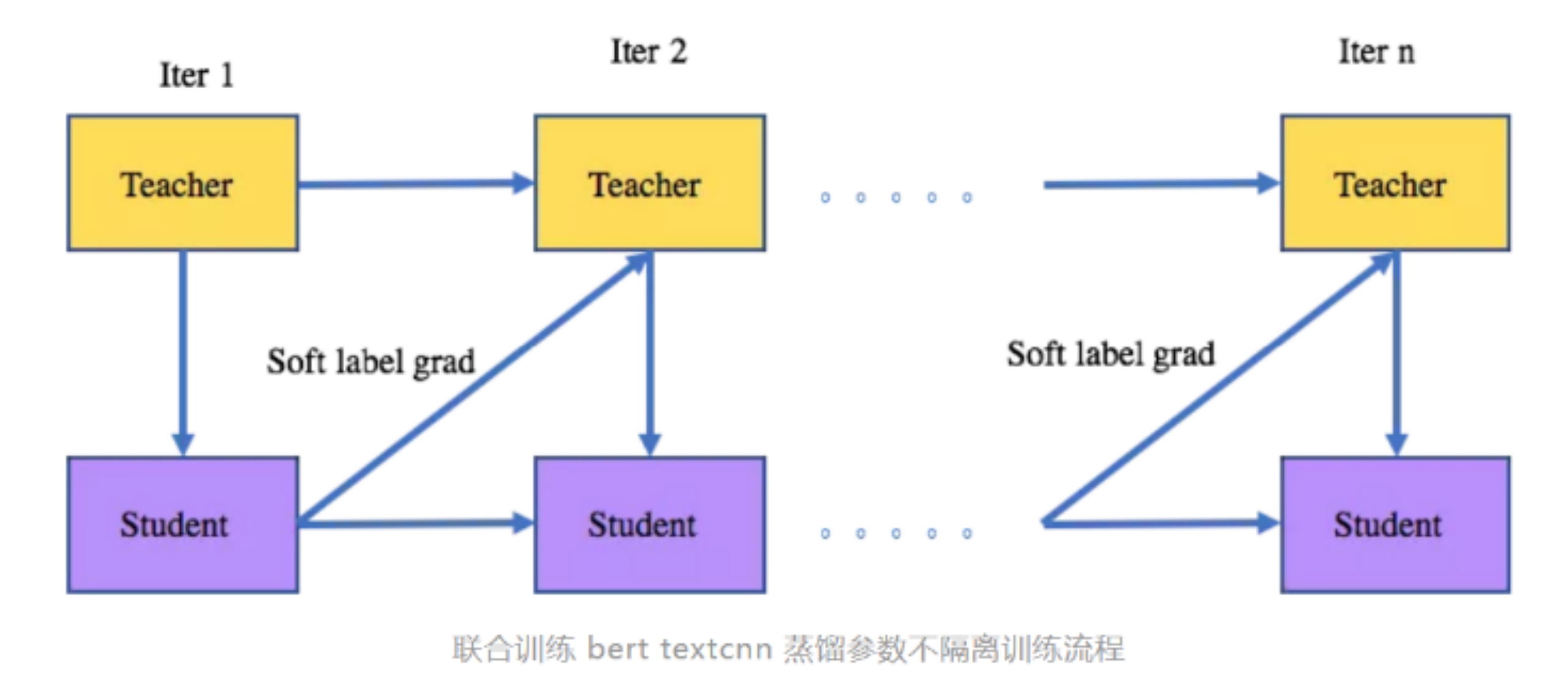
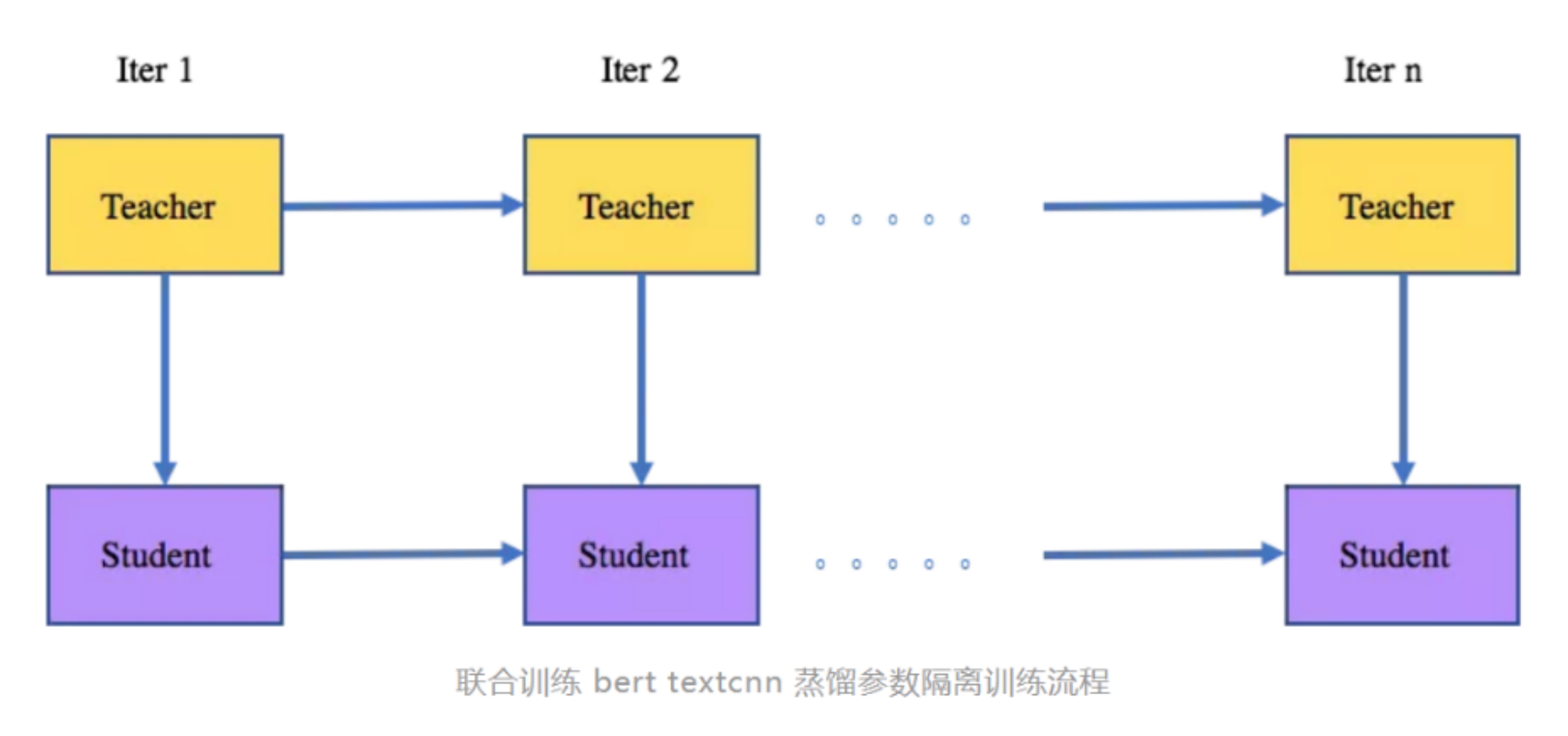
该怎么联合训练 bert textcnn 蒸馏?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
有2个方案。
(1)参数隔离:teacher model 训练一次,并把logit传给student。teacher 的参数更新至受到label的影响,student 参数更新受到teacher loigt的soft label loss 和label 的 hard label loss 的影响。
(2)参数不隔离: 与方案(1)类似,主要区别在于前一次迭代的student 的 soft label 的梯度会用于teacher参数的更新。