
如何来排查 RocketMQ 当前是否有性能瓶颈呢?
如何来排查 RocketMQ 当前是否有性能瓶颈呢?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
-
首先我们执行如下命令查看 RocketMQ 消息写入的耗时分布情况:
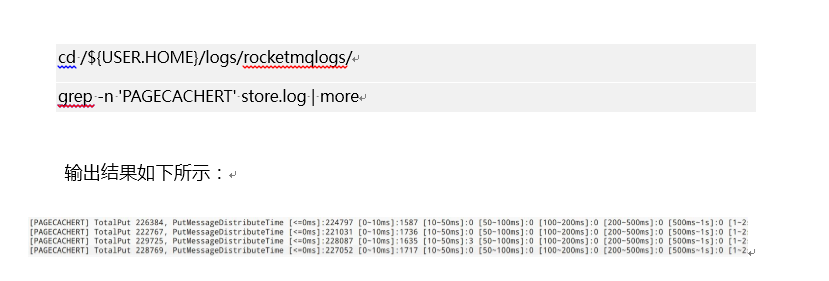
- RocketMQ 会每一分钟打印前一分钟内消息发送的耗时情况分布,我们从这里就能窥探 RocketMQ 消息写入是否存在明细的性能瓶颈,其区间如下:
[<=0ms] 小于 0ms,即微妙级别的。 2.[0~10ms] 小于 10ms 的个数。 3. [10~50ms] 大于 10ms 小。 4. 于 50ms 的个数。 5.其他区间显示,绝大多数会落在微妙级别完成,按照笔者的经验如果 100-200ms 及以上的区间超过 20 个后,说明 Broker 确实存在一定的瓶颈,如果只是少数几个,说明这个是内存或 pagecache 的抖动,问题不大。 6.通常情况下超时通常与 Broker 端的处理能力关系不大,还有另外一个佐证,在 RocketMQ broker 中还存在快速失败机制,即当 Broker 收到客户端的请求后会将消息先放入队列,然后顺序执行,如果一条消息队列中等待超过 200ms 就会启动快速失败,向客户端返回[TIMEOUT_CLEAN_QUEUE]broker busy,这个在本文的第 3 部分会详细介绍。 在 RocketMQ 客户端遇到网络超时,通常可以考虑一些应用本身的垃圾回收,是否由于 GC 的停顿时间导致的消息发送超时,这个我在测试环境进行压力测试时遇到过,但生产环境暂时没有遇到过,大家稍微留意一下。 7.在 RocketMQ 中通常遇到网络超时,通常与网络的抖动有关系,但由于我对网络不是特别擅长,故暂时无法找到直接证据,但能找到一些间接证据,例如在一个应用中同时连接了 kafka、RocketMQ 集群,发现在出现超时的同一时间发现连接到 RocketMQ 集群内所有 Broker,连接到 kafka 集群都出现了超时。 答复内容摘自《Apache RocketMQ 从入门到实战》,这本电子书收录开发者藏经阁 下载连接:https://developer.aliyun.com/topic/download?id=1139
2021-11-28 21:09:11赞同 展开评论
阿里云拥有国内全面的云原生产品技术以及大规模的云原生应用实践,通过全面容器化、核心技术互联网化、应用 Serverless 化三大范式,助力制造业企业高效上云,实现系统稳定、应用敏捷智能。拥抱云原生,让创新无处不在。
